
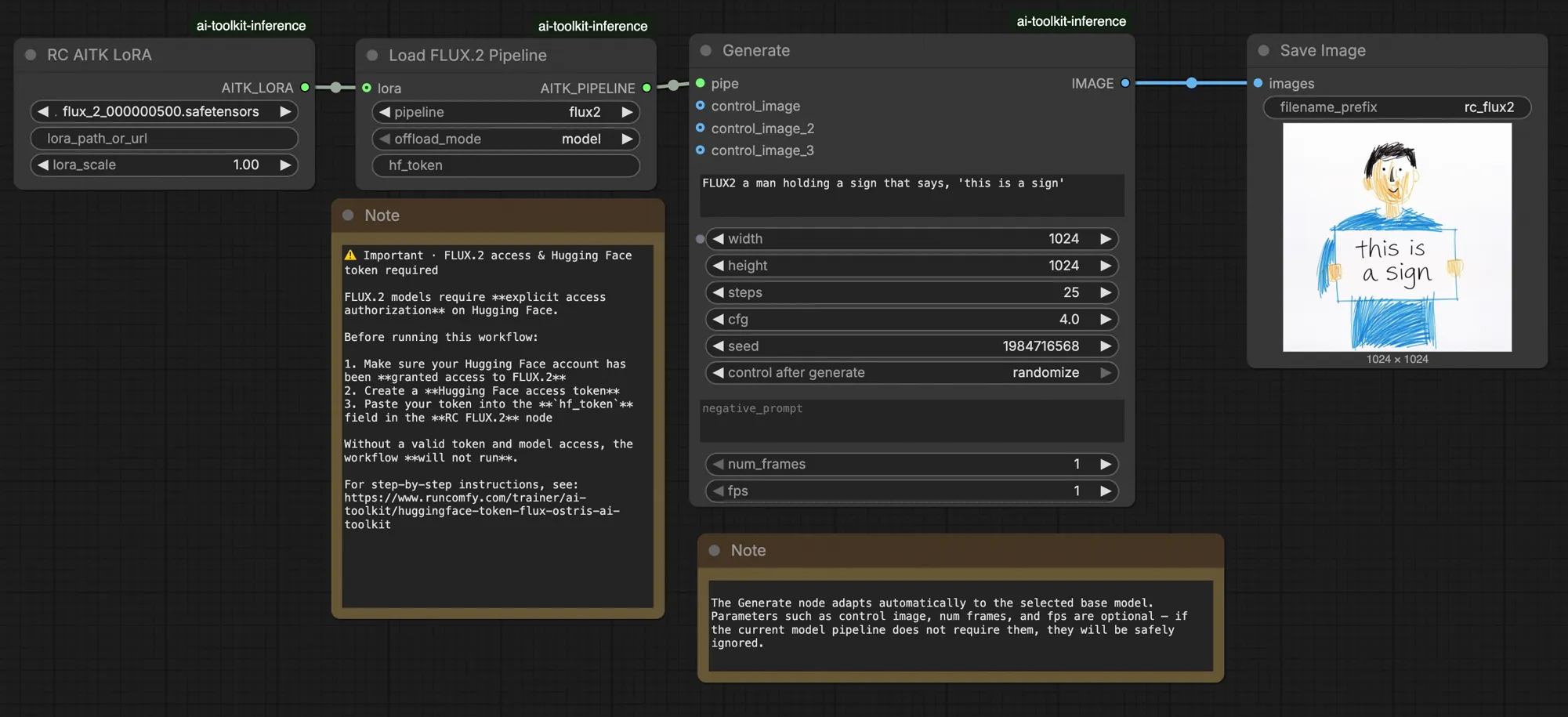
FLUX.2 LoRA ComfyUI 推論: FLUX.2 Dev パイプラインを使用したトレーニングに一致する AI Toolkit LoRA 出力#
このプロダクションレディの RunComfy ワークフローは、RC FLUX.2 Dev (Flux2Pipeline) (パイプラインレベルの整合性、一般的なサンプラーグラフではない) を通じて ComfyUI で FLUX.2 Dev LoRA 推論を実行します。RunComfy はこのカスタムノードを構築してオープンソース化しました。詳細は runcomfy-com repositories を参照してください。アダプターの適用は lora_path と lora_scale で制御します。
注: このワークフローを実行するには 3XL マシンが必要です。
なぜ FLUX.2 LoRA ComfyUI 推論が ComfyUI で異なるように見えるのか#
AI Toolkit トレーニングプレビューは、モデル固有の FLUX.2 パイプラインを通じてレンダリングされ、テキストエンコーディング、スケジューリング、および LoRA 注入が連携して機能するように設計されています。ComfyUI では、異なるグラフ (または異なる LoRA ローダーパス) を使用して FLUX.2 を再構築すると、それらの相互作用が変わる可能性があるため、同じプロンプト、ステップ、CFG、およびシードをコピーしても目に見えるドリフトが発生します。RunComfy RC パイプラインノードは、Flux2Pipeline で FLUX.2 をエンドツーエンドで実行し、そのパイプライン内で LoRA を適用することで、そのギャップを埋め、推論をプレビューの動作に合わせます。ソース: RunComfy オープンソースリポジトリ。
FLUX.2 LoRA ComfyUI 推論ワークフローの使用方法#
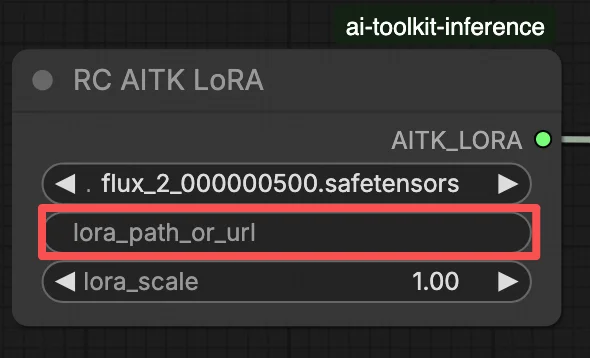
ステップ 1: LoRA パスを取得してワークフローにロードする (2 つのオプション)#
⚠️ 重要 · FLUX.2 アクセス & Hugging Face トークンが必要#
FLUX.2 Dev モデルには、Hugging Face での 明示的なアクセス承認 が必要です。
このワークフローを実行する前に:
- Hugging Face アカウントが FLUX.2 (Dev) へのアクセスを許可されていることを確認してください。
- Hugging Face アクセストークン を作成します。
- Load Pipeline ノードの
hf_tokenフィールドにトークンを貼り付けます。
有効なトークンと適切なモデルアクセスがない場合、ワークフローは 実行されません。詳細な手順については、Hugging Face トークン for FLUX.2 を参照してください。
オプション A — RunComfy トレーニング結果 → ローカル ComfyUI にダウンロード:
- Trainer → LoRA Assets にアクセスします。
- 使用したい LoRA を見つけます。
- 右側の ⋮ (三点リーダー) メニューをクリックし、Copy LoRA Link を選択します。
- ComfyUI ワークフローページで、コピーしたリンクを UI の 右上隅 にある Download 入力フィールドに貼り付けます。
- Download をクリックする前に、ターゲットフォルダが ComfyUI > models > loras に設定されていることを確認してください (このフォルダーをダウンロードターゲットとして選択する必要があります)。
- Download をクリックします。これにより、LoRA ファイルが正しい
models/lorasディレクトリに保存されます。 - ダウンロードが完了したら、ページを更新します。
- LoRA がワークフローの LoRA セレクトドロップダウン に表示されます — 選択します。

オプション B — 直接 LoRA URL (オプション A を上書き):
- 直接
.safetensorsダウンロード URL を LoRA ノードのpath / url入力フィールドに貼り付けます。 - ここに URL が提供されると、オプション A を上書きします — ワークフローは実行時に URL から直接 LoRA をロードします。
- ローカルダウンロードやファイル配置は不要です。
ヒント: URL が実際の .safetensors ファイルに解決されることを確認します (ランディングページやリダイレクトではありません)。
ステップ 2: 推論パラメーターをトレーニングサンプル設定に合わせる#
LoRA ノードで、lora_path (オプション A) でアダプターを選択するか、path / url に直接 .safetensors リンクを貼り付けます (オプション B がドロップダウンを上書き)。次に、lora_scale をトレーニングプレビュー時に使用した強度に設定し、そこから調整します。
残りのパラメータは Generate ノード (およびグラフによっては Load Pipeline ノード) にあります:
prompt: テキストプロンプト (トリガーワードを使用してトレーニングした場合は含めてください)width/height: 出力解像度; トレーニングプレビューサイズに合わせて最もクリーンな比較を行います (FLUX.2 には 16 の倍数が推奨されます)sample_steps: 推論ステップ数 (25 は一般的なデフォルトです)guidance_scale: CFG/ガイダンス値 (4.0 は一般的なデフォルトです)seed: 再現するための固定シード; 変更してバリエーションを探索しますseed_mode(存在する場合のみ):fixedまたはrandomizeを選択しますnegative_prompt(存在する場合のみ): このワークフローでは FLUX.2 はガイダンス蒸留されているため、ネガティブプロンプトは無視されますhf_token: Hugging Face アクセストークン; FLUX.2 Dev モデルのダウンロードに必要です (Load Pipeline ノードに貼り付けます)
トレーニング整合性のヒント: トレーニング中にサンプリング値 (seed, guidance_scale, sample_steps, トリガーワード、解像度) をカスタマイズした場合は、ここでそれらの正確な値を反映させます。RunComfy でトレーニングした場合は、Trainer → LoRA Assets > Config を開き、解決された YAML を表示してプレビュー/サンプル設定をワークフローノードにコピーします。

ステップ 3: FLUX.2 LoRA ComfyUI 推論を実行#
Queue/Run をクリックします — SaveImage ノードが結果を ComfyUI 出力フォルダに書き込みます。
クイックチェックリスト:
- ✓ LoRA は次のいずれかです:
ComfyUI/models/lorasにダウンロード済み (オプション A)、または直接.safetensorsURL を介してロード済み (オプション B) - ✓ ローカルダウンロード後にページが更新されている (オプション A のみ)
- ✓ 推論パラメータがトレーニング
sample設定に一致している (カスタマイズされている場合)
上記がすべて正しい場合、ここでの推論結果はトレーニングプレビューに近いものになるはずです。
FLUX.2 LoRA ComfyUI 推論のトラブルシューティング#
ほとんどの FLUX.2 “トレーニングプレビューと ComfyUI 推論” のギャップは、パイプラインレベルの違い (モデルの読み込み、スケジューリング、および LoRA のマージ方法) から生じます。単一の間違ったノブではありません。この RunComfy ワークフローは、RC FLUX.2 Dev (Flux2Pipeline) をエンドツーエンドで実行し、lora_path / lora_scale を介して LoRA をそのパイプライン内で適用することで、最も近い “トレーニングに一致する” ベースラインを復元します。
(1) Flux.2 with Lora error: "mul_cuda" not implemented for 'Float8_e4m3fn'#
なぜこれが起こるのか これは通常、FLUX.2 が Float8/FP8 重み (または混合精度量子化) でロードされ、LoRA が 一般的な ComfyUI LoRA パス を介して適用される場合に発生します。LoRA のマージがサポートされていない Float8 操作 (または混合 Float8 + BF16 プロモーション) を強制する可能性があり、mul_cuda Float8 ランタイムエラーを引き起こします。
修正方法 (推奨)
- RC FLUX.2 Dev (Flux2Pipeline) を介して推論を実行し、アダプターを
lora_path/lora_scaleのみを通じてロードし、AI Toolkit に合わせたパイプラインで LoRA のマージを行います。一般的な LoRA ローダーをスタックしないでください。 - 非 RC グラフでデバッグしている場合: Float8/FP8 拡散重みに LoRA を適用しないでください。LoRA を追加する前に FLUX.2 の BF16/FP16 互換 ロードパスを使用してください。
(2) LoRA 形状の不一致は、GPU 状態を破損させて OOM/システムの不安定性を引き起こすのではなく、迅速に失敗するべきです#
なぜこれが起こるのか これはほとんどの場合、ベースの不一致 です: LoRA は異なるモデルファミリー (例えば FLUX.1) のためにトレーニングされましたが、FLUX.2 Dev に適用されています。多くの場合、lora key not loaded 行が多数表示され、その後に形状の不一致が発生します。最悪の場合、セッションが不安定になり、OOM で終了する可能性があります。
修正方法 (推奨)
- LoRA が AI Toolkit を使用して
black-forest-labs/FLUX.2-dev用にトレーニングされていることを確認してください (FLUX.1 / FLUX.2 / Klein バリアントは互換性がありません)。 - グラフを “単一パス” に保つために: アダプターをワークフローの
lora_path入力を通じてのみロードし、Flux2Pipeline にマージを処理させます。追加の一般的な LoRA ローダーを並行して積み重ねないでください。 - 不一致が発生し、ComfyUI がその後に無関係な CUDA/OOM エラーを生成し始めた場合、ComfyUI プロセスを再起動して GPU + モデル状態を完全にリセットし、互換性のある LoRA で再試行してください。
(3) Flux.2 Dev - LoRAs を使用すると推論時間が 2 倍以上に増加します#
なぜこれが起こるのか LoRA は、LoRA パスが追加のパッチング/非量子化作業を強制したり、基本モデル単独よりも遅いコードパスで重みを適用したりする場合に、FLUX.2 Dev を大幅に遅くすることがあります。
修正方法 (推奨)
- このワークフローの RC FLUX.2 Dev (Flux2Pipeline) パスを使用し、アダプターを
lora_path/lora_scaleを通じて渡します。この設定では、LoRA は パイプラインロード中に一度マージ されるため、ステップごとのサンプリングコスト は基本モデルに近いままです。 - プレビューに一致する動作を追求している場合は、複数の LoRA ローダーを積み重ねたり、ローダーパスを混在させたりしないでください。1 つの
lora_path+ 1 つのlora_scaleにとどめ、ベースラインが一致するまで維持してください。
注 この FLUX.2 Dev ワークフローでは、FLUX.2 はガイダンス蒸留されているため、UI フィールドが存在しても negative_prompt はパイプラインによって無視される可能性があります — プロンプトの表現 + guidance_scale + lora_scale を最初に一致させてください。
今すぐ FLUX.2 LoRA ComfyUI 推論を実行#
ワークフローを開json いて、lora_path を設定し、Queue/Run をクリックして、AI Toolkit トレーニングプレビューに近い FLUX.2 Dev LoRA の結果を取得します。