
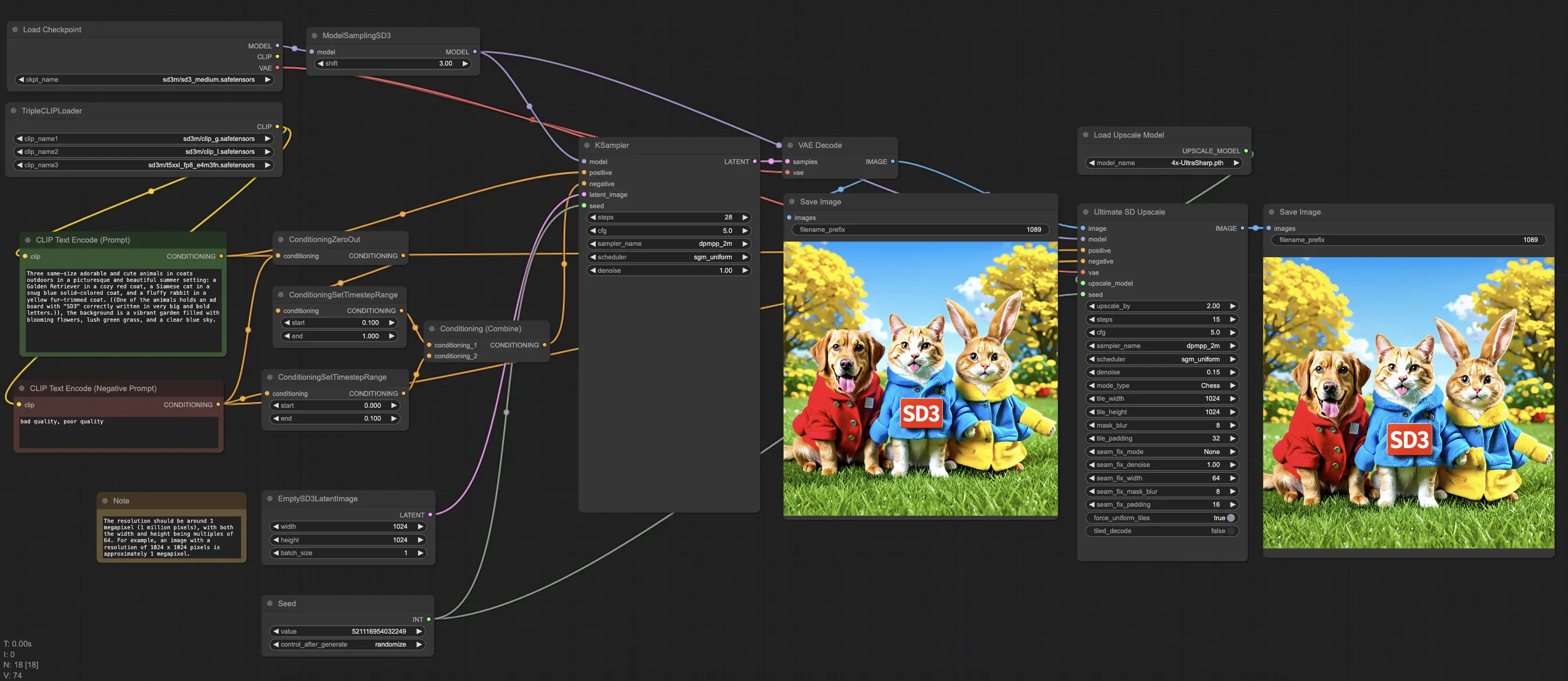



1. Boosting Your Creative Process with ComfyUI Stable Diffusion 3#
🌟🌟🌟The Stable Diffusion 3 Medium model and its related nodes are now preloaded into the RunComfy‘s ComfyUI Beta Version (Version 24.06.13.0)!!!🌟🌟🌟 You can either use the Stable Diffusion 3 Medium directly within this ComfyUI workflow or seamlessly integrate it into your existing ComfyUI workflows.
The ComfyUI Stable Diffusion 3 workflow comes with all the necessary Stable Diffusion 3 Medium models. Simply experiment with different prompts or parameters to experience it!
1.1. Stable Diffusion 3 Medium Models Preloaded in ComfyUI#
sd3_medium.safetensors: Includes the MMDiT and VAE weights but does not include any text encoders.sd3_medium_incl_clips_t5xxlfp16.safetensors: Contains all necessary weights, including the fp16 version of the T5XXL text encoder.sd3_medium_incl_clips_t5xxlfp8.safetensors: Contains all necessary weights, including the fp8 version of the T5XXL text encoder, offering a balance between quality and resource requirements.sd3_medium_incl_clips.safetensors: Includes all necessary weights except for the T5XXL text encoder. This version requires minimal resources, but the model's performance will be different without the T5XXL text encoder.- The
text_encodersfolder contains three text encoders and their original model card links for user convenience. All components within the this folder (and their equivalents embedded in other packages) are subject to their respective original licenses.
1.2 Overall Quality and Photorealism of Stable Diffusion 3 Medium#
Stable Diffusion 3 Medium sets a new standard for image quality in the AI art community. This model delivers images with exceptional detail, color accuracy, and realistic lighting. Here's what you can expect:
- Detail & Resolution: Enhanced ability to render intricate details, making it perfect for close-ups and complex compositions.
- Color & Lighting: Improved algorithms ensure that colors are vibrant and true to life, with dynamic lighting effects that add depth and realism to your images.
- Realism in Faces and Hands: Common pitfalls like distorted hands and faces are significantly reduced, thanks to innovations like the 16-channel Variational Autoencoder (VAE).
1.3 Prompt Understanding of Stable Diffusion 3 Medium#
One of the standout features of SD3 Medium is its sophisticated prompt comprehension. This model can interpret long and complex prompts involving spatial reasoning, compositional elements, actions, and styles. Here are some highlights:
- Text Encoders: Utilizes three text encoders to balance performance and efficiency. This allows for nuanced understanding and execution of detailed prompts.
- Compositional Awareness: Capable of maintaining spatial relationships and accurately depicting scenes as described, making it ideal for storytelling through visuals.
1.4 Typography of Stable Diffusion 3 Medium#
Typography has always been a challenge in text-to-image generation. SD3 Medium addresses this with remarkable success:
- Text Quality: Achieves unprecedented accuracy in spelling, kerning, letter formation, and spacing.
- Diffusion Transformer Architecture: This advanced architecture enables more precise rendering of text within images, reducing errors and improving visual coherence.
1.5 Resource Efficiency of Stable Diffusion 3 Medium#
Despite its advanced capabilities, SD3 Medium is designed to be resource-efficient:
- Low VRAM Footprint: Can run on standard consumer GPUs without performance degradation, making high-quality AI art accessible to a wider audience.
- Optimized for Efficiency: Balances computational demands with output quality, ensuring smooth operation even on less powerful hardware.
1.6 Fine-Tuning of Stable Diffusion 3 Medium#
Customization is a critical aspect for AI artists, and SD3 Medium excels in this area:
- Absorbing Nuanced Details: Capable of fine-tuning with small datasets, allowing artists to imprint their unique style or meet specific project requirements.
- Versatility: Whether you are working on specific themes, styles, or intricate details, SD3 Medium provides the flexibility needed for personalized artwork.
2. What is Stable Diffusion 3#
Stable Diffusion 3 is a cutting-edge AI model specifically designed for generating images from prompts. It represents the third iteration in the Stable Diffusion series and aims to deliver improved accuracy, better adherence to the nuances of prompts, and superior visual aesthetics compared to earlier versions and other models like DALL·E 3, Midjourney v6, and Ideogram v1.
3. Stable Diffusion 3 Models#
Stable Diffusion 3 offers three distinct models, each designed to meet different needs and computational capabilities:
3.1. Stable Diffusion 3 Medium#
🌟🌟🌟 Integrated directly into this workflow 🌟🌟🌟
- Parameters: 2 billion
- Key Features:
- High-quality, photorealistic images
- Advanced understanding of complex prompts
- Superior typography capabilities
- Resource-efficient, suitable for consumer GPUs
- Excellent for fine-tuning with small datasets
3.2. Stable Diffusion 3 Large#
Available via Stability AI Developer Platform API
- Parameters: 8 billion
- Key Features:
- Enhanced image quality and detail
- Greater capacity for handling complex prompts and styles
- Ideal for professional-grade projects requiring high resolution and fidelity
3.3. Stable Diffusion 3 Large Turbo#
Available via Stability AI Developer Platform API
- Parameters: 8 billion (with optimized inference time)
- Key Features:
- The same high performance as SD3 Large
- Faster inference, making it suitable for real-time applications and rapid prototyping
4. Technical Architecture of Stable Diffusion 3#
At the core of Stable Diffusion 3 lies the Multimodal Diffusion Transformer (MMDiT) architecture. This innovative framework enhances how the model processes and integrates textual and visual information. Unlike its predecessors that utilized a single set of neural network weights for both image and text processing, Stable Diffusion 3 employs separate weight sets for each modality. This separation allows for more specialized handling of text and image data, leading to improved text understanding and spelling in the generated images.
4.1. Components of MMDiT Architecture#
- Text Embedders: Stable Diffusion 3 uses a combination of three text embedding models, including two CLIP models and T5, to convert text into a format that the AI can understand and process.
- Image Encoder: An enhanced autoencoding model is used for converting images into a form suitable for the AI to manipulate and generate new visual content.
- Dual Transformer Approach: The architecture features two distinct transformers for text and images, which operate independently but are interconnected for attention operations. This setup allows both modalities to influence each other directly, enhancing the coherence between the text input and the image output.
5. What’s New and Improved in Stable Diffusion 3?#
- Adherence to Prompts: SD3 excels in closely following the specifics of user prompts, particularly those that involve complex scenes or multiple subjects. This precision in understanding and rendering detailed prompts allows it to outperform other leading models such as DALL·E 3, Midjourney v6, and Ideogram v1, making it highly reliable for projects requiring strict adherence to given instructions.
- Text in Images: With its advanced Multimodal Diffusion Transformer (MMDiT) architecture, SD3 significantly enhances the clarity and readability of text within images. By employing separate sets of weights for processing image and language data, the model achieves superior text comprehension and spelling accuracy. This is a substantial improvement over earlier versions of Stable Diffusion, addressing one of the common challenges in text-to-image AI applications.
- Visual Quality: SD3 not only matches but in many cases surpasses the visual quality of images generated by its competitors. The images produced are not only aesthetically pleasing but also maintain high fidelity to the prompts, thanks to the model's refined ability to interpret and visualize textual descriptions. This makes SD3 a top choice for users seeking exceptional visual aesthetics in their generated imagery.

For detailed insights into the model, please visit Stable Diffusion 3's research paper, Github








