
AIビデオにおける制御可能なアニメーション: WanVideo + TTMモーション制御ワークフロー for ComfyUI#
mickmumpitzによるこのワークフローは、トレーニング不要のモーションガイドアプローチを使用して、ComfyUIにAIビデオの制御可能なアニメーションをもたらします。WanVideoの画像からビデオへの拡散とTime-to-Move (TTM) 潜在ガイダンス、領域認識マスクを組み合わせることで、アイデンティティ、テクスチャ、シーンの連続性を維持しながら被写体の動きを指示できます。
ビデオプレートまたは2つのキーフレームから開始し、モーションを集中させたい場所に領域マスクを追加して、微調整なしで軌道を駆動します。結果は、指示されたショット、オブジェクトのモーションシーケンス、カスタムクリエイティブ編集に適した正確で繰り返し可能な制御可能なアニメーションです。
Comfyuiの制御可能なアニメーションにおける主要モデル#
- Wan2.2 I2V A14B (HIGH/LOW)。プロンプトと視覚的参照からモーションと時間的一貫性を合成するコアの画像からビデオへの拡散モデル。さまざまなモーション強度に対する忠実度(HIGH)と機敏性(LOW)のバランスをとる2つのバリアント。モデルファイルは、Hugging FaceのコミュニティWanVideoコレクションにホストされています。例: KijaiのWanVideoディストリビューション。 リンク: Kijai/WanVideo_comfy_fp8_scaled, Kijai/WanVideo_comfy
- Lightx2v I2V LoRA。Wan2.2と組み合わせたときに構造とモーションの一貫性を強化する軽量アダプター。強いモーションキューの下で被写体の形状を保持するのに役立ちます。 リンク: Kijai/WanVideo_comfy – Lightx2v LoRA
- Wan2.1 VAE。フレームを潜在にエンコードし、サンプラーの出力を詳細を犠牲にせずに画像にデコードするためのビデオオートエンコーダー。 リンク: Kijai/WanVideo_comfy – Wan2_1_VAE_bf16.safetensors
- UMT5-XXLテキストエンコーダー。モーションキューと並行してプロンプト駆動制御のための豊富なテキスト埋め込みを提供します。 リンク: google/umt5-xxl, Kijai/WanVideo_comfy – encoder weights
- セグメントAnythingモデルによるビデオマスク。SAM3とSAM2はフレーム全体に領域マスクを作成・伝播し、重要な領域で制御可能なアニメーションをシャープにする領域依存ガイダンスを可能にします。 リンク: facebook/sam3, facebook/sam2
- Qwen-Image-Edit 2509 (オプション)。アニメーション前のクイックスタート/エンドフレームのクリーンアップやオブジェクトの削除のためのイメージ編集基盤とライトニングLoRA。 リンク: QuantStack/Qwen-Image-Edit-2509-GGUF, lightx2v/Qwen-Image-Lightning, Comfy-Org/Qwen-Image_ComfyUI
- Time-to-Move (TTM) ガイダンス。ワークフローはTTM潜在を統合して、トレーニング不要の方法で制御可能なアニメーションに軌道制御を注入します。 リンク: time-to-move/TTM
Comfyuiにおける制御可能なアニメーションワークフローの使用方法#
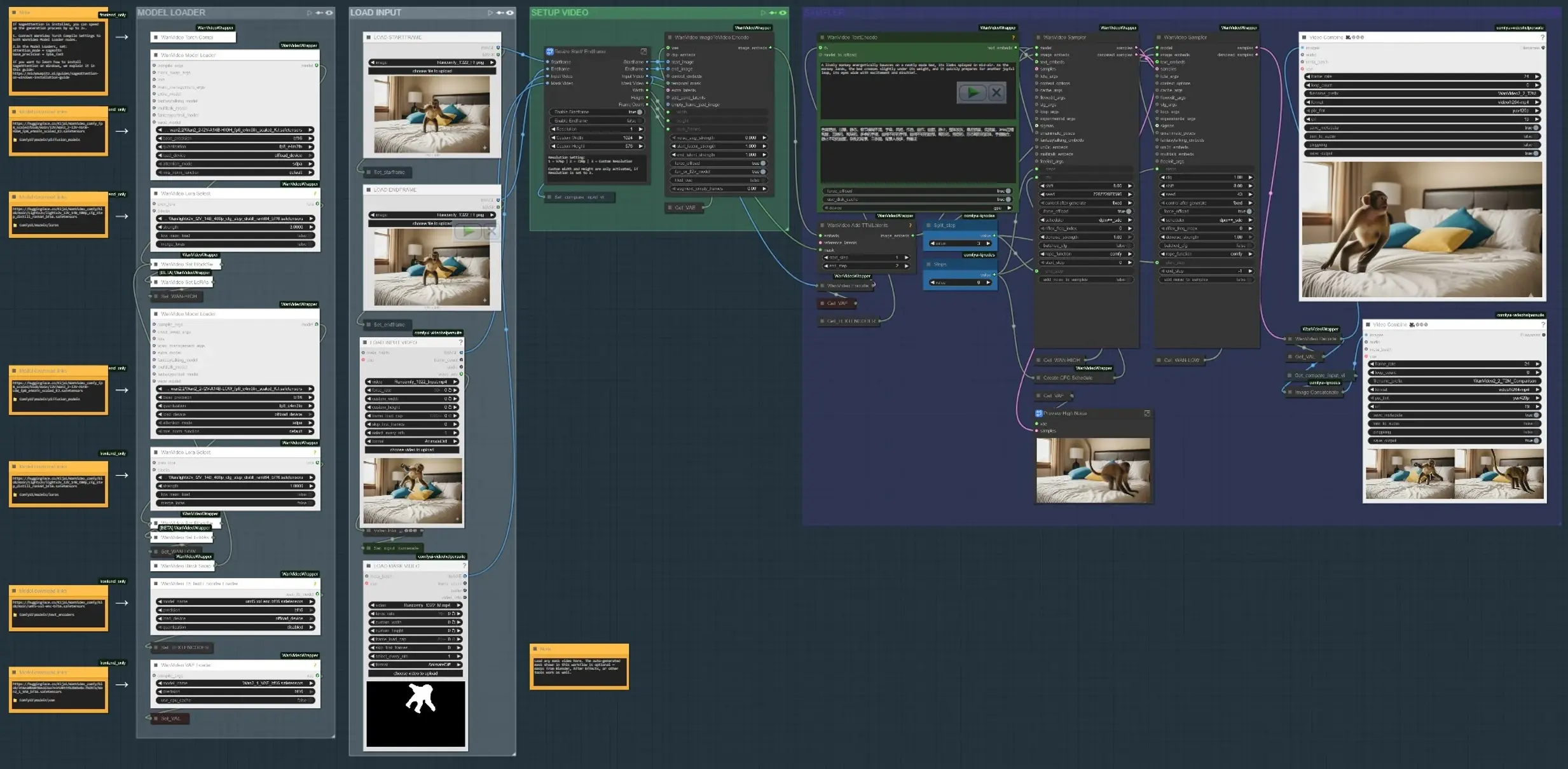
ワークフローは次の4つの主なフェーズで実行されます: 入力のロード、モーションが発生する場所の定義、テキストとモーションキューのエンコード、そして結果の合成とプレビュー。以下の各グループはグラフ内のラベル付きセクションに対応しています。
- 入力のロード “LOAD INPUT VIDEO”グループを使用して、プレートまたは参照クリップを取り込み、2つの状態間でモーションを構築する場合は開始および終了キーフレームをロードします。“Resize Start/Endframe”サブグラフは寸法を正規化し、開始フレームおよび終了フレームのゲーティングをオプションで有効にします。サイドバイサイドコンパレータは、入力と結果を示す出力を構築し、クイックレビュー用に提供します (
VHS_VideoCombine(#613))。 - モデルローダー “MODEL LOADER”グループはWan2.2 I2V (HIGH/LOW)をセットアップし、Lightx2v LoRAを適用します。ブロックスワップパスは、サンプリング前にバリアントをブレンドして、良好な忠実度-モーショントレードオフを提供します。Wan VAEは一度ロードされ、エンコード/デコード間で共有されます。テキストエンコーディングは、制御可能なアニメーションに対する強力なプロンプト条件付けのためにUMT5-XXLを使用します。
- SAM3/SAM2マスクサブジェクト “SAM3 MASK SUBJECT”または“SAM2 MASK SUBJECT”で、参照フレームをクリックし、正および負のポイントを追加し、クリップ全体にマスクを伝播します。これにより、選択した被写体または領域にモーション編集を制限する時間的一貫性のあるマスクが得られ、領域依存ガイダンスが可能になります。また、独自のマスクビデオをバイパスしてロードすることもできます。Blender/After Effectsからのマスクも、アーティストが描いた制御が必要な場合に問題なく動作します。
- 開始フレーム/終了フレームの準備 (オプション) “STARTFRAME – QWEN REMOVE”および“ENDFRAME – QWEN REMOVE”グループは、Qwen-Image-Editを使用して特定のフレームでオプションのクリーンアップパスを提供します。リギング、スティック、またはプレートのアーティファクトを削除してモーションキューを汚染しないように使用します。インペインティングは、編集をフルフレームに縫い戻し、クリーンなベースを提供します。
- テキスト+モーションエンコード プロンプトはUMT5-XXLで
WanVideoTextEncode(#605)にエンコードされます。開始フレーム/終了フレームの画像はWanVideoImageToVideoEncode(#89)でビデオ潜在に変換されます。TTMモーション潜在とオプションの時間マスクはWanVideoAddTTMLatents(#104)を介してマージされ、サンプラーが意味(テキスト)と軌道のキューを受け取ります。これは制御可能なアニメーションにとって重要です。 - サンプラーとプレビュー Wanサンプラー (
WanVideoSampler(#27) およびWanVideoSampler(#90)) は、デュアルクロックセットアップを使用して潜在をデノイズします。1つのパスはグローバルダイナミクスを管理し、もう1つはローカルの外観を保持します。ステップと設定可能なCFGスケジュールは、モーションの強度と忠実度を形成します。結果はフレームにデコードされ、ビデオとして保存されます。比較出力は、制御可能なアニメーションがブリーフに一致するかどうかを判断するのに役立ちます。
Comfyuiにおける制御可能なアニメーションワークフローの主要ノード#
WanVideoImageToVideoEncode(#89) 開始フレーム/終了フレームの画像をモーション合成の種となるビデオ潜在にエンコードします。基本解像度やフレーム数を変更するときのみ調整します。入力と一致させてストレッチを避けます。マスクビデオを使用する場合は、その寸法がエンコードされた潜在サイズと一致していることを確認してください。WanVideoAddTTMLatents(#104) TTMモーション潜在と時間マスクを制御ストリームに融合します。マスク入力をトグルしてモーションを被写体に制限します。空白のままにすると、モーションがグローバルに適用されます。背景に影響を与えずに軌道特定の制御可能なアニメーションが必要な場合に使用します。SAM3VideoSegmentation(#687) いくつかの正および負のポイントを収集し、トラックフレームを選択し、クリップ全体に伝播します。サンプリング前にマスクドリフトを検証するために視覚化出力を使用します。プライバシーに敏感なワークフローやオフラインワークフローの場合、モデルゲーティングを必要としない SAM2 グループに切り替えます。WanVideoSampler(#27) モーションとアイデンティティのバランスを取るデノイザーです。“Steps”とCFGスケジュールリストを組み合わせて、モーションの強さを押し上げたり緩和したりします。強すぎると外観を圧倒し、弱すぎるとモーションが過小になります。マスクがアクティブな場合、サンプラーは制御可能なアニメーションの安定性を向上させるために領域内の更新に集中します。
オプションの追加#
- 高速な反復のために、LOW Wan2.2モデルで開始し、TTMでモーションを調整し、最終パスでHIGHに切り替えてテクスチャを回復します。
- 複雑なシルエットの場合、アーティストが描いたマスクビデオを使用します。ローダーは外部マスクを受け入れ、それらを一致するようにリサイズします。
- “開始フレーム/終了フレーム”スイッチを使用して、視覚的に最初または最後のフレームをロックできます。長い編集でシームレスな引き渡しに便利です。
- 環境で利用可能な場合、最適化されたアテンション(例: SageAttention)を有効にすると、サンプリングが大幅に高速化されます。
- 出力フレームレートをソースに合わせて、制御可能なアニメーションでのタイミングの違いを避けます。
このワークフローは、テキストプロンプト、TTM潜在、堅牢なセグメンテーションを組み合わせて、トレーニング不要で領域認識のモーション制御を提供します。いくつかのターゲット入力で、モデルを維持し、シーンを一貫性のある状態に保ちながら、微妙でプロダクション対応の制御可能なアニメーションを指示できます。
謝辞#
このワークフローは以下の作品とリソースを実装および構築しています。我々は、Mickmumpitz に感謝し、彼は制御可能なアニメーションのためのチュートリアル/投稿の作成者であり、time-to-moveチームのTTMに貢献とメンテナンスを感謝します。権威ある詳細については、以下のリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- Patreon/制御可能なアニメーション
- ドキュメント / リリースノート: Mickmumpitz Patreon post
- time-to-move/TTM
- GitHub: time-to-move/TTM
注意: 参照されたモデル、データセット、コードの使用は、それぞれの著者およびメンテナによって提供されるライセンスおよび条件に従うものとします。