
Segment Anything V2、別名SAM2は、Meta AIによって開発された画期的なAIモデルで、画像および動画のオブジェクトセグメンテーションを革命的に変えます。
Segment Anything V2 (SAM2)とは?#
Segment Anything V2は、画像および動画全体のオブジェクトをシームレスにセグメント化する最先端のAIモデルです。これは、画像と動画のセグメンテーションタスクの両方を優れた精度と効率で処理できる最初の統合モデルです。Segment Anything V2 (SAM2)は、その前身であるSegment Anything Model (SAM)の成功を基に、プロンプト可能な機能を動画領域に拡張しています。
Segment Anything V2 (SAM2)を使用すると、クリック、バウンディングボックス、またはマスクなどのさまざまな入力方法を使用して画像または動画フレーム内のオブジェクトを選択できます。その後、モデルは選択されたオブジェクトをインテリジェントにセグメント化し、視覚コンテンツ内の特定の要素を正確に抽出および操作できるようにします。
Segment Anything V2 (SAM2)のハイライト#
- 最先端のパフォーマンス:SAM2は、画像および動画のオブジェクトセグメンテーション分野で既存のモデルを上回ります。画像セグメンテーションタスクでその前身であるSAMの性能を超える精度と精密度の新しい基準を設定します。
- 画像と動画のための統合モデル:SAM2は、画像および動画全体のオブジェクトをセグメント化するための統合ソリューションを提供する最初のモデルです。この統合により、AIアーティストはさまざまなセグメンテーションタスクに単一のモデルを使用できるため、ワークフローが簡素化されます。
- 強化された動画セグメンテーション機能:SAM2は、特にオブジェクトの部分を追跡する動画オブジェクトセグメンテーションで優れた性能を発揮します。既存の動画セグメンテーションモデルを上回り、フレーム全体でオブジェクトをセグメント化する精度と一貫性を向上させます。
- Segment Aのハイライト。インタラクション時間の短縮:既存のインタラクティブな動画セグメンテーション方法と比較して、SAM2はユーザーからのインタラクション時間を短縮します。この効率性により、AIアーティストは創造的なビジョンに集中し、手動のセグメンテーションタスクに費やす時間を減らすことができます。
- シンプルなデザインと高速な推論:高度な機能を持ちながら、SAM2はシンプルなアーキテクチャデザインを維持し、高速な推論速度を提供します。これにより、AIアーティストはパフォーマンスや効率を損なうことなく、SAM2をワークフローにシームレスに統合できます。
Segment Anything V2 (SAM2)の動作方法#
SAM2は、ターゲットオブジェクト情報をキャプチャするセッションごとのメモリモジュールを導入することにより、SAMのプロンプト可能な機能を動画に拡張します。これにより、一時的な消失があってもフレーム全体でオブジェクトを追跡できます。ストリーミングアーキテクチャは、動画フレームを1つずつ処理し、メモリモジュールが空のときにSAMのように動作します。これにより、リアルタイムの動画処理とSAMの機能の自然な一般化が可能になります。SAM2はまた、ユーザープロンプトに基づいたインタラクティブなマスク予測修正をサポートします。モデルは、ストリーミングメモリを備えたトランスフォーマーアーキテクチャを使用し、ユーザーインタラクションによってモデルとデータの両方を改善するモデルインザループデータエンジンを使用して収集された最大の動画セグメンテーションデータセットであるSA-Vデータセットでトレーニングされています。
ComfyUIでSegment Anything V2 (SAM2)を使用する方法#
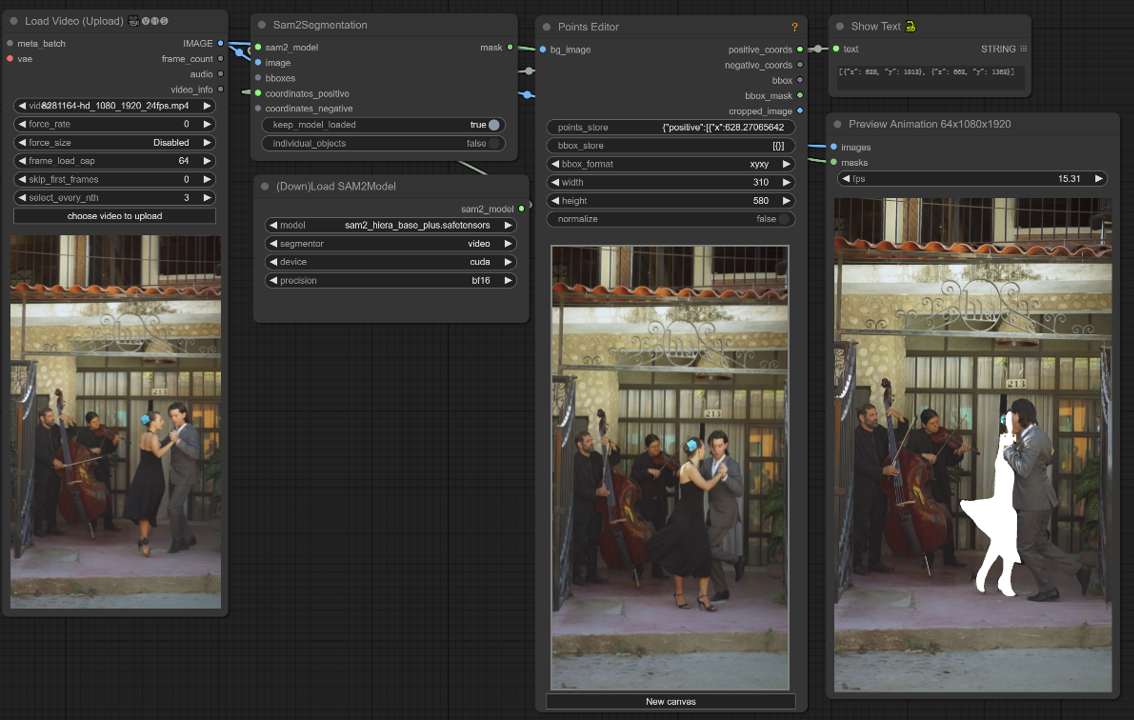
このComfyUIワークフローは、クリック/ポイントを使用して動画フレーム内のオブジェクトを選択することをサポートします。
1. 動画の読み込み(アップロード)#
動画の読み込み: 処理したい動画を選択してアップロードします。

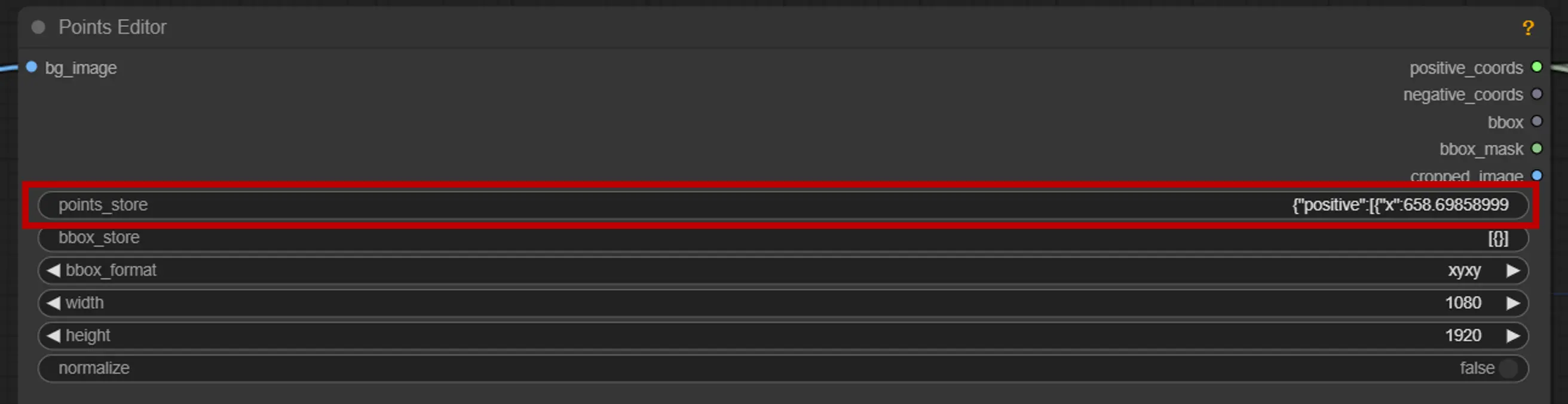
2. ポイントエディタ#
キーポイント: キャンバスに3つのキーポイント—positive0、positive1、およびnegative0を配置します:
positive0とpositive1は、セグメント化したい領域またはオブジェクトをマークします。
negative0は不要な領域や気を散らすものを除外するのに役立ちます。

ポイントストア: セグメンテーションプロセスを洗練するために、必要に応じてポイントを追加または削除できます。
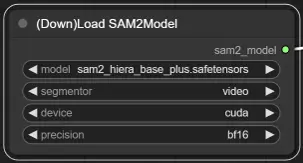
3. SAM2のモデル選択#
モデルオプション: 利用可能なSAM2モデルから選択します:tiny、small、large、またはbase_plus。大きなモデルはより良い結果を提供しますが、ロード時間が長くなります。
詳細については、Kijai ComfyUI-segment-anything-2をご覧ください。
