
InfiniteTalk: ComfyUIで1枚の画像からリップシンクされたポートレートビデオ#
このComfyUI InfiniteTalk ワークフローは、1枚の参照画像とオーディオクリップから自然でスピーチシンクロされたポートレートビデオを作成します。WanVideo 2.1 の画像から動画生成と MultiTalk トーキングヘッドモデルを組み合わせ、表現豊かなリップモーションと安定したアイデンティティを実現します。短いソーシャルクリップ、ビデオダブ、アバター更新が必要な場合、InfiniteTalk は静止写真を数分で流れるトーキングビデオに変えます。
InfiniteTalk は、MeiGen-AI の優れた MultiTalk 研究に基づいています。背景と帰属については、オープンソースプロジェクトを参照してください: MeiGen-AI/MultiTalk。
Comfyui InfiniteTalk ワークフローの主要モデル#
- MultiTalk (GGUF, InfiniteTalk variant): 音声から音素認識の顔の動きを駆動し、口と顎の動きが自然にスピーチを追跡します。参考: Kijai/WanVideo_comfy_GGUF › InfiniteTalk と上流のアイデア: MeiGen-AI/MultiTalk。
- WanVideo 2.1 I2V 14B (GGUF): アイデンティティ、照明、ポーズを保持しながらフレームをアニメーション化する主要な画像から動画生成器。推奨ウェイト: city96/Wan2.1-I2V-14B-480P-gguf。
- Wan 2.1 VAE (bf16): 潜在フレームをRGBにデコードし、色のシフトを最小限に抑えます。上記の WanVideo パックに含まれます。
- UMT5-XXL テキストエンコーダー: ポジティブおよびネガティブプロンプトを解釈して、スタイル、シーン、およびモーションコンテキストを調整します。モデルファミリー: google/umt5-xxl。
- CLIP Vision: 参照画像から視覚的な埋め込みを抽出し、アイデンティティと全体的な外観をロックします。
- Wav2Vec2 (Tencent GameMate): 生音声を頑強な音声特徴に変換し、MultiTalk 埋め込みを改善し、同期と韻律を向上させます: TencentGameMate/chinese-wav2vec2-base。
ヒント: この InfiniteTalk グラフは GGUF 用に構築されています。InfiniteTalk MultiTalk ウェイトと WanVideo バックボーンを GGUF に保持して互換性の問題を回避します。オプションの fp8/fp16 ビルドも利用可能です: Kijai/WanVideo_comfy_fp8_scaled および Kijai/WanVideo_comfy。
Comfyui InfiniteTalk ワークフローの使用方法#
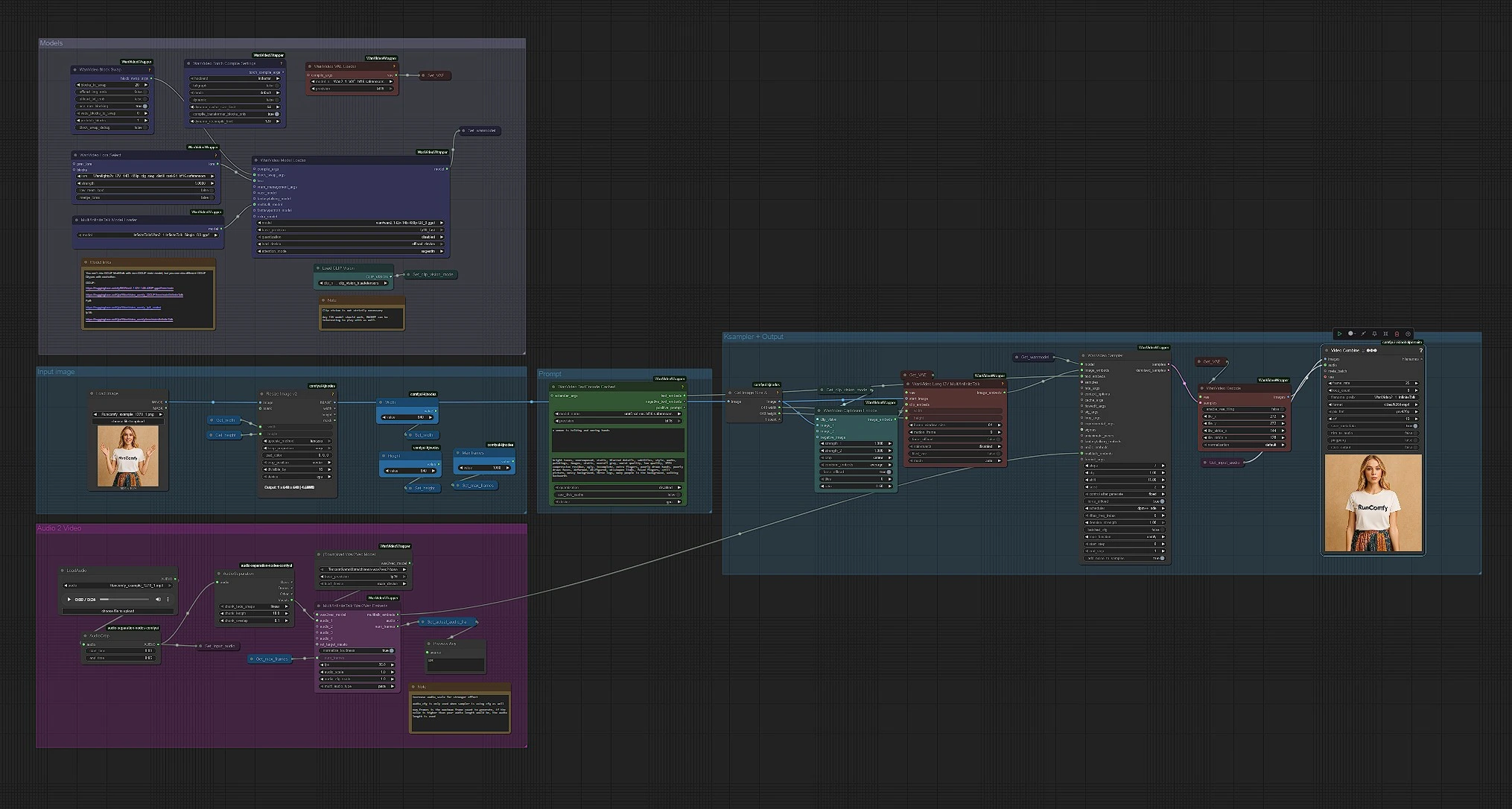
ワークフローは左から右に実行されます。あなたは3つのものを提供します: クリーンなポートレート画像、スピーチオーディオファイル、スタイルを指示する短いプロンプト。グラフはテキスト、画像、および音声の手がかりを抽出し、それらをモーション認識ビデオ潜在変数に融合し、同期されたMP4をレンダリングします。
モデル#
このグループは、WanVideo、VAE、MultiTalk、CLIP Vision、およびテキストエンコーダーをロードします。WanVideoModelLoader (#122) は Wan 2.1 I2V 14B GGUF バックボーンを選択し、WanVideoVAELoader (#129) は対応する VAE を準備します。MultiTalkModelLoader (#120) はスピーチ駆動のモーションを駆動する InfiniteTalk バリアントをロードします。WanVideoLoraSelect (#13) に Wan LoRA をオプションで接続して外観と動きをバイアスすることができます。これらは高速の初回実行のために手を付けずに置いてください。480p パイプライン用に事前に配線されています。
プロンプト#
WanVideoTextEncodeCached (#241) はあなたのポジティブおよびネガティブプロンプトを UMT5 でエンコードします。ポジティブプロンプトを使用して、対象とシーンのトーンを説明し、アイデンティティは参照写真から取得します。ネガティブプロンプトは避けたいアーティファクト(ぼやけ、余分な手足、灰色の背景)に集中してください。InfiniteTalk のプロンプトは主に照明と動きのエネルギーを形成し、顔は一貫性を保ちます。
入力画像#
CLIPVisionLoader (#238) と WanVideoClipVisionEncode (#237) はあなたのポートレートを埋め込みます。シャープで正面向きの頭と肩の写真を使用し、均一な光を当てます。必要に応じて、顔が動く余裕を持つように軽くトリミングしてください。過度のトリミングは動きを不安定にする可能性があります。画像の埋め込みは、ビデオがアニメーション化される際にアイデンティティと衣服の詳細を保持するために前方に渡されます。
オーディオからMultiTalkへ#
あなたのスピーチを LoadAudio (#125) にロードし、AudioCrop (#159) でクイックプレビュー用にトリミングします。DownloadAndLoadWav2VecModel (#137) が Wav2Vec2 を取得し、MultiTalkWav2VecEmbeds (#194) がクリップを音素認識のモーション特徴に変換します。4~8秒の短いカットは反復に最適です。外観が気に入ったら、より長いテイクを実行できます。クリーンでドライな声のトラックが最適です。強いバックグラウンドミュージックはリップタイミングを混乱させる可能性があります。
画像から動画、サンプリングと出力#
WanVideoImageToVideoMultiTalk (#192) は、あなたの画像、CLIP Vision 埋め込み、MultiTalk をフレーム単位で画像埋め込みに融合し、Width と Height 定数でサイズを決定します。WanVideoSampler (#128) は Get_wanmodel から WanVideo モデルとあなたのテキスト埋め込みを使用して潜在フレームを生成します。WanVideoDecode (#130) が潜在変数を RGB フレームに変換します。最後に、VHS_VideoCombine (#131) がフレームと音声を25 fpsでバランスの取れた品質設定で MP4 にミックスし、最終的な InfiniteTalk クリップを生成します。
Comfyui InfiniteTalk ワークフローの主要ノード#
WanVideoImageToVideoMultiTalk (#192)#
このノードは InfiniteTalk の中心です: 開始画像、CLIP Vision 特徴、MultiTalk ガイダンスを目標解像度で統合してトーキングヘッドアニメーションを条件付けます。width と height を調整してアスペクトを設定します。832×480 は速度と安定性に優れたデフォルトです。サンプリング前にアイデンティティと動きを整合させる主要な場所として使用します。
MultiTalkWav2VecEmbeds (#194)#
Wav2Vec2 特徴を MultiTalk モーション埋め込みに変換します。リップモーションが控えめすぎる場合は、この段階でその影響(音声スケーリング)を高めます。過度に誇張されている場合は、影響を減らします。信頼性のある音素タイミングのために音声が主なものとなるようにしてください。
WanVideoSampler (#128)#
画像、テキスト、MultiTalk 埋め込みを使用してビデオ潜在変数を生成します。初回実行時はデフォルトのスケジューラとステップを維持します。ちらつきが見られる場合は、合計ステップを増やすか、CFG を有効にすることが役立ちます。動きが硬すぎると感じた場合は、CFG またはサンプラー強度を減らします。
WanVideoTextEncodeCached (#241)#
UMT5-XXL でポジティブおよびネガティブプロンプトをエンコードします。「スタジオライト、柔らかな肌、自然な色」などの簡潔で具体的な言葉を使用し、ネガティブプロンプトを中心に集中させます。プロンプトはフレーミングとスタイルを洗練し、口の同期は MultiTalk から来ます。
オプションの追加機能#
- 互換性の問題を避けるために、MultiTalk と WanVideo を同じデプロイメントファミリー(すべて GGUF またはすべて非 GGUF)に保ちます。
- 5~8秒のオーディオクロップとデフォルトの480pサイズで反復してください。必要に応じて後でアップスケールします。
- アイデンティティが不安定な場合は、よりクリーンなソース写真や穏やかな LoRA を試してください。強い LoRA は類似性を上書きする可能性があります。
- 静かな部屋でスピーチを録音し、レベルを正規化します。InfiniteTalk は明確でドライな声で音素を最もよく追跡します。
謝辞#
InfiniteTalk ワークフローは、ComfyUI の柔軟なノードシステムと MultiTalk AI モデルを組み合わせることで、AI パワードビデオ生成において大きな飛躍を遂げました。この実装は、InfiniteTalk の自然なスピーチ同期を支える MultiTalk プロジェクトをリリースした MeiGen-AI のオリジナル研究とリリースのおかげで可能になりました。また、ソースリファレンスを提供してくれた InfiniteTalk プロジェクトチーム、およびシームレスなワークフロー統合を可能にした ComfyUI 開発者コミュニティにも感謝します。
さらに、ComfyUI 内で高品質なトーキングおよびシンギングポートレートの作成を容易にした Wan Video Sampler ノード に InfiniteTalk を実装した Kijai にも感謝します。InfiniteTalk のオリジナルリソースリンクはここにあります: InfiniteTalk Example Workflow。
これらの貢献により、クリエイターはシンプルなポートレートを生き生きとした連続するトーキングアバターに変換し、AI 駆動のストーリーテリング、ダビング、パフォーマンスコンテンツの新しい機会を開拓することが可能になりました。
