
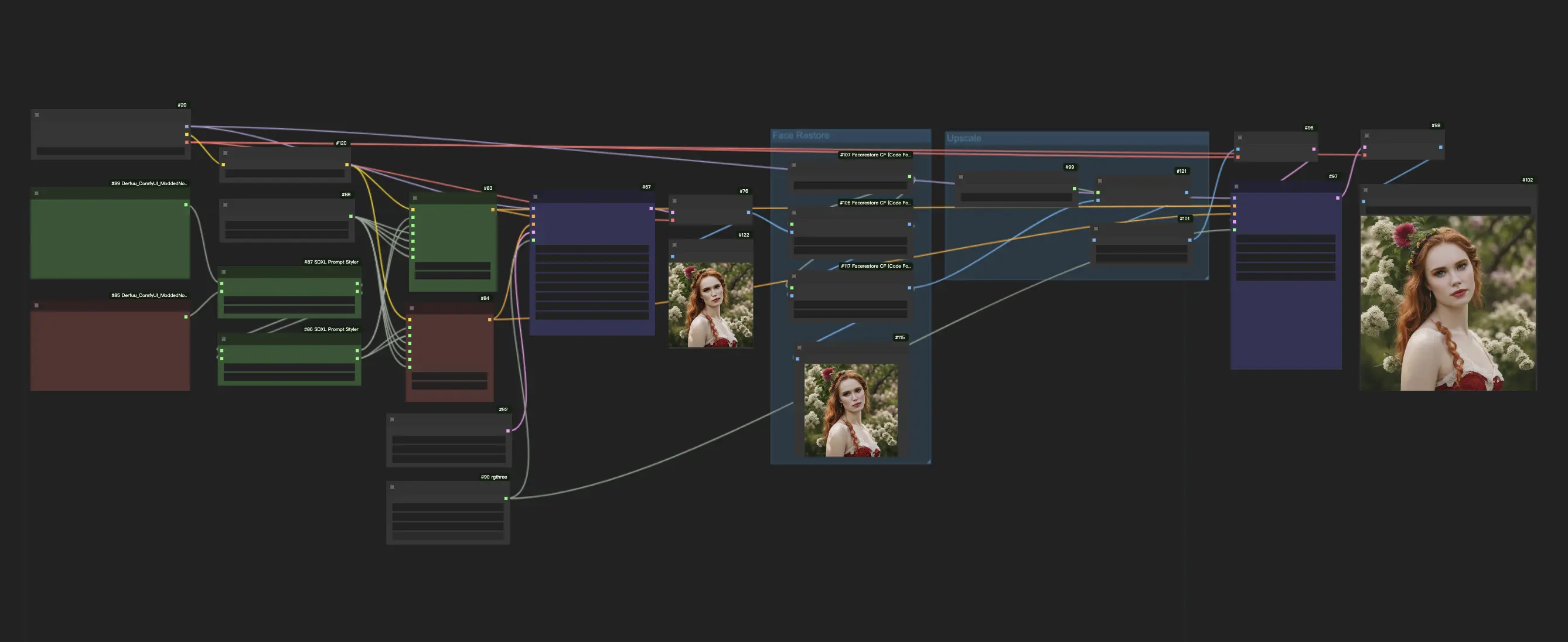

1. Flujo de Trabajo de ComfyUI SDXL Turbo#
SDXL Turbo sintetiza imágenes en un solo paso y genera resultados de texto a imagen en tiempo real. La calidad de SDXL Turbo es relativamente buena, aunque puede no ser siempre estable. Para mejorar los resultados, se incorpora un modelo de restauración de rostros y un modelo de escala para aquellos que buscan resultados de mayor calidad.
2. Resumen de SDXL Turbo#
SDXL Turbo es un modelo generativo de texto a imagen que convierte de manera eficiente indicaciones de texto en imágenes fotorrealistas en una sola evaluación de red. Aprovechando una técnica llamada Adversarial Diffusion Distillation (ADD), desarrollada por Stability AI, reduce drásticamente el proceso de síntesis de imágenes a 1 a 4 pasos, mucho menos que los 50 pasos tradicionales requeridos por modelos anteriores. Este modelo, un avance de SDXL 1.0, utiliza ADD para fusionar la destilación de puntaje con una pérdida adversaria, optimizando el uso de modelos existentes de difusión de imágenes para una mayor calidad con menos pasos de muestreo. La introducción de esta técnica de destilación no solo preserva la calidad de la imagen, sino que también reduce significativamente el esfuerzo computacional necesario para la generación de imágenes.
3. Limitaciones de SDXL Turbo#
A pesar de sus capacidades avanzadas, SDXL Turbo tiene ciertas limitaciones. Genera imágenes a una resolución fija de 512x512 píxeles y puede tener dificultades para renderizar texto legible, representar con precisión rostros y personas, y lograr un fotorrealismo perfecto. Estas limitaciones subrayan el uso previsto del modelo para investigación y exploración en lugar de representaciones fácticas o precisas de entidades del mundo real.









