
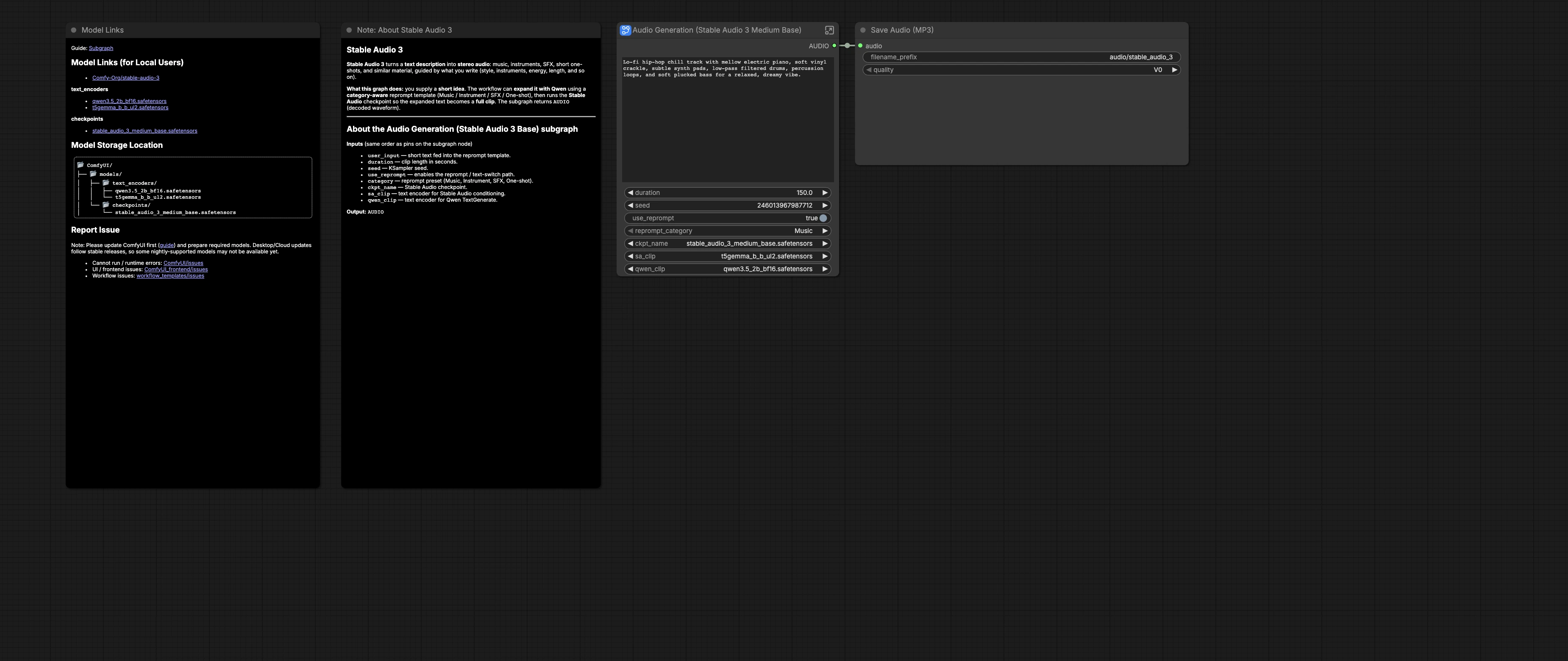
Flujo de trabajo de Stable Audio 3.0 Medium Base para texto a audio de larga duración en ComfyUI#
Este flujo de trabajo de Stable Audio 3.0 Medium Base convierte ideas de texto cortas en audio estéreo más largo y musical. Está construido alrededor del punto de control stable_audio_3_medium_base con los codificadores de texto T5-Gemma y Qwen3.5 para entregar bocetos de música impulsados por indicaciones, camas ambientales, efectos de sonido (SFX) y disparos únicos con configuraciones reproducibles en ComfyUI.
El gráfico incluye un sistema opcional de re-indicación consciente de categoría que puede expandir tu idea breve en una indicación lista para producción densa antes de la síntesis. Tú eliges la categoría, duración y semilla, luego la tubería condiciona Stable Audio 3 y renderiza el audio que se guarda como un MP3. El flujo de trabajo sigue la plantilla oficial y los recursos proporcionados por Comfy-Org para Stable Audio 3.0 Medium Base. Consulta la plantilla de referencia y los modelos en Comfy-Org/workflow_templates y Comfy-Org/stable-audio-3.
Modelos clave en el flujo de trabajo de Comfyui Stable Audio 3.0 Medium Base#
- Punto de control Stable Audio 3 Medium Base. El modelo generativo principal que sintetiza audio estéreo a partir de condicionamiento de texto y latentes. Fuente: Comfy-Org/stable-audio-3.
- Codificador de texto T5-Gemma Base UL2. Produce las incrustaciones de texto usadas para condicionar Stable Audio 3 para indicaciones positivas y negativas. El archivo del codificador de texto empaquetado está incluido bajo la carpeta text_encoders del repositorio Stable Audio 3: Comfy-Org/stable-audio-3.
- Modelo de texto Qwen3.5 2B. Impulsa la re-indicación opcional consciente de categoría que expande una idea corta en una descripción detallada de música, instrumento, SFX o disparo único. Fuente: Comfy-Org/Qwen3.5.
Cómo usar el flujo de trabajo de Comfyui Stable Audio 3.0 Medium Base#
A un nivel alto, proporcionas una idea corta y una duración objetivo. El gráfico puede mantener tus palabras tal cual o usar Qwen3.5 para reescribirlas a través de una plantilla de categoría. El resultado se codifica para el condicionamiento, es muestreado por Stable Audio 3, decodificado a audio y guardado.
Entradas del usuario: indicación y duración#
El subgráfico Generación de Audio (Stable Audio 3 Medium Base) (#52) expone user_input, duration, seed, use_reprompt, y category. Escribe una idea breve en lenguaje simple, como un estilo, lista de instrumentos, estado de ánimo, y un BPM opcional. Elige una longitud de clip en segundos y establece una seed para reproducibilidad o variación. Activa use_reprompt cuando quieras la reescritura impulsada por la plantilla, luego selecciona una category como Música, Instrumento, SFX, o Disparo único.
Cargadores: punto de control y codificadores de texto#
CheckpointLoaderSimple (#25) carga stable_audio_3_medium_base.safetensors, proporcionando el MODEL y VAE usados más tarde para muestreo y decodificación. CLIPLoader (#26) carga el codificador T5-Gemma usado para el condicionamiento. Un segundo CLIPLoader (#29) carga el modelo Qwen3.5 que impulsa la etapa de re-indicación.
Re-indicación: plantillas JSON y categoría#
Un selector de categoría CustomCombo (#43) alimenta un gran JSON de indicaciones del sistema en JsonExtractString (#49). La plantilla seleccionada se inserta en una meta-indicación por Text Replace (PROMPT TEMPLATE) (#38). Tu user_input se inyecta por Text Replace (USER INPUT) (#39), y la longitud objetivo se inserta usando Text Replace (AUDIO LENGTH) (#40), manteniendo la reescritura alineada con tu duración elegida.
Re-indicación: Qwen TextGenerate#
TextGenerate (#28) utiliza Qwen3.5 para convertir la plantilla ensamblada más tu idea en una indicación concisa y detallada que sigue reglas específicas de categoría. Esta etapa es especialmente útil para estructuras musicales más largas y para SFX donde el lenguaje técnico concreto es importante. La reescritura de la indicación es previsualizable, para que puedas iterar rápidamente en la elección de categoría y redacción.
Cambio entre texto original y reescrito#
ComfySwitchNode (#34) selecciona ya sea tu texto original o la reescritura generada por Qwen basado en use_reprompt. Déjalo encendido para obtener indicaciones estructuradas y conscientes de la duración, o apágalo cuando quieras control literal sobre la redacción. Este simple interruptor hace que las pruebas A/B sean directas.
Codificación CLIP: condicionamiento#
CLIPTextEncode (#6) convierte la indicación seleccionada en el condicionamiento positivo que impulsa el modelo. Un segundo CLIPTextEncode (#7) proporciona un condicionamiento negativo neutral por defecto. Este emparejamiento suministra a Stable Audio 3 una guía clara mientras evita artefactos no deseados.
Generación de audio: Stable Audio#
EmptyLatentAudio (#11) crea un audio latente cuya longitud coincide con duration. KSampler (#3) realiza el proceso de desruido usando el MODEL de Stable Audio 3 Medium Base del punto de control. VAEDecodeAudio (#12) convierte el latente final en una forma de onda estéreo audible. Debido a que la misma duration también informa la re-indicación, la longitud del clip renderizado y el texto reescrito permanecen sincronizados.
Guardar y exportar#
Fuera del subgráfico, SaveAudioMP3 (#19) escribe el resultado en un archivo MP3 con un prefijo útil para la organización. Usa esto cuando generes lotes con diferentes valores de seed o categorías, luego audiciona y guarda tus favoritos.
Nodos clave en el flujo de trabajo de Comfyui Stable Audio 3.0 Medium Base#
ComfySwitchNode(#34). Alterna entre eluser_inputoriginal y el texto generado por Qwen. Enciéndelo para reescrituras estructuradas y conscientes de la longitud o apágalo para control directo.TextGenerate(#28). Ejecuta Qwen3.5 con una indicación de sistema específica de categoría para expandir ideas. Para personalizar el estilo de reescritura, edita las plantillas de categoría enJsonExtractString(#49) y las indicaciones de unión en los nodosText Replaceadyacentes.EmptyLatentAudio(#11). Establece la longitud del clip. Mantén esto alineado con el tokenAUDIO_LENGTHinsertado para que el tiempo de síntesis coincida con la intención textual.KSampler(#3). Gobierna la trayectoria de desruido para Stable Audio 3. Ajustaseedpara variaciones mientras mantienes otras configuraciones estables para comparar tomas de manera justa.SaveAudioMP3(#19). Controla el prefijo del nombre del archivo de salida y el formato para la construcción rápida de bibliotecas a partir de múltiples ejecuciones.
Extras opcionales#
- Comienza con una idea de una o dos oraciones que nombre el género o fuente, instrumentos clave o texturas, y estado de ánimo. La re-indicación puede llenar detalles como BPM y arreglo.
- Elige la categoría que coincida con tu objetivo: Música para pistas completas, Instrumento para bucles o stems, SFX para entornos y acciones, Disparo único para golpes aislados.
- Mantén la duración realista para tu contenido objetivo. Los clips muy largos son más pesados de computar y pueden beneficiarse de una
seedestable mientras iteras. - Cuando los resultados se sientan abarrotados, desactiva la re-indicación y prueba una frase más simple, luego vuelve a activarla una vez que te guste la dirección.
- Para tomas alternativas rápidas, mantén todo constante y cambia solo la
seed.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Comfy-Org por el artículo de soporte de Stable Audio 3 Day-0 en ComfyUI, a Comfy-Org por la plantilla oficial de flujo de trabajo de Stable Audio 3.0 Medium Base, a Comfy-Org por los archivos del modelo Stable Audio 3, y a Comfy-Org por los archivos del modelo del codificador Qwen3.5 por sus contribuciones y mantenimiento. Para obtener detalles autorizados, por favor consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- Comfy-Org/ComfyUI Stable Audio 3 Day-0 Support Article
- Documentos / Notas de lanzamiento: Stable Audio 3 Day-0 Support
- Comfy-Org/Official Stable Audio 3.0 Medium Base Workflow Template
- GitHub: Comfy-Org/workflow_templates
- Comfy-Org/Stable Audio 3 Model Files
- Hugging Face: Comfy-Org/stable-audio-3
- Comfy-Org/Qwen3.5 Encoder Model Files
- Hugging Face: Comfy-Org/Qwen3.5
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.