
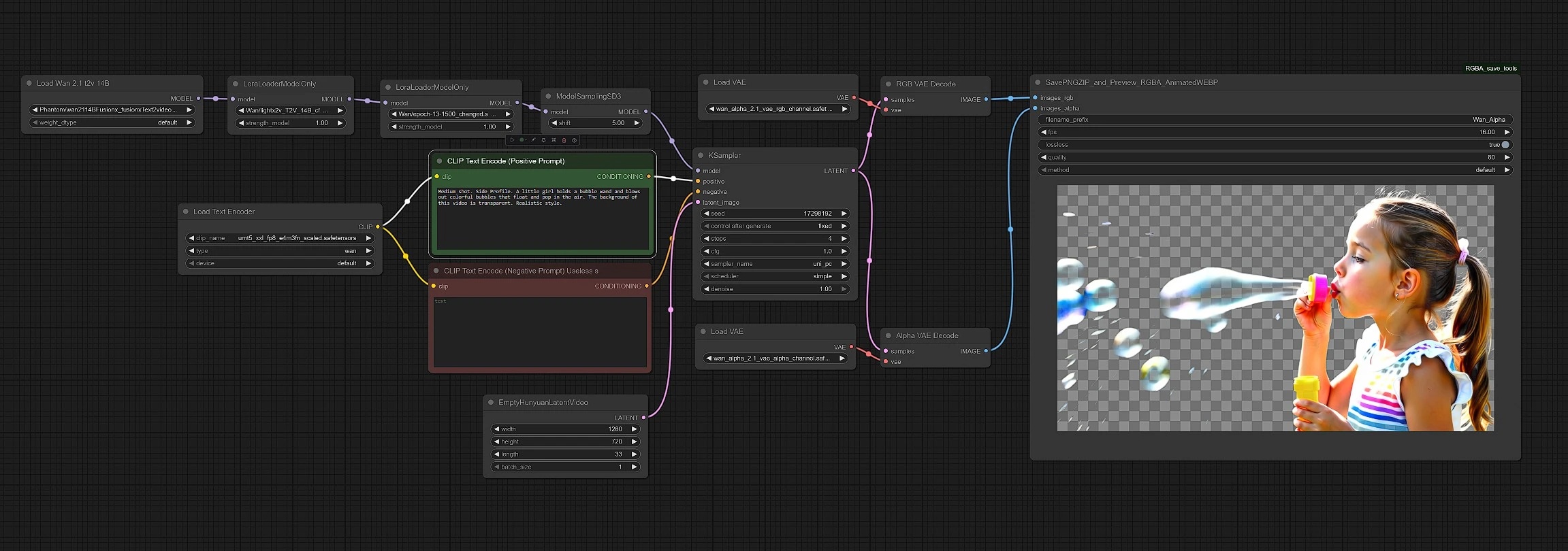
Wan Alpha: transparent text-to-video for pro compositing#
Wan Alpha is a purpose-built ComfyUI workflow that generates videos with a native alpha channel using the Wan 2.1 family. It jointly produces RGB and alpha so characters, props, and effects drop straight into timelines without keying or rotoscoping. For VFX, motion graphics, and interactive apps, Wan Alpha delivers clean edges, semi‑transparent effects, and frame-accurate masks ready for production.
Built around Wan2.1‑T2V‑14B and an alpha-aware VAE pair, Wan Alpha balances fidelity and speed. Optional LightX2V LoRA acceleration shortens sampling while preserving detail, and the workflow exports RGBA frame sequences plus an animated WebP preview for quick review.
Key models in Comfyui Wan Alpha workflow#
- Wan2.1‑T2V‑14B. Foundation text-to-video model that drives scene structure, motion, and rendering quality. Official weights and code are maintained in the Wan-Video organization on GitHub. Wan-Video/Wan2.1
- UMT5‑XXL text encoder. Multilingual encoder used to tokenize and embed prompts for Wan models, enabling rich prompt phrasing in multiple languages. google/umt5-xxl and UMT5 docs
- Wan‑Alpha VAE pair. A VAE design that learns RGB and alpha jointly so decoded alpha aligns pixel-for-pixel with RGB, supporting fine edges and semi-transparency. See the Wan‑Alpha technical report for background. Wan‑Alpha (arXiv)
- LightX2V LoRA. Optional acceleration LoRA that distills long samplers to a few steps for faster text-to-video while maintaining perceptual quality. ModelTC/LightX2V
How to use Comfyui Wan Alpha workflow#
This ComfyUI graph follows a straightforward path from prompt to RGBA frames: load models, encode text, allocate a video latent, sample, decode RGB and alpha in lockstep, then save.
Model and LoRA loading
- Start at
Load Wan 2.1 t2v 14B(#37) to bring in the base model. If you use acceleration or style refinements, apply them withLoraLoaderModelOnly(#59) andLoraLoaderModelOnly(#65) in sequence. The model then passes throughModelSamplingSD3(#48), which configures a sampler compatible with the loaded checkpoint. This stack defines the motion prior and rendering style that Wan Alpha will refine in later steps.
Prompt encoding
Load Text Encoder(#38) loads the UMT5‑XXL text encoder. Enter your description inCLIP Text Encode (Positive Prompt)(#6); keep your subject, action, camera framing, and the phrase “transparent background” concise. UseCLIP Text Encode (Negative Prompt) Useless s(#7) to steer away from halos or background clutter if needed. These encodings condition both RGB and alpha generation so edges and transparency cues follow your intent.
Video canvas setup
- Use
EmptyHunyuanLatentVideo(#40) to define the latent video canvas. Setwidth,height,frames, andfpsto fit your shot; higher resolutions or longer clips require more memory. This node allocates a temporally consistent latent volume that Wan Alpha will fill with motion and appearance. Consider matching duration and frame rate to your edit to avoid resampling later.
Generation
- The
KSampler(#3) performs diffusion on the video latent using your model stack and prompt conditioning. Adjustseedfor variations, and select asamplerandschedulerthat balance speed and detail. When the LightX2V LoRA is active, you can use fewer steps for faster renders while maintaining stability. The output is a single latent stream shared by the next decoding stage to guarantee perfect RGBA alignment.
Decoding RGB and alpha
RGB VAE Decode(#8) pairs withVAELoader(#39) to reconstruct RGB frames. In parallel,Alpha VAE Decode(#52) pairs withVAELoader(#51) to reconstruct the alpha channel. Both decoders read the same latent so the matte aligns exactly with the color pixels, a core idea in Wan‑Alpha’s design for consistent transparency. This dual-path decode is what makes Wan Alpha ready for direct compositing.
Saving and previewing
SavePNGZIP_and_Preview_RGBA_AnimatedWEBP(#73) writes two deliverables: a zip archive of RGBA PNG frames and a compact animated WebP preview. The frame sequence is production friendly for NLEs and compositors, while the preview accelerates reviews. Name your output set, choose a preview length and quality, and run the node to package your result.
Key nodes in Comfyui Wan Alpha workflow#
EmptyHunyuanLatentVideo (#40)
- Role: defines spatial and temporal resolution of the generated clip. Tune
width,height,frames, andfpsto match delivery. Larger canvases and longer durations raise VRAM needs; consider shorter drafts for look development, then scale up for finals.
KSampler (#3)
- Role: the main denoiser for Wan Alpha. Adjust
seedfor explorations,stepsto trade speed for detail,samplerandschedulerfor stability, andcfgto balance prompt adherence with natural motion. With LightX2V LoRA active, you can reducestepssignificantly while preserving quality thanks to step-distillation. See LightX2V for context on fast sampling. ModelTC/LightX2V
LoraLoaderModelOnly (#59)
- Role: loads the LightX2V LoRA that accelerates Wan2.1 sampling. Use the
strengthcontrol to blend its effect if you see oversharpening or tempo artifacts. Keep this LoRA closest to the base model in the chain so downstream LoRAs inherit its speed benefits.
LoraLoaderModelOnly (#65)
- Role: loads an additional LoRA for style or domain refinement. Moderate
strengthto avoid overpowering motion coherence; combine with your prompt rather than replacing it. If artifacts appear, lower this LoRA before changing the sampler.
VAELoader (#39) RGB
- Role: provides the RGB VAE used by
RGB VAE Decode(#8). Keep this paired with the Wan‑Alpha alpha VAE to ensure both decoders interpret latents coherently. Swapping to unrelated VAEs can misalign edges or soften transparency. Background on the joint RGB–alpha design is in the Wan‑Alpha report. Wan‑Alpha (arXiv)
VAELoader (#51) Alpha
- Role: provides the alpha VAE used by
Alpha VAE Decode(#52). It reconstructs the matte from the same latent space as RGB so transparency matches motion and detail. If you customize VAEs, test that RGB and alpha still align on subpixel edges like hair.
SavePNGZIP_and_Preview_RGBA_AnimatedWEBP (#73)
- Role: exports assets. Set a clear
output_namefor versioning, choose preview quality and frame rate that reflect the generated clip, and keep the PNG export as your master for lossless compositing. Avoid resizing between decode and save to preserve edge fidelity.
Optional extras#
- Strong prompts for Wan Alpha explicitly describe subject, action, camera, lighting, and “transparent background.” Add subtle materials like “wispy hair” or “glass” to exercise alpha detail.
- For quick iteration, use shorter durations or lower frame rates, then upscale settings once look and motion are locked.
- If you see halos, add negatives like “background, outline, green screen, white fringe” and keep lighting consistent in the prompt.
- When combining multiple LoRAs, place acceleration LoRAs earlier and stylistic LoRAs later, and keep strengths modest to retain motion realism.
- Import the RGBA PNG sequence directly into your compositor; use the animated WebP only for previews, not as a master.
Resources used in Wan Alpha
- Wan2.1 model family and code: Wan-Video/Wan2.1
- UMT5 text encoder: google/umt5-xxl and UMT5 docs
- Wan‑Alpha method overview: Wan‑Alpha (arXiv)
- LightX2V acceleration: ModelTC/LightX2V
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge WeChatCV for Wan-Alpha for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- WeChatCV/Wan-Alpha
- GitHub: WeChatCV/Wan-Alpha
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.