
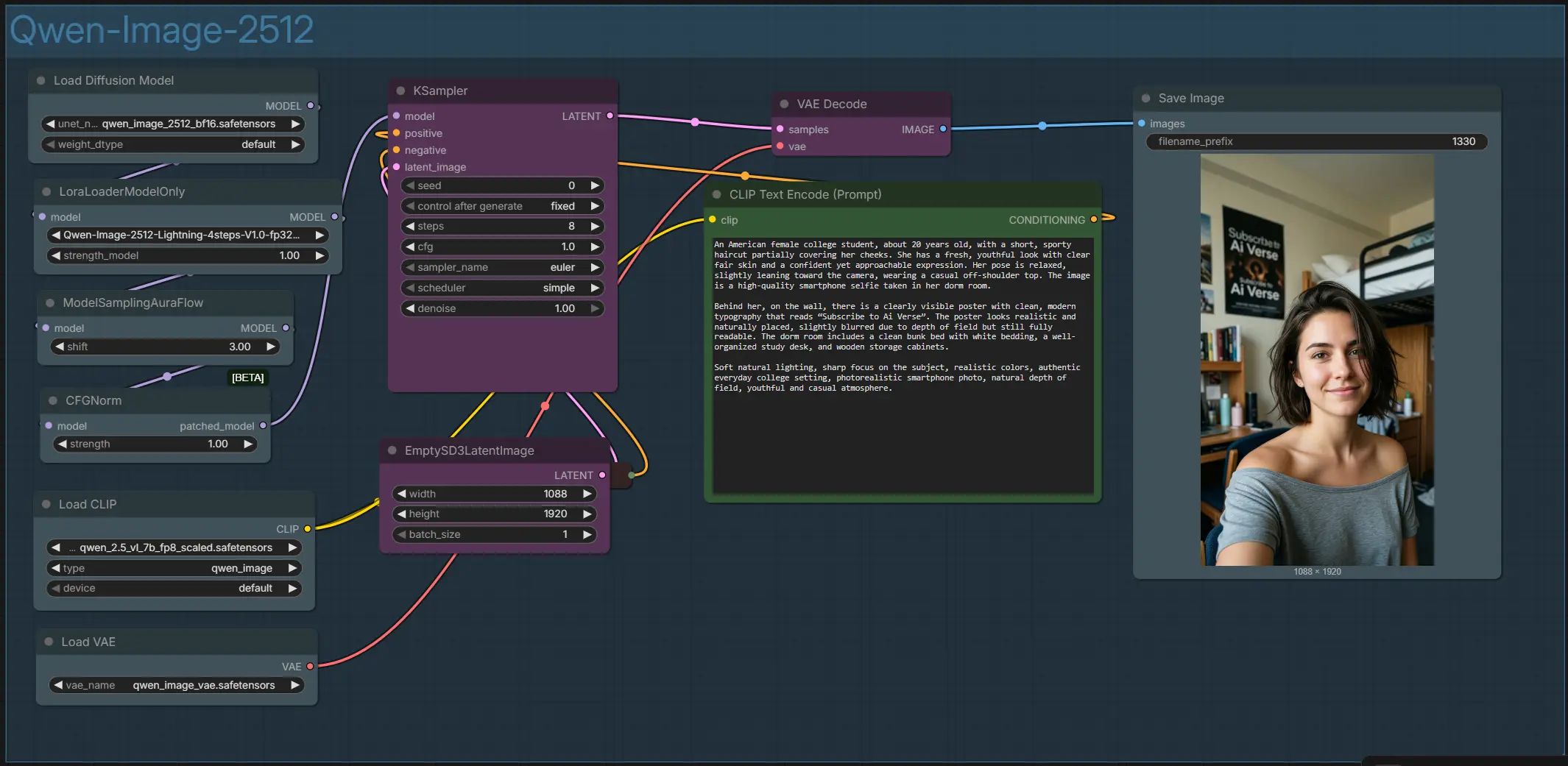






Flujo de trabajo Qwen Image 2512 ComfyUI para retratos y escenas precisos en texto#
Este flujo de trabajo convierte tu indicación en una imagen de alta fidelidad usando Qwen Image 2512. Está diseñado para creadores que necesitan una fuerte alineación de texto a imagen, personas realistas y un renderizado de texto bilingüe confiable dentro de la escena. El gráfico viene preconfigurado con el VAE y codificador de texto de Qwen, además de un Lightning LoRA opcional para generación en pocos pasos, para que puedas pasar de la indicación al resultado con configuración mínima.
Úsalo para arte conceptual, ilustración, señalización, carteles y estilos fotográficos cotidianos. Qwen Image 2512 aporta composición estable y tipografía nítida, lo que lo convierte en una opción sólida para indicaciones que mezclan personas, entornos y texto legible.
Modelos clave en el flujo de trabajo Comfyui Qwen Image 2512#
- Modelo base Qwen-Image 2512 (bfloat16). Modelo de difusión central que sintetiza la imagen a partir de la condicionante. Los pesos listos para Comfy se proporcionan en el paquete Comfy-Org. Model files
- Codificador de texto Qwen2.5-VL 7B. Codifica tu indicación en vectores de condicionamiento que impulsan el diseño, estilo y renderizado de texto de Qwen Image 2512. Text encoder files
- Qwen Image VAE. Decodifica el latente producido por el muestreador de nuevo a una imagen RGB con color y detalle fieles. VAE file
- Qwen-Image-2512-Lightning-4steps-V1.0 LoRA (opcional). Un LoRA comunitario afinado para generación en pocos pasos para acelerar el renderizado con pequeñas compensaciones de calidad. LoRA card
- Para antecedentes sobre la familia de modelos y el enfoque de entrenamiento, consulta el informe técnico de Qwen-Image. Paper
Cómo usar el flujo de trabajo Comfyui Qwen Image 2512#
Flujo general: tu indicación se codifica, se crea un lienzo latente en la resolución elegida, la pila de modelos aplica el modelo base y el LoRA opcional, el muestreador itera para refinar el latente, y el VAE decodifica la imagen final para guardar.
- Resumen del grupo Qwen-Image-2512
- Todo el gráfico está organizado dentro de un solo grupo llamado "Qwen-Image-2512." Conecta el codificador de texto, el modelo y la pila de LoRA, los ayudantes de muestreo y la decodificación VAE. Controlas el aspecto con tus indicaciones positivas y negativas, el tamaño del lienzo y algunos ajustes del muestreador. La salida es una imagen de estilo retrato de alta resolución guardada en tu carpeta de salida de ComfyUI.
- Indicaciones con
CLIPTextEncode(#52) y negativos opcionalesCLIPTextEncode(#32)- Ingresa tu descripción principal en
CLIPTextEncode(#52). Escribe la escena, los sujetos y cualquier texto en la imagen que desees renderizar; Qwen Image 2512 es particularmente fuerte en señalización, carteles, maquetas de UI y subtítulos bilingües. UsaCLIPTextEncode(#32) para negativos opcionales para alejarse de artefactos o estilos no deseados. Mantén los fragmentos de texto entre comillas si necesitas una redacción precisa.
- Ingresa tu descripción principal en
- Lienzo y relación de aspecto con
EmptySD3LatentImage(#57)- Elige tu ancho y alto objetivo aquí para establecer la composición. Los formatos de retrato funcionan bien para personas y selfies, mientras que las proporciones cuadradas y de paisaje se adaptan a diseños de productos y escenas. Los lienzos más grandes ofrecen mayor detalle a costa de memoria y tiempo; comienza modestamente, luego aumenta una vez que te guste el encuadre. La consistencia mejora cuando mantienes la misma relación de aspecto en todas las iteraciones.
- Pila de modelo y LoRA con
UNETLoader(#100) yLoraLoaderModelOnly(#101)- El generador base es Qwen Image 2512 cargado por
UNETLoader(#100). Si deseas renderizados más rápidos, habilita el Lightning LoRA enLoraLoaderModelOnly(#101) para cambiar a un flujo de trabajo de pocos pasos. Esta pila establece las capacidades del modelo para realismo, diseño y alineación de texto a imagen antes de que comience el muestreo.
- El generador base es Qwen Image 2512 cargado por
- Ayudantes de muestreo con
ModelSamplingAuraFlow(#43) yCFGNorm(#55)- Estos dos nodos preparan el modelo para un muestreo estable y equilibrado en contraste.
ModelSamplingAuraFlow(#43) ajusta el cronograma para mantener los detalles nítidos sin exagerar las texturas.CFGNorm(#55) normaliza la guía para mantener un color y exposición consistentes mientras sigue tu indicación.
- Estos dos nodos preparan el modelo para un muestreo estable y equilibrado en contraste.
- Desenfoque y refinamiento con
KSampler(#54)- Esta es la etapa de trabajo que mejora iterativamente el latente de ruido a una imagen coherente. Estableces la semilla para repetibilidad, seleccionas el muestreador y el programador, y eliges cuántos pasos ejecutar. Con Lightning habilitado, puedes apuntar a pocos pasos; con el modelo base solo, usa más pasos para máxima fidelidad.
- Decodificar y guardar con
VAEDecode(#45) ySaveImage(#117)- Después del muestreo, el VAE reconstruye limpiamente el RGB del latente y
SaveImageescribe el PNG final. Si los colores o el contraste se ven apagados, revisa la guía o la redacción de la indicación en lugar de posprocesar; Qwen Image 2512 responde bien a descripciones de iluminación y pistas de materiales.
- Después del muestreo, el VAE reconstruye limpiamente el RGB del latente y
Nodos clave en el flujo de trabajo Comfyui Qwen Image 2512#
UNETLoader(#100)- Carga el modelo base Qwen-Image-2512 que determina la capacidad general y el espacio de estilo. Usa la construcción bf16 para máxima calidad si tu GPU lo permite. Cambia a una variante fp8 o comprimida solo si necesitas ajustar la memoria o aumentar el rendimiento.
LoraLoaderModelOnly(#101)- Aplica el Qwen-Image-2512-Lightning-4steps-V1.0 LoRA sobre el modelo base. Aumenta o disminuye
strength_modelpara mezclar la sintonización de velocidad con la fidelidad base, o configúralo en 0 para deshabilitar. Cuando este LoRA está activo, reducestepsenKSamplera pocas iteraciones para realizar la aceleración.
- Aplica el Qwen-Image-2512-Lightning-4steps-V1.0 LoRA sobre el modelo base. Aumenta o disminuye
ModelSamplingAuraFlow(#43)- Ajusta el comportamiento de muestreo del modelo para un cronograma de estilo flujo que a menudo produce bordes más nítidos y menos manchas. Si los resultados parecen demasiado afilados o poco detallados, ajusta ligeramente el parámetro
shifty vuelve a muestrear. Mantén estables otras variables mientras pruebas para aislar el efecto.
- Ajusta el comportamiento de muestreo del modelo para un cronograma de estilo flujo que a menudo produce bordes más nítidos y menos manchas. Si los resultados parecen demasiado afilados o poco detallados, ajusta ligeramente el parámetro
CFGNorm(#55)- Normaliza la guía sin clasificador para evitar salidas deslavadas o sobresaturadas. Usa
strengthpara decidir cuán asertivamente debe actuar la normalización. Si la precisión del texto disminuye cuando aumentas CFG, incrementa la fuerza de normalización en lugar de aumentar CFG aún más.
- Normaliza la guía sin clasificador para evitar salidas deslavadas o sobresaturadas. Usa
EmptySD3LatentImage(#57)- Establece el tamaño del lienzo latente que define el encuadre y la relación de aspecto. Para personas, las proporciones de retrato reducen la distorsión y ayudan con las proporciones del cuerpo; para carteles, las proporciones cuadradas o de paisaje enfatizan el diseño y los bloques de texto. Aumenta la resolución solo después de que estés satisfecho con la composición.
CLIPTextEncode(#52) yCLIPTextEncode(#32)- El codificador positivo (#52) convierte tu descripción en condicionamiento, incluyendo cadenas de texto explícitas para ser renderizadas en la escena. El codificador negativo (#32) suprime rasgos no deseados como artefactos, dedos extra o fondos ruidosos. Mantén las indicaciones concisas y fácticas para mejor alineación.
KSampler(#54)- Controla semilla, muestreador, programador, pasos, CFG y fuerza de desenfoque. Con Qwen Image 2512, los valores moderados de CFG suelen preservar la fuerte alineación de texto del modelo; si las letras se deforman, baja CFG antes de cambiar el muestreador. Para borradores rápidos habilita Lightning y prueba muy pocos pasos, luego incrementa los pasos para renderizados finales si es necesario.
VAELoader(#34) yVAEDecode(#45)- Carga y aplica el VAE de Qwen para reconstruir color fiel y detalle fino. Mantén el VAE emparejado con el modelo base para evitar cambios de color. Si cambias los pesos base, también cambia al VAE correspondiente.
Extras opcionales#
- Indicación para texto en imagen
- Pon palabras exactas entre comillas rectas, y añade pistas tipográficas breves como "tipografía moderna limpia" o "sans serif en negrita." Incluye sugerencias de ubicación como "cartel de pared" o "letrero de tienda" para anclar dónde debe aparecer el texto.
- Iteración más rápida con Lightning
- Habilita el Lightning LoRA y usa pocos pasos para vistas previas. Una vez que el encuadre y la redacción sean correctos, deshabilita o reduce la fuerza de LoRA y aumenta los pasos para recuperar máxima fidelidad.
- Elecciones de relación de aspecto
- Mantén proporciones consistentes en todas las variaciones. Usa retrato para personas, cuadrado para estudios de productos o logotipos, y paisaje para entornos o diapositivas. Si escalas más tarde, mantén la misma proporción para mantener la composición.
- Disciplina de guía
- Qwen Image 2512 generalmente prefiere un CFG modesto. Si la fidelidad del texto se desliza, baja CFG o aumenta la fuerza de
CFGNormen lugar de acumular más guía.
- Qwen Image 2512 generalmente prefiere un CFG modesto. Si la fidelidad del texto se desliza, baja CFG o aumenta la fuerza de
- Reproducibilidad
- Bloquea una semilla cuando te gusta un resultado para que puedas iterar de manera segura. Cambia un control a la vez para entender su impacto antes de avanzar.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Comfy-Org por los Archivos del Modelo Qwen Image 2512 por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- Archivos del Modelo Comfy-Org/Qwen Image 2512
- Hugging Face: Comfy-Org/Qwen-Image_ComfyUI
- Docs / Notas de Lanzamiento: Archivos del Modelo Qwen Image 2512
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.