
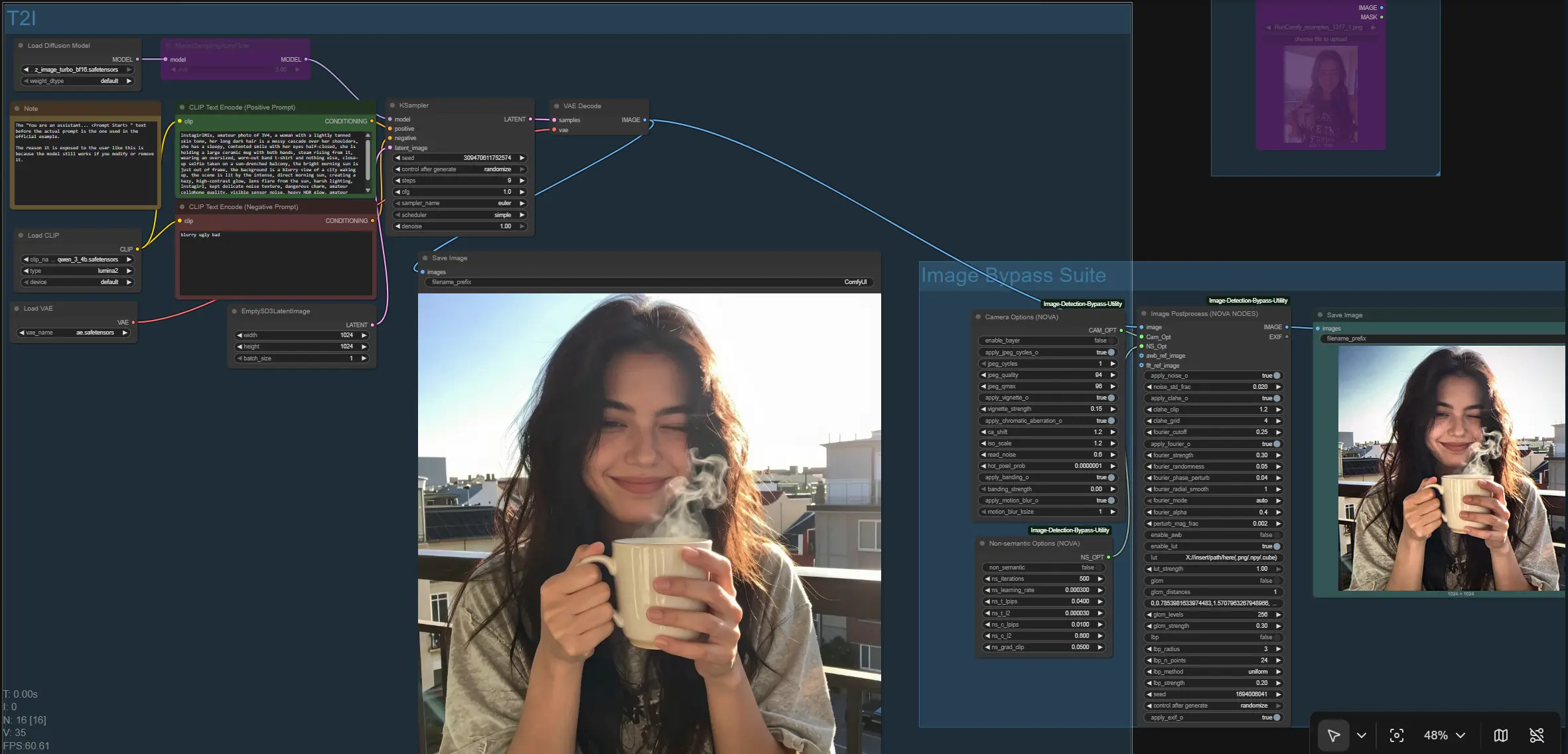







ComfyUI Image Bypass Workflow#
This workflow delivers a modular Image Bypass pipeline for ComfyUI that combines non‑semantic normalization, FFT‑domain controls, and camera pipeline simulation. It is designed for creators and researchers who need a reliable way to process images through an Image Bypass stage while keeping full control over input routing, preprocessing behavior, and output consistency.
At its core, the graph generates or ingests an image, then routes it through an Image Bypass Suite that can apply sensor‑like artifacts, frequency shaping, texture matching, and a perceptual optimizer. The result is a clean, configurable path that fits batch work, automation, and rapid iteration on consumer GPUs. The Image Bypass logic is powered by the open source utility from this repository: PurinNyova/Image-Detection-Bypass-Utility.
Key models in Comfyui Image Bypass workflow#
- z_image_turbo_bf16 (UNet checkpoint). A fast text‑to‑image diffusion backbone used in the T2I branch for quick prototyping and baseline image generation. It is replaceable with your preferred checkpoint. Reference: Comfy-Org/z_image_turbo on Hugging Face.
- VAE (ae.safetensors). Handles latent decoding back to pixels so the output of sampling can be visualized and further processed by the Image Bypass stage. Any compatible VAE can be swapped in if you prefer a different reconstruction profile.
- Prompt encoder (loaded via CLIPLoader). Encodes your positive and negative prompts into conditioning vectors for the sampler. The graph is agnostic to the specific text encoder file you load, so you can substitute models as needed for your base generator.
How to use Comfyui Image Bypass workflow#
At a high level, the workflow offers two ways to produce the image that enters the Image Bypass Suite: a Text‑to‑Image branch (T2I) and an Image‑to‑Image branch (I2I). Both converge on a single processing node that applies the Image Bypass logic and writes the final result to disk. The graph also saves the pre‑bypass baseline so you can compare outputs.
Group: T2I#
Use this path when you want to synthesize a fresh image from prompts. Your prompt encoder is loaded by CLIPLoader (#164) and read by CLIP Text Encode (Positive Prompt) (#168) and CLIP Text Encode (Negative Prompt) (#163). The UNet is loaded with UNETLoader (#165), optionally patched by ModelSamplingAuraFlow (#166) to adjust the model’s sampling behavior, and then sampled with KSampler (#167) starting from EmptySD3LatentImage (#162). The decoded image comes out of VAEDecode (#158) and is saved as a baseline via SaveImage (#159) before entering the Image Bypass Suite. For this branch, your primary inputs are the positive/negative prompts and, if desired, the seed strategy in KSampler (#167).
Group: I2I#
Choose this path when you already have an image to process. Load it via LoadImage (#157) and route the IMAGE output to the Image Bypass Suite input on NovaNodes (#146). This bypasses text conditioning and sampling entirely. It is ideal for batch post‑processing, experiments on existing datasets, or standardizing outputs from other workflows. You can freely switch between T2I and I2I depending on whether you want to generate or strictly transform.
Group: Image Bypass Suite#
This is the heart of the graph. The central processor NovaNodes (#146) receives the incoming image and two option blocks: CameraOptionsNode (#145) and NSOptionsNode (#144). The node can operate in a streamlined auto mode or a manual mode that exposes controls for frequency shaping (FFT smoothing/matching), pixel and phase perturbations, local contrast and tone handling, optional 3D LUTs, and texture statistics adjustment. Two optional inputs let you plug in an auto white‑balance reference and an FFT/texture reference image to guide normalization. The final Image Bypass result is written by SaveImage (#147), giving you both the baseline and the processed output for side‑by‑side evaluation.
Key nodes in Comfyui Image Bypass workflow#
NovaNodes (#146)#
The core Image Bypass processor. It orchestrates frequency‑domain shaping, spatial perturbations, local tone control, LUT application, and optional texture normalization. If you provide an awb_ref_image or fft_ref_image, it will use those references early in the pipeline to guide color and spectral matching. Begin in auto mode to get a sensible baseline, then switch to manual to fine‑tune effect strength and blend for your content and downstream tasks. For consistent comparisons, set and reuse a seed; for exploration, randomize to diversify micro‑variations.
NSOptionsNode (#144)#
Controls the non‑semantic optimizer that nudges pixels while preserving perceptual similarity. It exposes iteration count, learning rate, and perceptual/regularization weights (LPIPS and L2) along with gradient clipping. Use it when you need subtle distribution shifts with minimal visible artifacts; keep changes conservative to maintain natural textures and edges. Disable it entirely to measure how much the Image Bypass pipeline helps without an optimizer.
CameraOptionsNode (#145)#
Simulates sensor and lens characteristics such as demosaic and JPEG cycles, vignette, chromatic aberration, motion blur, banding, and read noise. Treat it as a realism layer that can add plausible acquisition artifacts to your images. Enable only the components that match your target capture conditions; stacking too many can over‑constrain the look. For reproducible outputs, keep the same camera options while varying other parameters.
ModelSamplingAuraFlow (#166)#
Patches the loaded model’s sampling behavior before it reaches KSampler (#167). This is useful when your chosen backbone benefits from an alternate step trajectory. Adjust it when you notice a mismatch between prompt intent and sample structure, and treat it in tandem with your sampler and scheduler choices.
KSampler (#167)#
Executes diffusion sampling given the model, positive and negative conditioning, and the starting latent. The key levers are seed strategy, steps, sampler type, and overall denoise strength. Lower steps help speed, while higher steps can stabilize structure if your base model requires it. Keep this node’s behavior stable while iterating on Image Bypass settings so you can attribute changes to the postprocess rather than the generator.
Optional extras#
- Swap models freely. The Image Bypass Suite is model‑agnostic; you can replace
z_image_turbo_bf16and still route results through the same processing stack. - Use references thoughtfully. Provide
awb_ref_imageandfft_ref_imagethat share lighting and content characteristics with your target domain; mismatched references can reduce realism. - Compare fairly. Keep
SaveImage(#159) as the baseline andSaveImage(#147) as the Image Bypass output so you can A/B test settings and track improvements. - Batch with care. Increase
EmptySD3LatentImage(#162) batch size only as VRAM allows, and prefer fixed seeds when measuring small parameter changes. - Learn the utility. For feature details and ongoing updates to the Image Bypass components, see the upstream project: PurinNyova/Image-Detection-Bypass-Utility.
Credits#
- ComfyUI, the graph engine used by this workflow: comfyanonymous/ComfyUI.
- Example base checkpoint: Comfy-Org/z_image_turbo.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge PurinNyova for Image-Detection-Bypass-Utility for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- PurinNyova/Image-Detection-Bypass-Utility
- GitHub: PurinNyova/Image-Detection-Bypass-Utility
- Docs / Release Notes: Repository (tree/main)
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.