
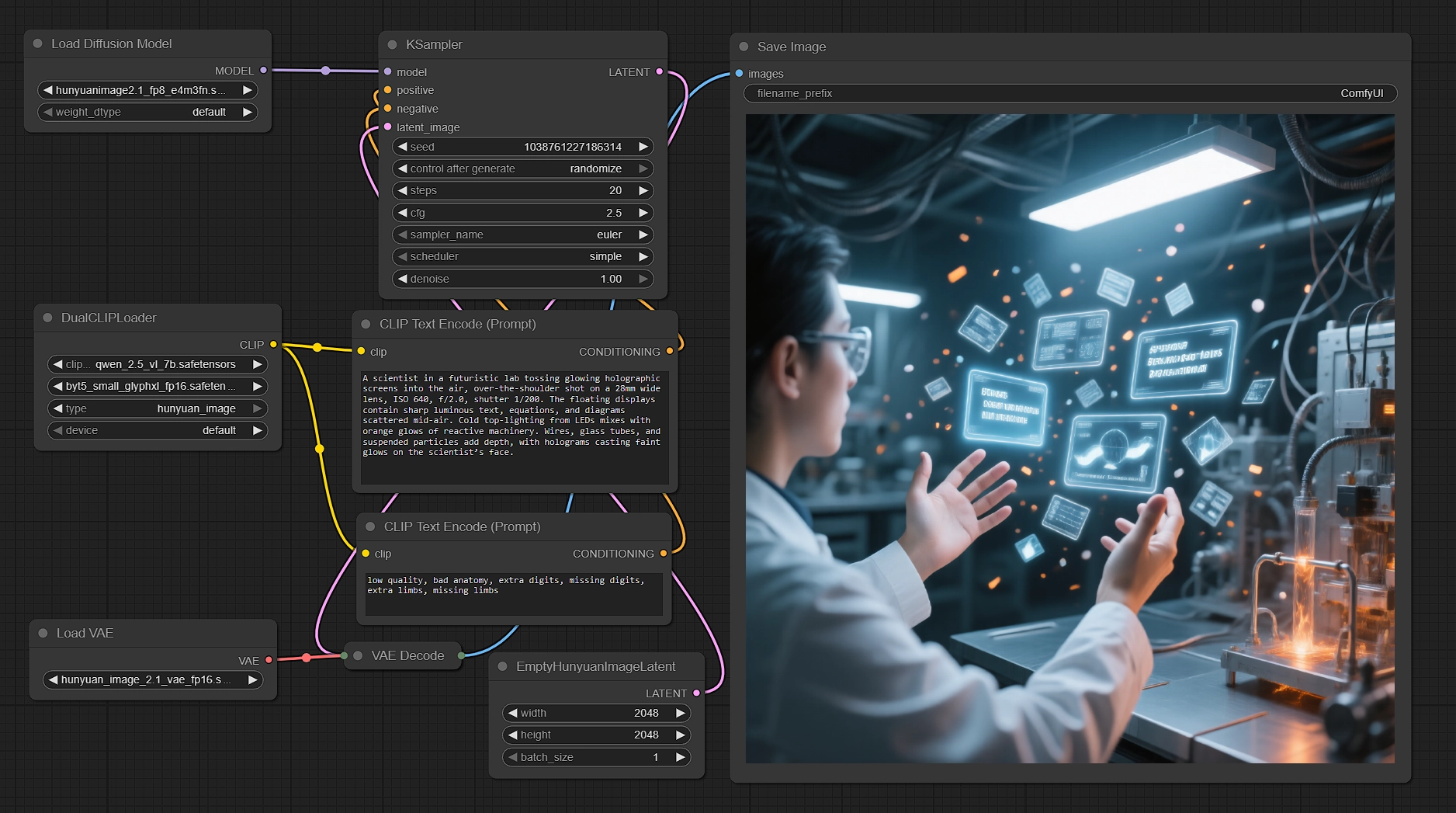










Genera imágenes nativas 2K con Hunyuan Image 2.1 en ComfyUI#
Este flujo de trabajo convierte tus indicaciones en renderizados nativos de 2048×2048 utilizando Hunyuan Image 2.1. Combina el transformador de difusión de Tencent con codificadores de texto duales para mejorar la alineación semántica y la calidad de renderizado de texto, luego muestrea de manera eficiente y decodifica a través del VAE de alta compresión correspondiente. Si necesitas escenas listas para producción, personajes y texto claro en imagen a 2K manteniendo velocidad y control, este flujo de trabajo de ComfyUI Hunyuan Image 2.1 está diseñado para ti.
Creadores, directores de arte y artistas técnicos pueden introducir indicaciones multilingües, ajustar algunos controles y obtener resultados nítidos de manera consistente. El gráfico se entrega con una indicación negativa sensata, un lienzo nativo 2K y un FP8 UNet para mantener el VRAM bajo control, mostrando lo que Hunyuan Image 2.1 puede ofrecer de inmediato.
Modelos clave en el flujo de trabajo Comfyui Hunyuan Image 2.1#
- HunyuanImage‑2.1 de Tencent. Modelo base de texto a imagen con espina dorsal de transformador de difusión, codificadores de texto duales, un VAE 32×, postentrenamiento RLHF y destilación de flujo medio para muestreo eficiente. Enlaces: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct. Codificador multimodal de visión-lenguaje utilizado aquí como el codificador de texto semántico para mejorar la comprensión de indicaciones en escenas complejas y lenguajes. Enlace: Hugging Face
- ByT5 Small. Codificador a nivel de bytes sin tokenización que fortalece el manejo de caracteres y glifos para el renderizado de texto dentro de imágenes. Enlaces: Hugging Face · Paper
Cómo usar el flujo de trabajo Comfyui Hunyuan Image 2.1#
El gráfico sigue un camino claro desde la indicación hasta los píxeles: codifica texto con dos codificadores, prepara un lienzo latente nativo 2K, muestra con Hunyuan Image 2.1, decodifica a través del VAE correspondiente y guarda el resultado.
Codificación de texto con codificadores duales#
- El
DualCLIPLoader(#33) carga Qwen2.5‑VL‑7B y ByT5 Small configurados para Hunyuan Image 2.1. Esta configuración dual permite al modelo analizar semánticas de escena mientras se mantiene robusto ante glifos y texto multilingüe. - Introduce tu descripción principal en
CLIPTextEncode(#6). Puedes escribir en inglés o chino, mezclar pistas de cámara e iluminación e incluir instrucciones de texto en imagen. - Una indicación negativa lista para usar en
CLIPTextEncode(#7) suprime artefactos comunes. Puedes adaptarla a tu estilo o dejarla tal como está para resultados equilibrados.
Lienzo latente en nativo 2K#
EmptyHunyuanImageLatent(#29) inicializa el lienzo en 2048×2048 con un solo lote. Hunyuan Image 2.1 está diseñado para generación 2K, por lo que se recomiendan tamaños nativos 2K para la mejor calidad.- Ajusta el ancho y la altura si es necesario, manteniendo las proporciones que Hunyuan soporta. Para proporciones alternativas, mantente en dimensiones amigables con el modelo para evitar artefactos.
Muestreo eficiente con Hunyuan Image 2.1#
UNETLoader(#37) carga el punto de control FP8 para reducir el VRAM mientras se preserva la fidelidad, luego alimenta aKSampler(#3) para la eliminación de ruido.- Usa las condiciones positivas y negativas de los codificadores para dirigir la composición y claridad. Ajusta la semilla para variedad, pasos para calidad versus velocidad, y guía para la adherencia a la indicación.
- El flujo de trabajo se centra en el camino del modelo base. Hunyuan Image 2.1 también admite una etapa de refinamiento; puedes añadir una más tarde si deseas un pulido adicional.
Decodificar y guardar#
VAELoader(#34) trae el VAE de Hunyuan Image 2.1, yVAEDecode(#8) reconstruye la imagen final del latente muestreado con el esquema de compresión 32× del modelo.SaveImage(#9) escribe el resultado en el directorio elegido. Establece un prefijo claro para el nombre de archivo si planeas iterar entre semillas o indicaciones.
Nodulos clave en el flujo de trabajo Comfyui Hunyuan Image 2.1#
DualCLIPLoader (#33)#
Este nodo carga el par de codificadores de texto que Hunyuan Image 2.1 espera. Mantén el tipo de modelo configurado para Hunyuan, y selecciona Qwen2.5‑VL‑7B y ByT5 Small para combinar un fuerte entendimiento de escena con manejo de texto consciente de glifos. Si iteras en estilo, ajusta la indicación positiva en conjunto con la guía en lugar de cambiar codificadores.
CLIPTextEncode (#6 y #7)#
Estos nodos convierten tus indicaciones positivas y negativas en condicionamiento. Mantén la indicación positiva concisa en la parte superior, luego añade pistas de lente, iluminación y estilo. Usa la indicación negativa para suprimir artefactos como extremidades extra o texto ruidoso; recórtala si la encuentras demasiado restrictiva para tu concepto.
EmptyHunyuanImageLatent (#29)#
Define la resolución y lote de trabajo. El predeterminado 2048×2048 se alinea con la capacidad nativa 2K de Hunyuan Image 2.1. Para otras proporciones, elige pares de ancho y altura amigables con el modelo y considera aumentar ligeramente los pasos si te alejas mucho del cuadrado.
KSampler (#3)#
Impulsa el proceso de eliminación de ruido con Hunyuan Image 2.1. Aumenta los pasos cuando necesites un micro-detalle más fino, disminúyelos para borradores rápidos. Aumenta la guía para una adherencia más fuerte a la indicación pero ten cuidado con la sobresaturación o rigidez; redúcelo para más variación natural. Cambia semillas para explorar composiciones sin cambiar tu indicación.
UNETLoader (#37)#
Carga el UNet de Hunyuan Image 2.1. El punto de control FP8 incluido mantiene el uso de memoria moderado para la salida 2K. Si tienes VRAM suficiente y quieres el máximo margen para configuraciones agresivas, considera una variante de mayor precisión del mismo modelo de los lanzamientos oficiales.
VAELoader (#34) y VAEDecode (#8)#
Estos nodos deben coincidir con la versión de Hunyuan Image 2.1 para decodificar correctamente. El VAE de alta compresión del modelo es clave para la generación rápida 2K; emparejar el VAE correcto evita cambios de color y texturas bloqueadas. Si cambias el modelo base, siempre actualiza el VAE en consecuencia.
Extras opcionales#
- Indicación
- Hunyuan Image 2.1 responde bien a indicaciones estructuradas: sujeto, acción, entorno, cámara, iluminación, estilo. Para texto en imagen, cita las palabras exactas que deseas y mantenlas breves.
- Velocidad y memoria
- El FP8 UNet ya es eficiente. Si necesitas exprimir más, desactiva lotes grandes y prefiere menos pasos. Los nodos cargadores GGUF opcionales están presentes en el gráfico pero deshabilitados por defecto; los usuarios avanzados pueden intercambiarlos al experimentar con puntos de control cuantizados.
- Proporciones
- Mantente en tamaños amigables con el nativo 2K para mejores resultados. Si te aventuras a formatos anchos o altos, verifica un render limpio y considera un pequeño aumento de pasos.
- Refinamiento
- Hunyuan Image 2.1 admite una etapa de refinamiento. Para probarlo, añade un segundo muestreador después del paso base con un punto de control de refinamiento y un ligero desruido para preservar la estructura mientras se aumenta el micro-detalle.
- Referencias
- Detalles del modelo y descargas de Hunyuan Image 2.1: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct: Hugging Face
- ByT5 Small y paper: Hugging Face · Paper
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a @Ai Verse y Hunyuan por Hunyuan Image 2.1 Demo por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación y los repositorios originales enlazados a continuación.
Recursos#
- Hunyuan/Hunyuan Image 2.1 Demo
- Documentos / Notas de lanzamiento: Tutorial de Hunyuan Image 2.1 Demo de @Ai Verse
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.

