
La técnica Hallo2 fue desarrollada por Jiahao Cui, Hui Li, Yao Yao, Hao Zhu, Hanlin Shang, Kaihui Cheng, Hang Zhou, Siyu Zhu y Jingdong Wang de la Universidad Fudan y Baidu Inc. Para más información, visita Hallo2 GitHub. Los nodos y el flujo de trabajo de ComfyUI_Hallo2 fueron desarrollados por smthemex. Para más detalles, visita ComfyUI_Hallo2 GitHub. Todos los créditos a sus contribuciones.
1. Acerca de Hallo2#
Hallo2 es un modelo de vanguardia para generar videos de animación de retratos impulsados por audio de alta calidad, larga duración y resolución 4K. Se basa en el modelo original Hallo con varias mejoras clave:
- Soporta la generación de videos mucho más largos, de hasta decenas de minutos o incluso horas
- Genera videos en resolución 4K
- Permite controlar la expresión y la pose usando indicaciones textuales además del audio
Hallo2 logra esto utilizando técnicas avanzadas como la aumentación de datos para mantener la consistencia durante largas duraciones, la cuantización vectorial de códigos latentes para resolución 4K y un proceso de eliminación de ruido mejorado guiado tanto por audio como por texto.
2. Características Técnicas de Hallo2#
Hallo2 combina varios modelos de IA avanzados y técnicas para crear sus videos de retratos de alta calidad:
- Modelo de Difusión: Este es el "motor" principal que genera los fotogramas del video. Comienza con ruido aleatorio y lo refina gradualmente para que coincida con el resultado deseado, guiado por los indicaciones de audio y texto.
- 3D U-Net: Este es un tipo de red neuronal que actúa como el "escultor" en el proceso de difusión. Observa el fotograma ruidoso actual, el audio y las instrucciones de texto, y sugiere cómo cambiar el ruido para que se parezca más al retrato final.
- Codificador de Audio: Hallo2 utiliza un modelo llamado Wav2Vec2 como sus "oídos" para comprender el audio, convirtiendo la forma de onda bruta en una representación compacta que captura el tono, la velocidad y el contenido del habla.
- Detector de Rostros: Para ayudar a centrarse en la animación del rostro, Hallo2 utiliza un modelo de detección de rostros para ubicar automáticamente el rostro del retrato en la imagen de referencia. Luego sabe dónde aplicar los movimientos de labios y expresiones.
- Compresor de Imágenes: Para trabajar eficientemente con imágenes de alta resolución 4K, Hallo2 utiliza un tipo especial de modelo de autoencoder (VQ-VAE) para comprimirlas en una representación "latente" más pequeña y luego decodificarlas de nuevo a 4K al final. Esto es como cómo los JPEGs reducen el tamaño de los archivos de imagen mientras preservan la calidad.
- Trucos de Aumentación: Para ayudar a mantener la calidad en videos largos, Hallo2 aplica algunas "aumentaciones de datos" inteligentes a los fotogramas generados previamente antes de usarlos para influir en el siguiente fotograma. Estos incluyen ocasionalmente borrar parches aleatorios o agregar ruido sutil. Esto ayuda a prevenir errores acumulativos que podrían arruinar la consistencia con el tiempo.
En resumen, Hallo2 toma audio e imagen de retrato, tiene un "agente" de IA que esculpe fotogramas de video para que coincidan mientras se mantiene fiel al retrato original, y emplea algunos trucos adicionales para mantener todo sincronizado y coherente incluso en videos largos. Todas estas partes trabajan juntas en una canalización de múltiples pasos para producir los impresionantes resultados que ves.
3. Cómo Usar el Flujo de Trabajo de ComfyUI Hallo2#
Hallo2 ha sido integrado en ComfyUI a través de un flujo de trabajo personalizado con varios nodos especializados. Aquí se explica cómo usarlo:
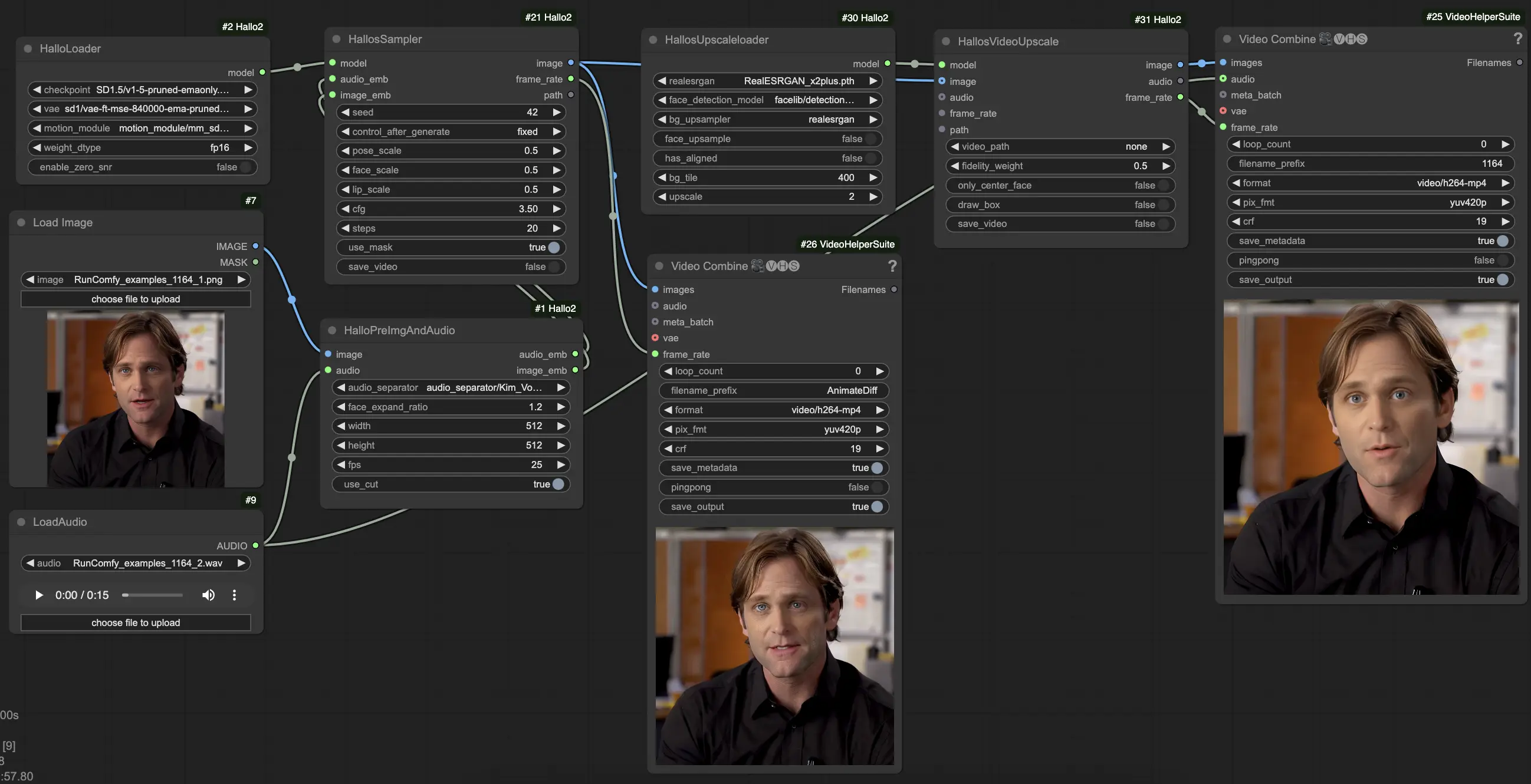
- Carga tu imagen de retrato de referencia usando el nodo
LoadImage. Esta debe ser un retrato claro y frontal. (Consejos: Cuanto mejor enmarcado e iluminado esté tu retrato de referencia, mejores serán los resultados. Evita perfiles laterales, oclusiones, fondos ocupados, etc.) - Carga tu audio conductor usando el nodo
LoadAudio. Debe coincidir con el estado de ánimo que deseas que el retrato exprese. - Conecta la imagen y el audio al nodo
HalloPreImgAndAudio. Esto preprocesa la imagen y el audio en incrustaciones. Parámetros clave:audio_separator: Modelo para separar el habla del ruido de fondo. Generalmente dejarlo en el valor predeterminado.face_expand_ratio: Cuánto expandir la región detectada del rostro. Valores más altos incluyen más del cabello/fondo.width/height: Resolución de generación. Valores más altos son más lentos pero más detallados. 512-1024 cuadrado es un buen equilibrio.fps: FPS de video objetivo. 25 es un buen valor predeterminado.
- Carga el modelo principal Hallo2 usando el nodo
HalloLoader. Apúntalo a tu archivo de punto de control Hallo2, VAE y archivos del módulo de movimiento. - Conecta las incrustaciones de imagen y audio preprocesadas junto con el modelo cargado al nodo
HalloSampler. Esto realiza la generación real del video. Parámetros clave:seed: Semilla aleatoria que determina detalles menores. Cámbiala si no te gusta el primer resultado.pose_scale/face_scale/lip_scale: Cuánto escalar la intensidad de los movimientos de pose, expresión facial y labios. 1.0 = intensidad completa, 0.0 = congelado.cfg: Escala de orientación sin clasificador. Más alto = sigue más de cerca la condicionante pero es menos diverso.steps: Número de pasos de eliminación de ruido. Más pasos = mejor calidad pero más lento.
- En este punto, puedes ver el video generado. Para mejorar aún más la calidad con super-resolución, agrega los nodos
HallosUpscaleloaderyHallosVideoUpscaleal final de la cadena. El cargador de escalado lee un modelo de escalado previamente entrenado, mientras que el nodo de escalado realiza el escalado a 4K.