
Fish Audio S2 TTS para ComfyUI: TTS de alta calidad, clonación de voz y diálogo multi-locutor#
Fish Audio S2 TTS es un flujo de trabajo listo para ejecutar en ComfyUI que convierte texto en discurso natural, clona una voz a partir de un clip de referencia corto y genera conversaciones multi-locutor. Está impulsado por la familia Fish Audio S2-Pro y admite un control de estilo rico a través de etiquetas de emoción y prosodia como [excited], [whisper], y [laughing].
Este flujo de trabajo es ideal para creadores, equipos de producto y desarrolladores que desean síntesis de voz flexible y expresiva dentro de ComfyUI. Incluye opcionalmente texto-a-voz para captura rápida de transcripciones, detección automática de idioma y múltiples opciones de precisión, incluidas fp8 y sage_attention para una inferencia eficiente.
Nota: Ejecuta este flujo de trabajo en una máquina 2X Large o más grande. Las instancias más pequeñas pueden quedarse sin memoria (OOM).
Modelos clave en el flujo de trabajo Comfyui Fish Audio S2 TTS#
- Fish Audio S2-Pro — el modelo de texto-a-voz generativo central utilizado para TTS de un solo locutor, clonación de voz y diálogo multi-locutor. Soporta extensos tokens de estilo y síntesis multilingüe model card y es parte del proyecto Fish-Speech repo.
- Fish Audio S2-Pro FP8 — una variante de S2-Pro eficiente en memoria que reduce las necesidades de VRAM con una mínima pérdida de calidad, recomendada para GPUs limitadas model card.
- OpenAI Whisper large-v3 — un modelo opcional de texto-a-voz utilizado para transcribir automáticamente tu audio de referencia al preparar los mensajes de clonación de voz repo.
Cómo usar el flujo de trabajo Comfyui Fish Audio S2 TTS#
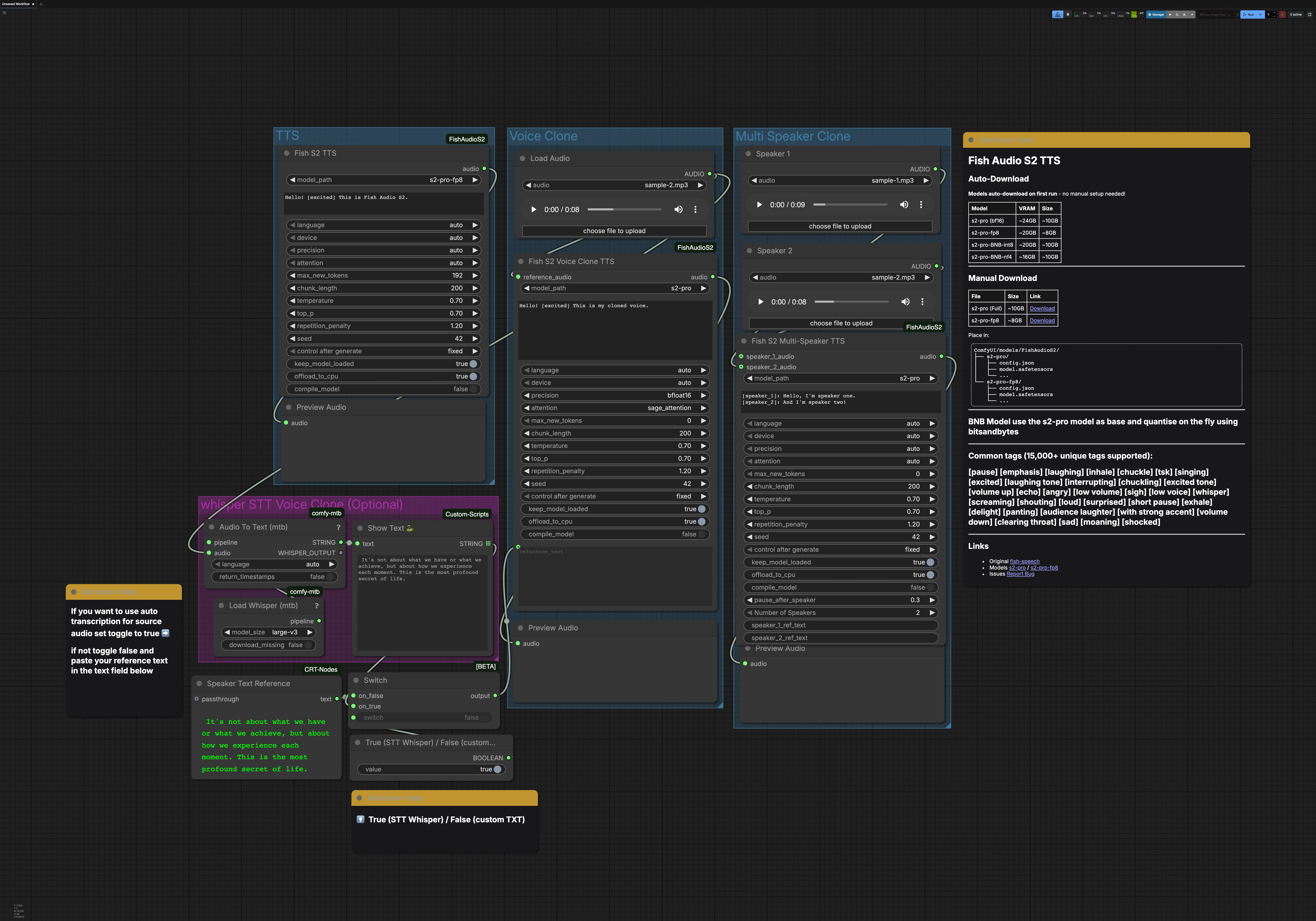
Este flujo de trabajo contiene tres caminos principales que pueden ejecutarse de forma independiente: TTS, Clonación de Voz y Clonación Multi-Locutor. Un grupo opcional Whisper STT puede generar la transcripción para la clonación de voz. Cada camino termina con una vista previa de audio para que puedas monitorear los resultados rápidamente.
Grupo TTS#
El nodo FishS2TTS (#42) realiza texto-a-voz directo con Fish Audio S2 TTS. Introduce tu guion en el cuadro de texto del nodo y añade etiquetas de estilo como [excited], [pause], o [whisper] para dar forma a la emoción y el ritmo. La detección de idioma es automática, por lo que puedes escribir en el idioma objetivo y el modelo se adapta. Elige la variante S2-Pro que se ajuste a la memoria de tu GPU, por ejemplo, fp8 para cargas más ligeras. La salida se dirige a PreviewAudio para escuchar instantáneamente.
Grupo de Clonación de Voz#
Usa LoadAudio para proporcionar un clip de referencia corto y limpio de la voz objetivo, luego enrútalo a FishS2VoiceCloneTTS (#14). Proporciona la transcripción que coincide con el estilo de habla que deseas; el texto preciso ayuda al modelo a preservar el ritmo y el acento. Puedes usar el texto de referencia del grupo STT o escribir el tuyo propio, y puedes añadir etiquetas de estilo para afinar la emoción y la entrega. Las opciones de precisión y backend de atención equilibran la velocidad, la memoria y la estabilidad para líneas largas. El clon sintetizado se envía a PreviewAudio para que puedas iterar rápidamente.
Grupo de Clonación Multi-Locutor#
Carga un clip de referencia por locutor usando los nodos LoadAudio, luego conéctalos a FishS2MultiSpeakerTTS (#41). Proporciona un guion de diálogo que etiquete cada turno con [speaker_1], [speaker_2], y así sucesivamente. Esta plantilla incluye dos locutores por defecto, y el nodo admite la ampliación hasta ocho voces distintas cuando se configura adecuadamente. Puedes mezclar prosa narrativa, etiquetas y diálogo para controlar el flujo y la emoción de cada personaje. La mezcla final se previsualiza para verificar el tiempo y la claridad.
Whisper STT para clonación de voz (opcional)#
Load Whisper (mtb) (#6) con large-v3 potencia Audio To Text (mtb) (#7) para transcribir un clip de referencia automáticamente. El texto reconocido se muestra mediante ShowText|pysssss (#8). Un pequeño interruptor construido con ComfySwitchNode (#34) y un control booleano te permite elegir entre la salida STT (true) o tu propio texto escrito desde Text Box line spot (#31) (false). Esto es útil cuando quieres una transcripción base rápida o al crear un mensaje preciso para la clonación.
Nodos clave en el flujo de trabajo Comfyui Fish Audio S2 TTS#
FishS2TTS (#42)#
Genera discurso de un solo locutor a partir de texto con etiquetas de estilo opcionales y detección automática de idioma. Ajusta la variante del modelo para que coincida con tu hardware, por ejemplo, eligiendo fp8 cuando la VRAM es limitada. Usa el control de semillas para tomas repetibles e introduce pequeños cambios al explorar entregas alternativas. Para guiones largos, selecciona un backend de atención optimizado para la estabilidad.
FishS2VoiceCloneTTS (#14)#
Crea una voz clonada condicionando en reference_audio y reference_text. Se obtienen mejores resultados con un discurso limpio, con tono consistente y una transcripción que refleje la cadencia deseada. Las etiquetas de estilo pueden mezclarse en el texto final para guiar el estado de ánimo sin dañar la identidad. Las configuraciones de precisión y atención ayudan a equilibrar la calidad y la memoria para líneas extendidas.
FishS2MultiSpeakerTTS (#41)#
Sintetiza conversaciones multi-locutor emparejando el audio de referencia de cada locutor con un diálogo marcado por etiquetas [speaker_n]. Aumenta el número de locutores según sea necesario y asigna clips distintos para una separación más fuerte. Mantén el tono de referencia de cada locutor consistente para evitar mezclas. Usa la semilla para una mezcla determinista al renderizar escenas de múltiples tomas.
Extras opcionales#
- Usa las etiquetas de estilo con cuidado. Comienza con algunas como [excited], [whisper], [emphasis], [pause], y aumenta solo según sea necesario para la claridad.
- Para la clonación de voz, recorta el silencio del inicio y el final de la referencia y evita el ruido de fondo para preservar el timbre.
- Si la memoria de la GPU es limitada, prefiere S2-Pro fp8 u opciones de cuantización en tiempo de ejecución. Para la máxima fidelidad, utiliza una mayor precisión.
- La puntuación importa. Las comas y los puntos mejoran la fraseología, y las etiquetas colocadas en los límites de las cláusulas tienden a sonar más naturales.
- Para guiones multi-locutor, mantén una expresión por línea y siempre prefija con la etiqueta correcta [speaker_n] para mantener la separación.
Recursos:
- Tarjeta de modelo Fish Audio S2-Pro: Hugging Face
- Variante S2-Pro fp8: Hugging Face
- Proyecto Fish-Speech: GitHub
- Nodos ComfyUI Fish Audio S2: GitHub
- Whisper large-v3: GitHub
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos sinceramente a Saganaki22 por los Nodos Personalizados de ComfyUI-FishAudioS2, y a Fish Audio por el Modelo S2-Pro por sus contribuciones y mantenimiento. Para obtener detalles autorizados, consulta la documentación y los repositorios originales enlazados a continuación.
Recursos#
- Saganaki22/ComfyUI-FishAudioS2 Nodos Personalizados
- GitHub: Saganaki22/ComfyUI-FishAudioS2
- Fish Audio/S2-Pro Modelo
- Hugging Face: fishaudio/s2-pro
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.
