
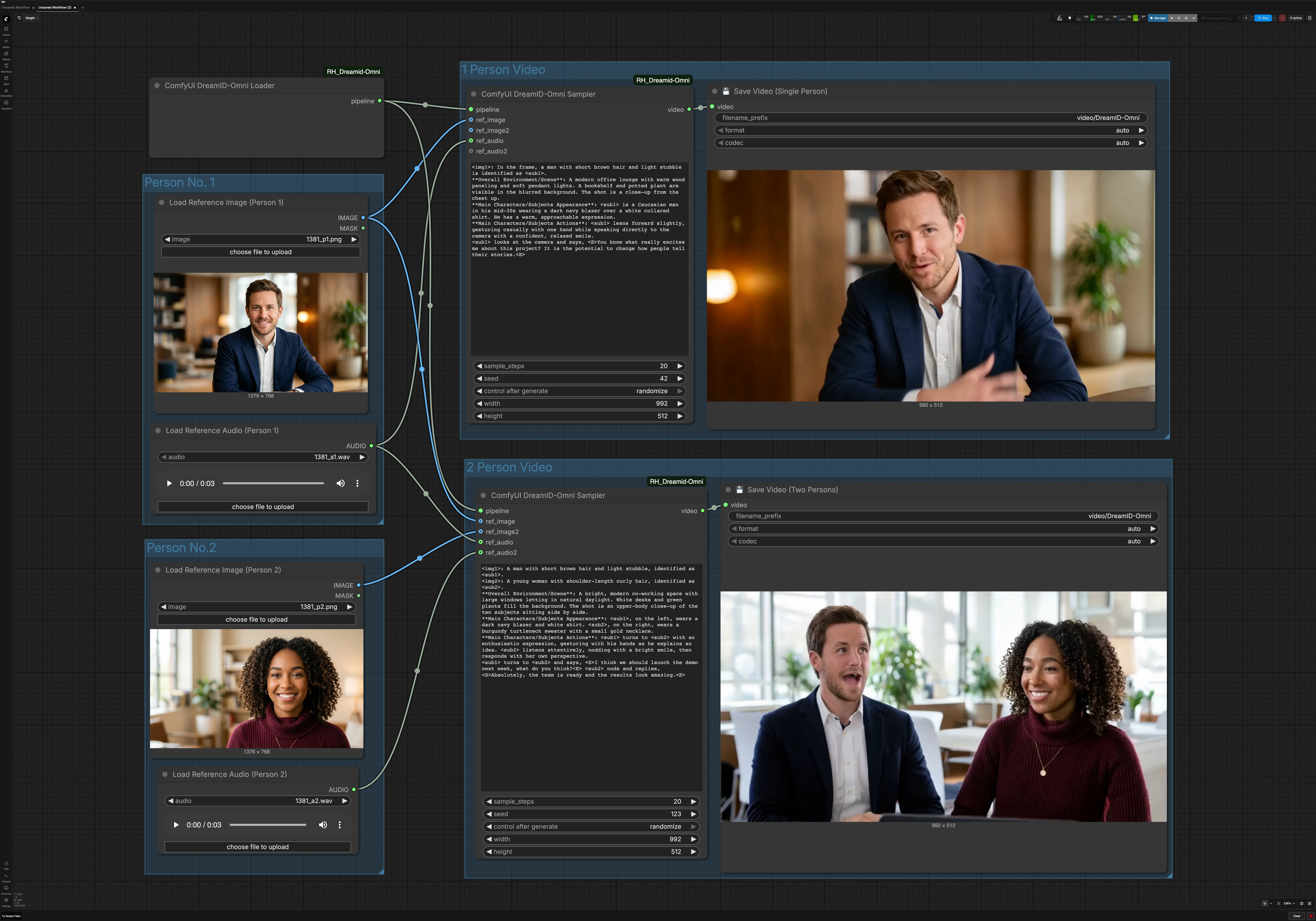
Flujo de trabajo de video hablante de personaje único y dual de DreamID-Omni para ComfyUI#
Este flujo de trabajo convierte una foto de referencia única y un clip de audio en un video de cabeza parlante que preserva la identidad. Impulsado por el modelo DreamID-Omni, combina una estructura de video moderna con movimiento labial impulsado por MMAudio para que el sujeto hable naturalmente mientras mantiene el rostro de tu imagen. También admite dos personajes, permitiendo clips conversacionales lado a lado impulsados por dos voces.
Diseñado para creadores, equipos de producto e investigadores, el flujo de trabajo DreamID-Omni en ComfyUI es ideal para avatares digitales, anuncios personalizados, intros de tutoriales y escenas de diálogo de IA. Proporcionas fotos y audio, opcionalmente describes la toma en un breve aviso, y el gráfico renderiza un video pulido listo para compartir.
Modelos clave en el flujo de trabajo DreamID-Omni de ComfyUI#
- DreamID-Omni. El módulo central de identidad que preserva la persona en tu imagen de referencia a lo largo de los fotogramas mientras responde al audio para movimientos labiales realistas. Consulta el repositorio oficial y los pesos para más detalles: DreamID-Omni y DreamID-Omni en Hugging Face.
- Wan 2.2 generación de video. Una estructura de difusión de video de alta capacidad que sintetiza movimiento coherente, iluminación y composición de la toma mientras DreamID-Omni dirige la identidad facial.
- MMAudio. Un modelo de representación de audio que condiciona las formas de la boca y las sutiles señales faciales para alinearse con el discurso proporcionado, mejorando el realismo de la sincronización labial.
Cómo usar el flujo de trabajo DreamID-Omni de ComfyUI#
Este gráfico tiene dos rutas paralelas. La ruta de una persona usa una imagen y un audio. La ruta de dos personas usa dos imágenes y dos audios para producir un clip conversacional. Un cargador DreamID-Omni compartido inicializa la tubería para ambos.
Persona No. 1#
Usa Cargar Imagen de Referencia (Persona 1) (#6) para seleccionar un retrato claro, de frente, con iluminación uniforme y mínima oclusión. Usa Cargar Audio de Referencia (Persona 1) (#7) para proporcionar el discurso que deseas que el personaje diga. El audio más limpio produce mejor sincronización labial, por lo que se prefiere el discurso sin música o ruido de fondo fuerte. Este par alimenta tanto el modo de una sola persona como, cuando está habilitado, el sujeto izquierdo o primero en el modo de dos personas.
Persona No. 2#
Usa Cargar Imagen de Referencia (Persona 2) (#9) y Cargar Audio de Referencia (Persona 2) (#11) al crear un diálogo. Elige una foto que coincida con el encuadre de la Persona 1 para mantener el equilibrio de la composición. Asegúrate de que el segundo audio sea similar en volumen al primero para evitar cambios perceptuales abruptos. Si solo estás haciendo un clip de una persona, puedes ignorar este grupo.
Video de 1 Persona#
La ruta de un solo hablante es impulsada por ComfyUI DreamID-Omni Sampler (#21). Fusiona la tubería DreamID-Omni con la foto y el audio de la Persona 1, luego renderiza una toma consistente con la descripción breve de la escena en el área de aviso del nodo. Mantén tu aviso conciso y práctico, por ejemplo, describiendo el fondo, la distancia de la cámara y el comportamiento. El resultado es escrito por 💾 Guardar Video (Una Persona) (#4), que nombra y exporta el archivo para ti.
Video de 2 Personas#
La ruta de diálogo usa ComfyUI DreamID-Omni Sampler (#22) para componer dos identidades en un solo cuadro y conducir cada boca con su audio emparejado. Proporciona un breve aviso para establecer el entorno y el estilo de interacción, como un espacio de co-trabajo, tono casual o quién habla primero. Esto ayuda a estabilizar la colocación de la cámara y los gestos mientras DreamID-Omni y MMAudio mantienen la identidad y la alineación labial. El clip es exportado por 💾 Guardar Video (Dos Personas) (#5).
Tubería DreamID-Omni compartida#
ComfyUI DreamID-Omni Loader (#23) inicializa los componentes DreamID-Omni utilizados por ambas rutas. Normalmente no necesitas ajustar nada aquí. Siempre que los pesos y el nodo ComfyUI estén disponibles, el cargador prepara la tubería para que los muestreadores puedan renderizar.
Nodos clave en el flujo de trabajo DreamID-Omni de ComfyUI#
ComfyUI DreamID-Omni Loader (#23)#
Inicializa la tubería DreamID-Omni y hace que sus pesos estén disponibles para los muestreadores posteriores. No hay entradas típicas de usuario aquí. Si mantienes múltiples variantes de modelo, confirma que los pesos correctos están instalados antes de poner en cola los renderizados.
ComfyUI DreamID-Omni Sampler (#21)#
Renderizado de una sola persona. Este nodo combina la tubería del cargador con la primera imagen de referencia y audio para sintetizar una cabeza parlante que preserva la identidad. El campo de aviso es donde defines la escena y el comportamiento; la semilla controla la repetibilidad; la resolución determina el encuadre y el detalle facial; y los pasos intercambian velocidad por fidelidad. Para resultados consistentes en todas las tomas, reutiliza la misma semilla y mantén los cambios de aviso al mínimo.
ComfyUI DreamID-Omni Sampler (#22)#
Renderizado de dos personas. Esta instancia acepta dos fotos y dos audios, emparejando cada voz con su sujeto para un movimiento labial sincronizado. El aviso puede escenificar la conversación y el diseño de la cámara. Ajusta la semilla y la resolución como lo harías en el modo de una sola persona, y asegura que ambos audios estén recortados al tiempo deseado antes de renderizar.
💾 Guardar Video (Una Persona) (#4)#
Escribe la salida de un solo hablante en el disco. Establece la carpeta o nombre base para mantener las versiones organizadas. Si está disponible, deja las opciones de códec y velocidad de fotogramas en automático cuando no estés seguro.
💾 Guardar Video (Dos Personas) (#5)#
Escribe la salida de diálogo en el disco. Usa un nombre base distinto para que los clips de una y dos personas sean fáciles de distinguir. Mantén las configuraciones de exportación automáticas para fiabilidad a menos que tengas un requisito de entrega específico.
Extras opcionales#
- Mantén los rostros lo suficientemente grandes en las imágenes de referencia para ocupar una porción significativa del cuadro para un bloqueo de identidad más fuerte.
- Usa audio de discurso limpio y bien nivelado. Recorta los silencios al inicio para evitar labios congelados iniciales.
- Para un aspecto más estable, reutiliza la misma semilla al iterar en avisos o atuendos.
- Si el espacio para dos personas se siente apretado, reformula el aviso para ampliar la cámara o aumentar el espacio para los hombros en lugar de recortar rostros.
- Para activos y actualizaciones, consulta el modelo y nodo oficiales: DreamID-Omni, ComfyUI_RH_Dreamid-Omni, y pesos de DreamID-Omni.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Guoxu1233 por el modelo/flujo de trabajo DreamID-Omni, a HM-RunningHub por el nodo ComfyUI de DreamID-Omni, y a XuGuo699 por los pesos del modelo DreamID-Omni por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación y repositorios originales enlazados a continuación.
Recursos#
- Repositorio Oficial de DreamID-Omni - https://github.com/Guoxu1233/DreamID-Omni
- GitHub: Guoxu1233/DreamID-Omni
- Nodo ComfyUI de DreamID-Omni (RunningHub) - https://github.com/HM-RunningHub/ComfyUI_RH_Dreamid-Omni
- Pesos del Modelo DreamID-Omni (Hugging Face) - https://huggingface.co/XuGuo699/DreamID-Omni
- Hugging Face: XuGuo699/DreamID-Omni
Nota: El uso de los modelos referenciados, conjuntos de datos y código está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.
