
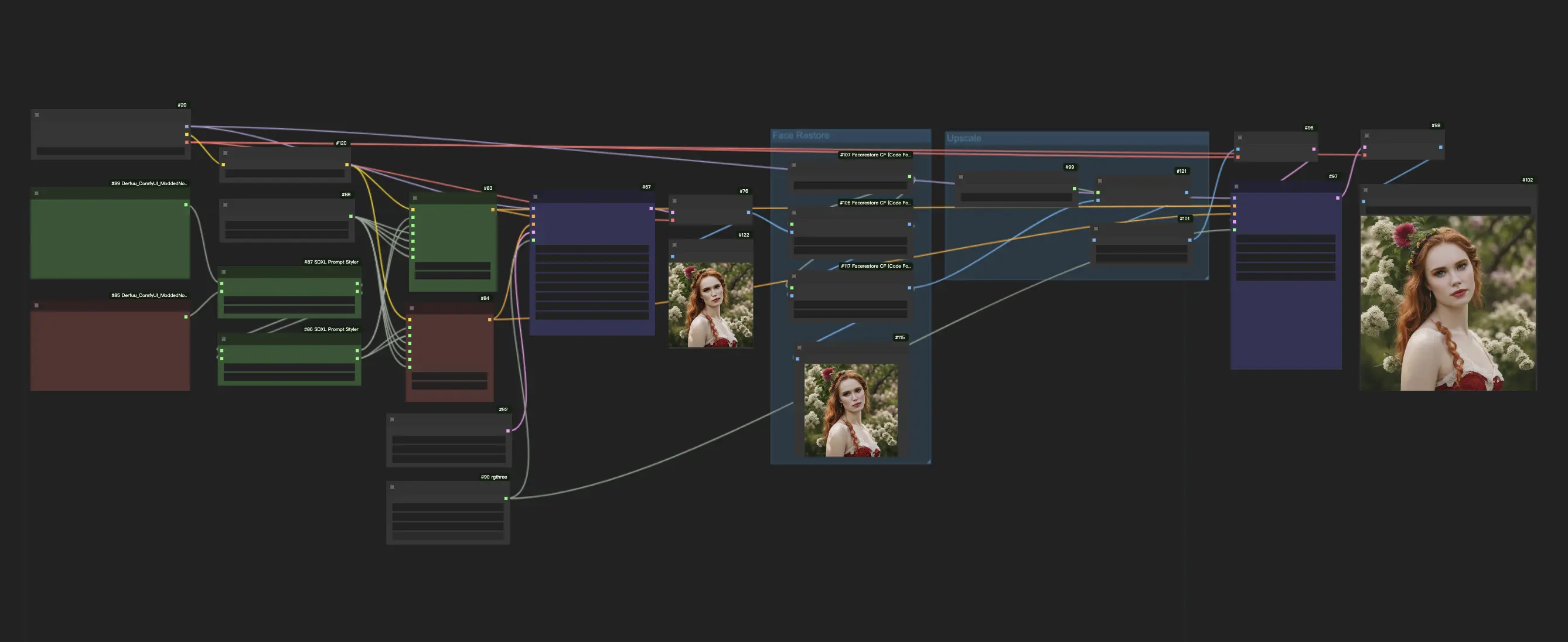

1. ComfyUI SDXL Turbo Workflow#
SDXL Turbo synthesizes image outputs in a single step and generates real-time text-to-image outputs. The quality of SDXL Turbo is relatively good, though it may not always be stable. To enhance results, incorporating a face restoration model and an upscale model for those seeking higher quality outcomes.
2. Overview of SDXL Turbo#
SDXL Turbo is a generative text-to-image model that efficiently converts text prompts into photorealistic images in just one network evaluation. Leveraging a technique called Adversarial Diffusion Distillation (ADD), developed by Stability AI, it drastically shortens the image synthesis process to 1 to 4 steps—far fewer than the traditional 50 steps required by earlier models. This model, an advancement from SDXL 1.0, utilizes ADD to merge score distillation with an adversarial loss, optimizing the use of existing image diffusion models for higher quality with fewer sampling steps. The introduction of this distillation technique not only preserves image quality but also significantly cuts down on the computational effort needed for image generation.
3. Limitations of SDXL Turbo#
Despite its advanced capabilities, SDXL Turbo has certain limitations. It generates images at a fixed resolution of 512x512 pixels and may struggle with rendering legible text, accurately depicting faces and people, and achieving perfect photorealism. These constraints underscore the model's intended use for research and exploration rather than factual or accurate representations of real-world entities.









