
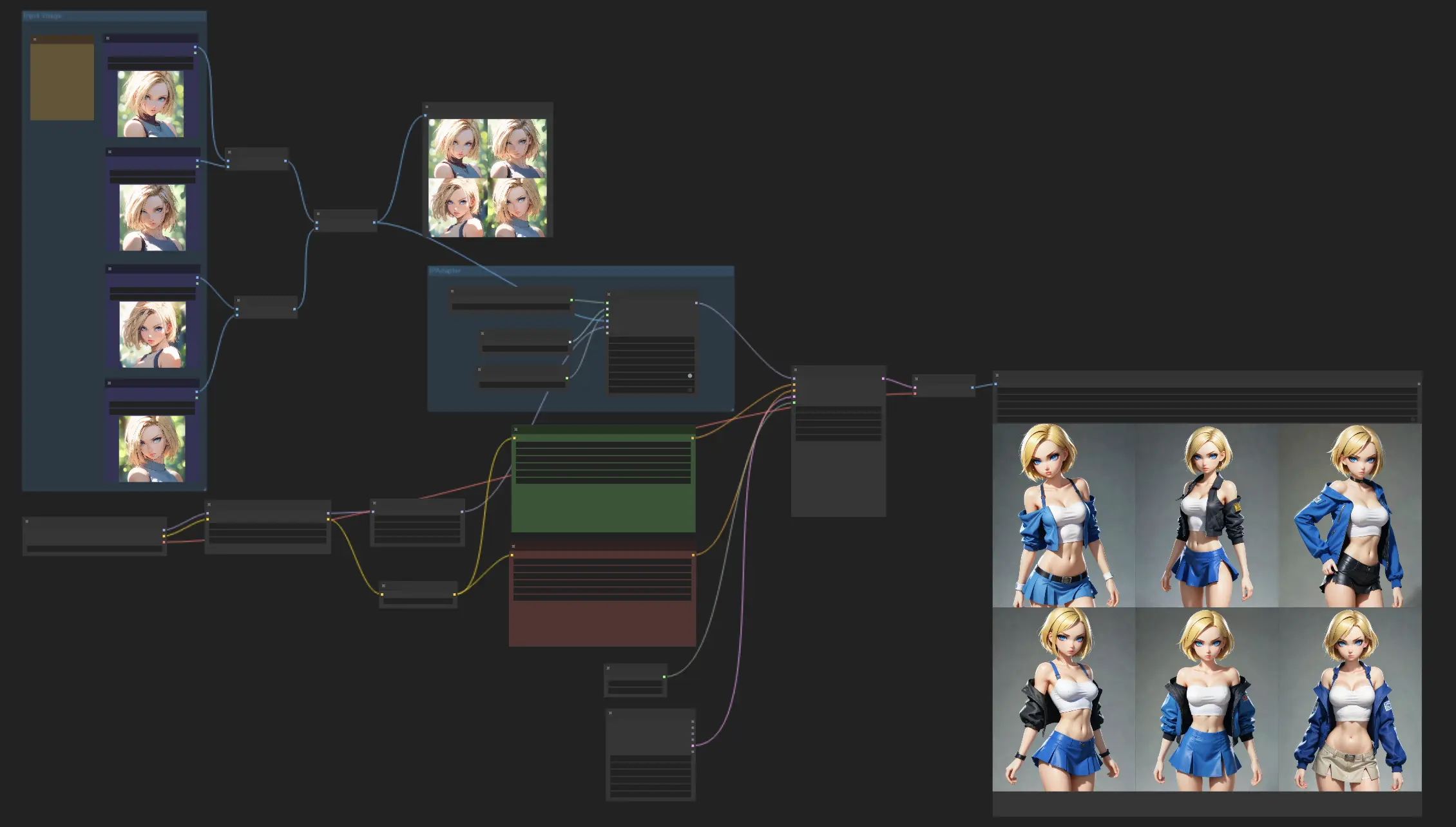

1. Flujo de trabajo de personajes consistentes#
Este flujo de trabajo se trata de crear personajes con una apariencia consistente, aprovechando el modelo IPAdapter Face Plus V2. Simplemente comience cargando algunas imágenes de referencia y luego deje que el modelo Face Plus V2 haga su magia, creando una serie de imágenes que mantengan las mismas características faciales. Siéntase libre de mezclar las cosas con diferentes puntos de control o modelos LoRA para explorar una variedad de estilos, todo mientras mantiene la apariencia de su personaje consistente.
2. Resumen de IPAdapter FaceID/FaceID Plus#
v1.5 FaceID#
Este modelo es la versión base para la identificación de rostros, lo que permite variaciones aumentadas por indicaciones de texto, redes de control y máscaras. Se destaca por su fuerza promedio en el acondicionamiento, lo que lo hace adecuado para tareas generales de acondicionamiento facial. El modelo base FaceID no utiliza un codificador de visión CLIP, lo que implica una configuración más simple sin la necesidad de configuraciones complejas del codificador.
v1.5 FaceID Plus#
El modelo FaceID Plus es una variante más potente, diseñada para efectos de acondicionamiento de imagen a imagen más fuertes. Requiere el uso del codificador de imágenes ViT-H, lo que indica su necesidad de capacidades de procesamiento más altas para el modelado detallado de rostros.
v1.5 FaceID Plus v2#
Una iteración sobre FaceID Plus, este modelo introduce mejoras para un acondicionamiento facial aún más detallado. Al igual que FaceID Plus, utiliza el codificador de imágenes ViT-H. Este modelo apunta a proporcionar una mayor calidad en el modelado de rostros, atendiendo requisitos más matizados.
v1.5 FaceID Portrait#
Diseñado específicamente para retratos, este modelo no utiliza un codificador de visión CLIP. Se enfoca en generar imágenes faciales de alta calidad en entornos de retratos, potencialmente ofreciendo un enfoque especializado para la generación de imágenes de retratos.
SDXL FaceID#
La variante SDXL de FaceID está adaptada para su uso con la arquitectura SDXL, sin emplear un codificador de visión CLIP. Representa un modelo base dentro de la suite SDXL, diseñado para arquitecturas de aprendizaje profundo escalables, enfocándose en tareas de identificación de rostros.
SDXL FaceID Plus v2#
Esta es una versión más fuerte del modelo FaceID para la arquitectura SDXL, utilizando el codificador de imágenes ViT-H. Está diseñado para ofrecer efectos mejorados de acondicionamiento facial dentro del marco SDXL, apuntando a tareas de generación de imágenes de alta calidad.
3. Cómo usar IPAdapter FaceID/FaceID Plus#
3.1. Elija el modelo FaceID/FaceID Plus#
Seleccione su modelo preferido de FaceID o FaceID Plus para comenzar a crear sus imágenes. Dentro de la configuración, encontrará opciones para ajustar tanto los pesos como el ruido. Estos ajustes son clave para afinar la apariencia de sus imágenes generadas, permitiéndole lograr el aspecto preciso que busca.
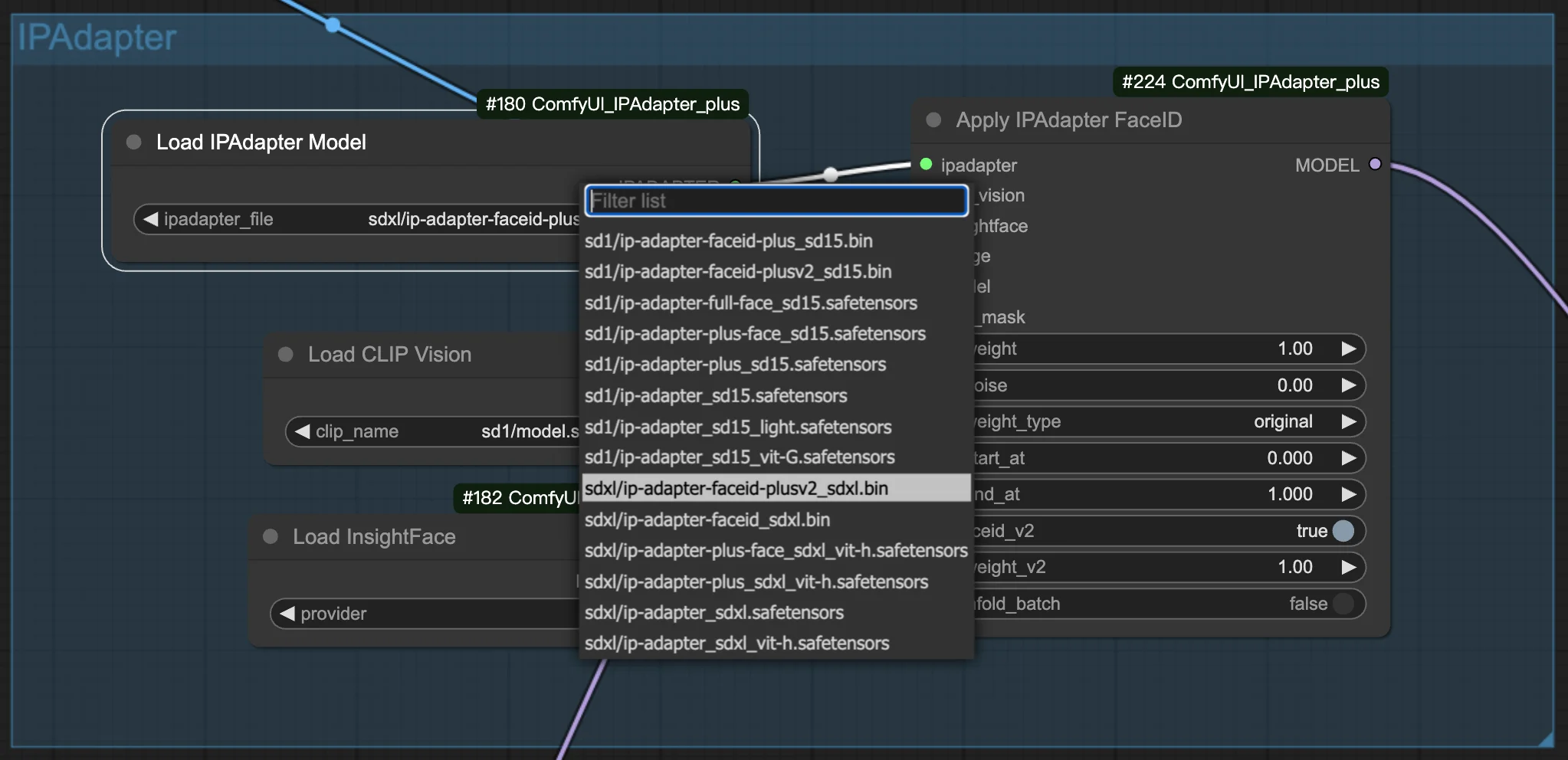
3.2. Preparando la imagen de referencia#
Cuando se utilizan nodos IPAdapter FaceID, el modelo de visión CLIP procesa su imagen de referencia redimensionándola y centrándola a una dimensión de 224x224 píxeles. Este ajuste automático se enfoca en el centro de la imagen, haciendo crucial que el sujeto principal de su imagen, como el rostro de un personaje, esté posicionado centralmente. Si el sujeto está descentrado, especialmente en imágenes de retrato o paisaje, los resultados podrían no cumplir con sus expectativas. Para obtener los mejores resultados, se recomienda encarecidamente utilizar imágenes cuadradas con el sujeto centrado.





