
ACE-Step 1.5XL Base texto a música: Flujo de trabajo de indicación a canción para ComfyUI#
Este flujo de trabajo convierte descripciones en lenguaje natural en audio terminado usando la familia de difusión ACE-Step 1.5XL Base. Empareja el modelo base con su VAE ACE Step y codificadores de texto duales Qwen para mantener los resultados firmemente en el ámbito musical en lugar de TTS o habla. Si deseas música AI impulsada por indicaciones con estructura, tempos e instrumentación predecibles, este pipeline de ACE-Step 1.5XL Base texto a música es una configuración mínima y enfocada que te lleva de la idea a MP3 rápidamente.
Diseñado para productores, diseñadores de sonido y creadores, el gráfico enfatiza la claridad: elige modelos, establece una duración, escribe una indicación musical, luego genera y guarda. El flujo de trabajo de ACE-Step 1.5XL Base texto a música es lo suficientemente compacto para iteraciones rápidas mientras se mantiene expresivo para arreglos detallados, claves y tempos.
Modelos clave en Comfyui ACE-Step 1.5XL Base texto a música flujo de trabajo#
- Modelo de difusión ACE-Step 1.5 XL Base (bf16). La columna vertebral generativa que desruida las latentes de audio en frases musicales coherentes y texturas. Archivo del modelo
- ACE Step 1.5 VAE. El autoencoder variacional emparejado que codifica/decodifica entre el espacio latente y el dominio de la forma de onda, preservando el timbre y los balances de mezcla. Archivo del modelo
- Codificador de texto Qwen 4B ACE15. Un gran codificador de texto adaptado para ACE que captura ricas semánticas musicales, estructura y señales de arreglo de la indicación. Archivo del modelo
- Codificador de texto Qwen 0.6B ACE15. Un codificador adaptado a ACE más ligero que prioriza la velocidad y la eficiencia de recursos mientras retiene una fuerte comprensión de la indicación. Archivo del modelo
Cómo usar Comfyui ACE-Step 1.5XL Base texto a música flujo de trabajo#
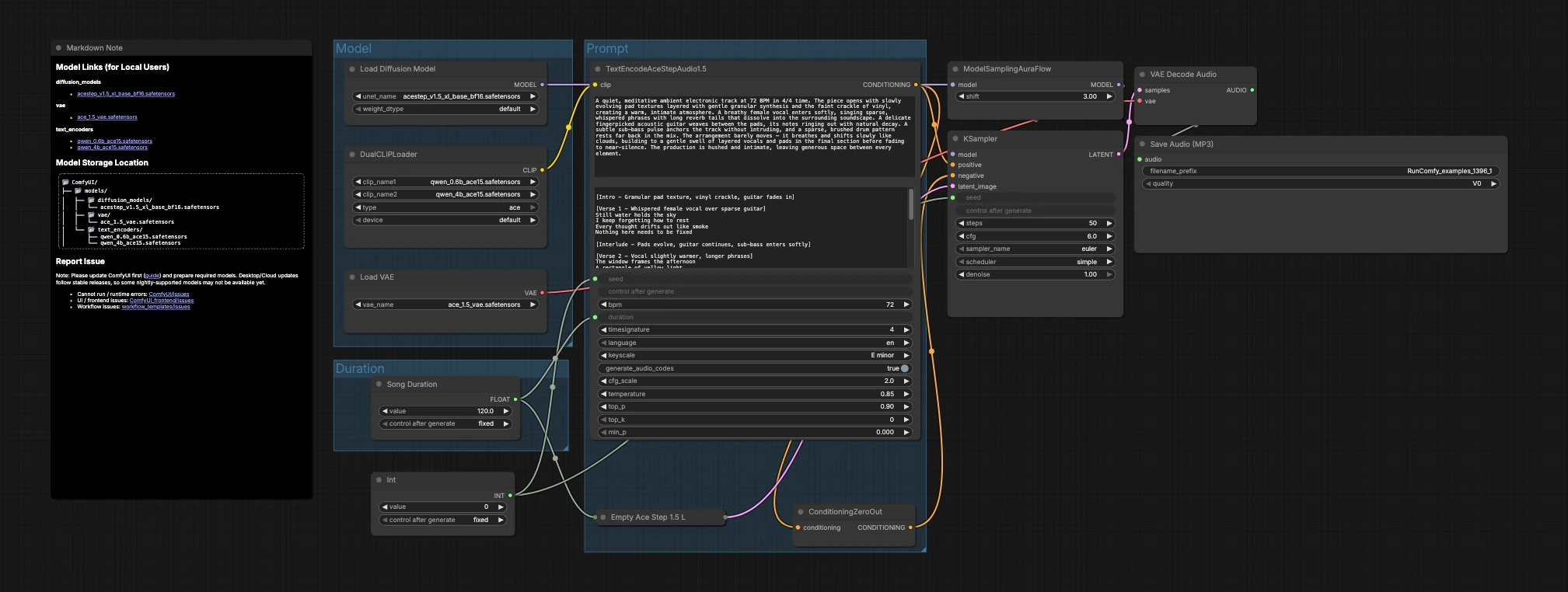
El gráfico está organizado en tres grupos que fluyen hacia la generación y exportación: Modelo, Duración e Indicación. Cargas los modelos, eliges una longitud objetivo, describes la música, luego el muestreador crea latentes que el VAE decodifica en audio.
Modelo#
Este grupo carga los activos principales. UNETLoader (#104) selecciona el punto de control de difusión ACE-Step 1.5 XL Base, y VAELoader (#106) carga el VAE ACE Step 1.5 correspondiente para que la calidad de decodificación se alinee con el entrenamiento. DualCLIPLoader (#105) trae ambos codificadores Qwen ACE15; el flujo de trabajo los usa conjuntamente para que las indicaciones de texto ricas se traduzcan en un fuerte acondicionamiento musical.
Duración#
Aquí decides cuánto debe durar la pieza. Song Duration (#99) establece la longitud objetivo en segundos y la transmite hacia adelante para que el lienzo latente y el acondicionamiento de texto estén de acuerdo. PrimitiveInt (#109) proporciona una semilla, permitiéndote fijar resultados exactos para reproducibilidad o variarla para explorar tomas alternativas.
Indicación#
Aquí es donde el lenguaje se convierte en música. Escribe tu descripción en TextEncodeAceStepAudio1.5 (#94), incluyendo metadatos musicales útiles como tempo (BPM), métrica, clave, instrumentación, arreglo, presencia vocal y notas de mezcla. El nodo emite el acondicionamiento positivo; ConditioningZeroOut (#47) suministra un camino negativo neutral para que la generación se mantenga enfocada en tu descripción. EmptyAceStep1.5LatentAudio (#98) inicializa una línea de tiempo de audio latente para la duración elegida. ModelSamplingAuraFlow (#78) adapta el modelo base a un programador adecuado para el audio ACE-Step. KSampler (#3) combina modelo, acondicionamiento, latente y semilla para generar el latente musical. VAEDecodeAudio (#18) convierte el latente de nuevo a forma de onda, y SaveAudioMP3 (#107) escribe el resultado en un archivo MP3 listo para compartir.
Nodos clave en Comfyui ACE-Step 1.5XL Base texto a música flujo de trabajo#
TextEncodeAceStepAudio1.5 (#94)#
Convierte tu indicación en acondicionamiento que el modelo de difusión puede seguir. Acepta detalles musicales como tempo, firma de tiempo, clave, notas de arreglo, instrumentación, lenguaje e intención vocal opcional. Para obtener los mejores resultados, sé concreto sobre el género, la sensación y la ubicación en la mezcla, y mantén las señales estructurales concisas para que el modelo pueda mantener la coherencia durante la duración solicitada.
EmptyAceStep1.5LatentAudio (#98)#
Crea la “lienzo” de audio latente para la pieza. Alinea sus segundos con lo que estableciste en Song Duration (#99) y referenciado en el codificador de texto para evitar truncamiento o relleno no deseado. Los lienzos más largos invitan a un desarrollo más gradual, mientras que los más cortos se adaptan a bucles, señales y jingles.
ModelSamplingAuraFlow (#78)#
Configura la estrategia de muestreo adaptada al audio ACE-Step. Úsalo como se proporciona para resultados estables; ajusta solo si tienes una preferencia de programador específica, ya que interactúa con el conteo de pasos y la guía en KSampler (#3).
KSampler (#3)#
Realiza la desruida que convierte el acondicionamiento en latentes de audio. Las palancas clave aquí son el tipo de muestreador, el conteo de pasos y la semilla. Aumenta los pasos para refinar los detalles a costa de tiempo, y mantén la semilla fija al comparar indicaciones para que puedas atribuir cambios al texto en lugar de al azar.
DualCLIPLoader (#105)#
Carga ambos codificadores de texto Qwen ACE15. Si tienes acceso a ambos, comienza con el codificador 4B activo para una comprensión más rica del lenguaje; cambia al 0.6B cuando necesites iteraciones más rápidas o menor uso de memoria. Mantén la elección del codificador constante en las tomas al evaluar ediciones sutiles de la indicación.
ConditioningZeroOut (#47)#
Proporciona un camino negativo neutral. Si deseas suprimir artefactos específicos o alejarte del contenido hablado, puedes reemplazar esto con un nodo de indicación negativa real; de lo contrario, el negativo anulado mantiene la generación de ACE-Step 1.5XL Base texto a música enfocada en tu descripción positiva.
Extras opcionales#
- Comienza las indicaciones con una receta compacta: género + estado de ánimo + tempo + métrica + clave + instrumentación + arreglo + notas de mezcla.
- Usa verbos musicales explícitos y roles (líder, pad, bajo, percusión) para que el modelo asigne espacio en la mezcla y evite contenido similar al habla.
- Fija la semilla al probar A/B indicaciones, luego varía la semilla para explorar actuaciones alternativas de una idea ganadora.
- Mantén la duración alineada a través de
Song Duration(#99),TextEncodeAceStepAudio1.5(#94), yEmptyAceStep1.5LatentAudio(#98) para un fraseo predecible. - Elige Qwen 4B para una comprensión más rica de la indicación o 0.6B para velocidad; mantén tu elección constante mientras iteras para hacer comparaciones justas.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Comfy.org por el flujo de trabajo audio_ace_step1_5_xl_base, Comfy-Org por el modelo de difusión ACE Step 1.5 XL Base y ACE Step 1.5 VAE, y al equipo de Qwen por los codificadores de texto 0.6B y 4B ACE15 por sus contribuciones y mantenimiento. Para obtener detalles autorizados, consulta la documentación original y los repositorios vinculados a continuación.
Recursos#
- Comfy.org/Página fuente del flujo de trabajo
- Documentación / Notas de la versión: página del flujo de trabajo audio_ace_step1_5_xl_base
- Comfy-Org/Modelo de difusión ACE Step 1.5 XL Base
- Hugging Face: acestep_v1.5_xl_base_bf16.safetensors
- Comfy-Org/ACE Step 1.5 VAE
- Hugging Face: ace_1.5_vae.safetensors
- Comfy-Org/Codificador de texto Qwen 0.6B ACE15
- Hugging Face: qwen_0.6b_ace15.safetensors
- Comfy-Org/Codificador de texto Qwen 4B ACE15
- Hugging Face: qwen_4b_ace15.safetensors
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.

