
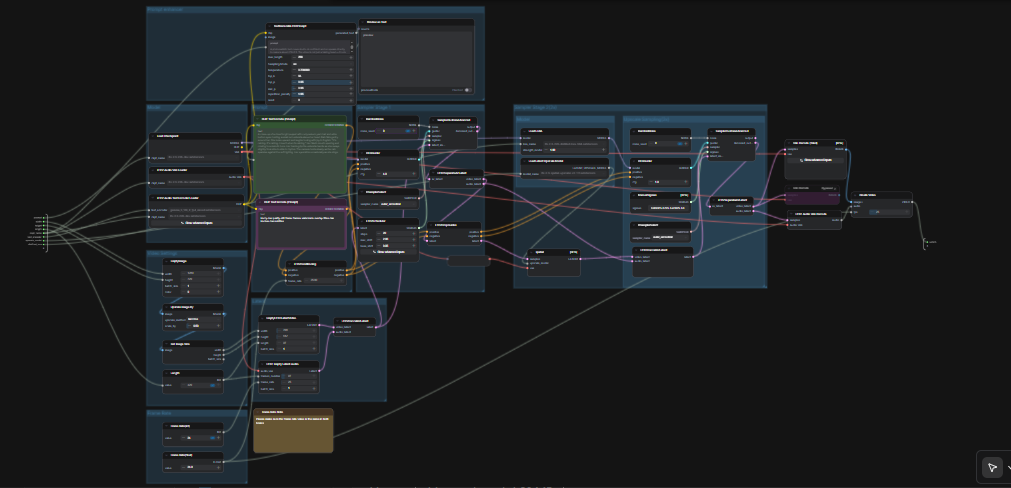
LTX 2.3 ComfyUI: Text-zu-Video mit sauberem Audio, zweistufigem Sampling und 2× räumlichem Upscaling#
Dieser LTX 2.3 ComfyUI-Workflow verwandelt kurze Eingaben in ausgereifte, filmische Videos mit synchronisiertem Audio. Er basiert auf dem Lightricks LTX‑2.3 Modell und ist für hohe visuelle Kohärenz, stabile Bewegungen und sendefreundliche Ausgaben konfiguriert. Kreative, Editoren und technische Künstler können mit einer einzigen Eingabe zu einer MP4 mit Audio in einem Durchgang gelangen, indem sie einen optimierten Graphen verwenden, der einen Prompt-Verstärker, zwei Sampling-Stufen und einen 2× latenten Upscaler beinhaltet.
Im Vergleich zu typischen Text-zu-Video-Setups betont dieser Graph Szenenkonsistenz und Eingabegenauigkeit. Der Standardpfad generiert ein AV-Latent, skaliert es im latenten Raum für schärfere Details auf und dekodiert dann zu Frames und Audio, bevor alles in eine bereite Video-Datei verpackt wird. Wenn Sie moderne Open-Source-Video-Modelle erkunden, ist dieser LTX 2.3 ComfyUI-Workflow eine schnelle Möglichkeit, Produktionsqualität in Bewegung zu erhalten.
Wichtige Modelle im Comfyui LTX 2.3 ComfyUI-Workflow#
- LTX‑2.3 22B (dev) Checkpoint von Lightricks. Das Kernmodell für Text-zu-Video, das hochkoherente Bewegungen und starke Szenenkonsistenz produziert. Hugging Face • GitHub
- Gemma 3 12B Instruct Text Encoder (FP4 gemischt). Bietet robuste Sprachverständnis für bessere Eingabegrundlage und reichere Szenendetails. Hugging Face
- LTX‑2.3 Spatial Upscaler x2 1.0. Ein latenter Upscaler, der räumliche Details schärft, ohne die Bewegungskonsistenz zu brechen. Hugging Face
- LTX‑2.3 22B Distilled LoRA (384). Ein destillierter Adapter, der Texturtreue verfeinert und den Stil während des Upscale/Refine-Stadiums stabilisiert. Hugging Face
- LTX Audio VAE. Das Audiomodul, das mit LTX‑2.3 gekoppelt ist und saubere, synchronisierte Klanggenerierung aus derselben Eingabe ermöglicht. Hugging Face
Verwendung des Comfyui LTX 2.3 ComfyUI-Workflows#
Der Graph läuft in zwei koordinierten Durchgängen. Zuerst erzeugt er ein AV-Latent in einer Arbeitsauflösung mit Ihrer Eingabe. Dann führt er ein 2× latentes Upscale und einen zweiten Sampling-Durchgang mit einem destillierten LoRA durch, bevor er zu Frames und Audio dekodiert und schließlich zu MP4 muxed.
Prompt-Verstärker#
Der TextGenerateLTX2Prompt (#149) Knoten schreibt einfache Sprache in eine modellfreundliche Eingabe um, die Aktionen, visuelle und akustische Hinweise abdeckt. Geben Sie Ihre Szenenbeschreibung ein; optionales Referenzbildmaterial kann angeschlossen werden, wenn Sie eine Anleitung für die Rahmung oder den Stil wünschen. Der generierte Text wird an einen positiven Encoder weitergeleitet, während eine qualitätsorientierte negative Eingabe Artefakte reduziert. Dieses Gleichgewicht hilft dem LTX‑2.3 Modell, ohne die Kreativität übermäßig einzuschränken, auf Kurs zu bleiben.
Modell#
Der CheckpointLoaderSimple (#146) lädt den LTX‑2.3 22B Checkpoint und stellt sowohl das Modell als auch seine VAE bereit. LTXAVTextEncoderLoader (#147) bringt den Gemma 3 12B Instruct Text Encoder ein, den der Workflow für sowohl positive als auch negative Konditionierung verwendet. Behalten Sie diese Auswahl bei, es sei denn, Sie testen andere LTX-Varianten, da der Rest des Graphen auf dieses Paar abgestimmt ist.
Videoeinstellungen#
Auflösung und Dauer werden mit einem leichten Bildgerüst und der Length-Steuerung festgelegt. Der Graph liest die Bildgröße, skaliert sie für eine Arbeitsauflösung und leitet diese Werte an den Video-Latent-Ersteller weiter. LTX-Modelle haben Schrittbegrenzungen; halten Sie sich an Größen, die einem 32-Schritt-Muster folgen, und Längen, die mit der Bildfrequenz des Modells übereinstimmen. Der Graph wird illegale Werte sanft auf die nächstgelegenen gültigen Snaps schnappen, aber gültige Größen von Anfang an zu wählen, führt zu der besten Komposition.
Bildrate#
Zwei kleine Steuerungen legen FPS für sowohl Konditionierung als auch endgültige Kodierung fest: Frame Rate(int) (#141) und Frame Rate(float) (#140). Halten Sie sie identisch, damit die Bewegungstiming und Audioausrichtung über die gesamte Pipeline hinweg konsistent bleiben. Wählen Sie eine filmische Rate, wenn Sie eine glattere Bewegung wünschen, oder passen Sie die Plattform-Standards an, wenn Sie auf soziale Formate abzielen.
Latent#
EmptyLTXVLatentVideo (#121) initialisiert das Video-Latent und LTXVEmptyLatentAudio (#119) macht dasselbe für Audio. LTXVConcatAVLatent (#122) verbindet sie zu einem einzigen AV-Latent, sodass Textführung beide Modalitäten gemeinsam steuern kann. LTXVConditioning (#120) fügt positive und negative Konditionierung hinzu, und LTXVCropGuides (#115) passt die Führung an das räumliche Layout des Latents für zuverlässigere Rahmung an.
Sampler-Stufe 1#
Diese Stufe erstellt das initiale AV-Latent mithilfe von RandomNoise (#151), KSamplerSelect (#144) und dem LTX-bewussten LTXVScheduler (#112) mit einem CFGGuider (#139). Der Scheduler ist speziell für LTX zugeschnitten, um zeitliche Stabilität mit Eingabeanpassung in Einklang zu bringen. Wenn Sie mehr Variation wünschen, ändern Sie den Rausch-Seed; für eine stabilere Anpassung an das Skript bevorzugen Sie Sampler, die zeitliche Kohärenz bewahren.
Modell (LoRA)#
LoraLoaderModelOnly (#143) wendet das LTX‑2.3 destillierte LoRA vor der Verfeinerung an. Dieser Adapter verbessert subtil die Texturpolitur und Stiltreue, ohne Bewegungskonsistenz zu verlieren. Es ist am auffälligsten bei Haut, Stoffen und spekulären Highlights.
Upscale Sampling (2×)#
LTXVLatentUpsampler (#130) führt ein 2× räumliches Upscale im latenten Raum unter Verwendung des geladenen LatentUpscaleModelLoader (#114) und der Basis-VAE durch. Da das Upscaling vor dem Dekodieren erfolgt, behalten Sie die zeitliche Glätte bei, während Sie feine räumliche Details gewinnen. Die hochskalierten Video- und Audio-Latents werden dann mit LTXVConcatAVLatent (#129) für den Verfeinerungsdurchgang wieder zusammengeführt.
Sampler-Stufe 2 (2×)#
Der zweite Durchgang verfeinert das hochskalierte Latent mithilfe von RandomNoise (#127), KSamplerSelect (#145) und einem ManualSigmas-Zeitplan (#113) unter einem CFGGuider (#116). In dieser Stufe werden Mikrodetails und Kantenschärfe finalisiert. Es funktioniert am besten, wenn das LoRA aktiv ist und die Eingabe spezifisch über Texturen und Beleuchtung ist.
Dekodieren und Ausgabe#
LTXVSeparateAVLatent (#135) trennt das verfeinerte Latent, sodass VAEDecodeTiled (#137) Frames rekonstruieren kann, während LTXVAudioVAEDecode (#138) Audio wiederherstellt. CreateVideo (#133) muxed Frames und Audio bei der gewählten FPS, und der oberste SaveVideo Knoten schreibt ein MP4 in den Videoordner des Workflows. Das Ergebnis ist eine saubere, teilbare Datei, die vollständig innerhalb der LTX 2.3 ComfyUI-Pipeline produziert wurde.
Wichtige Knoten im Comfyui LTX 2.3 ComfyUI-Workflow#
TextGenerateLTX2Prompt(#149): Wandelt einfache Beschreibungen in strukturierte Eingaben um, die Bewegung, visuelle Attribute und Audio abdecken. Passen Sie Ihre Formulierungen hier zuerst an, wenn Sie Story-Elemente oder Tempo steuern möchten; es bringt normalerweise größere Gewinne als Sampler-Anpassungen.LTXVScheduler(#112): Ein LTX-spezifischer Scheduler, der formt, wie Rauschen im Laufe der Zeit entfernt wird. Kombinieren Sie ihn durchdacht mit Ihrem gewählten Sampler, um zeitliche Stabilität und Eingabegenauigkeit auszugleichen.LTXVLatentUpsampler(#130): Führt ein 2× räumliches Upscale direkt im latenten Raum durch, bewahrt Bewegungskontinuität bei und fügt scharfe Details hinzu. Verwenden Sie ihn, wenn Sie schärfere Ergebnisse wünschen, ohne auf Post-Dekodier-Upscaler zurückzugreifen.LoraLoaderModelOnly(#143): Wendet das LTX‑2.3 destillierte LoRA zur Verfeinerung an. Erhöhen Sie den Einfluss für eine engere Stilkontrolle; reduzieren Sie ihn, wenn Sie den breiteren Look des Basismodells wünschen.CreateVideo(#133): Muxed dekodierte Frames mit generiertem Audio bei der ausgewählten FPS, sodass Timing und Lippensynchronisation intakt bleiben. Wenn Sie die FPS ändern, halten Sie beide Bildratensteuerungen übereinstimmend.
Optionale Extras#
- Eingabe-Tipps: Beschreiben Sie Aktionen über die Zeit, listen Sie Schlüsselaspekte auf und spezifizieren Sie erwartete Geräusche oder Dialoge. Klare, prägnante Formulierungen geben dem LTX‑2.3 Encoder das beste Signal.
- Dimensionen und Länge: Bevorzugen Sie Größen auf einem 32-Schritt und Längen, die die Bildfrequenz des Modells respektieren. Obwohl der Graph automatisch nahe Werte anpasst, verbessern gültige Eingaben die Komposition und reduzieren subtile Unruhe.
- Schnelle Iteration: Ändern Sie den
RandomNoise-Seed zwischen den Durchläufen, um Varianten zu erkunden, während Sie dieselbe Eingabe und Einstellungen beibehalten. - Modellwechsel: Die Standardeinstellungen sind auf LTX‑2.3 22B mit Gemma 3 12B IT und den 2× räumlichen Upscaler abgestimmt. Wechseln Sie Modelle nur, wenn Sie verstehen, wie sich jedes auf die Konditionierung und Dekodierung auswirkt.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Lightricks für das LTX-2.3 Modell und EyeForAILabs für das YouTube-Tutorial für ihre Beiträge und Wartung. Für maßgebliche Details verweisen wir auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: 2601.03233
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: YouTube Channel from @eyeforailabs
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen ihrer Autoren und Betreuer.


