
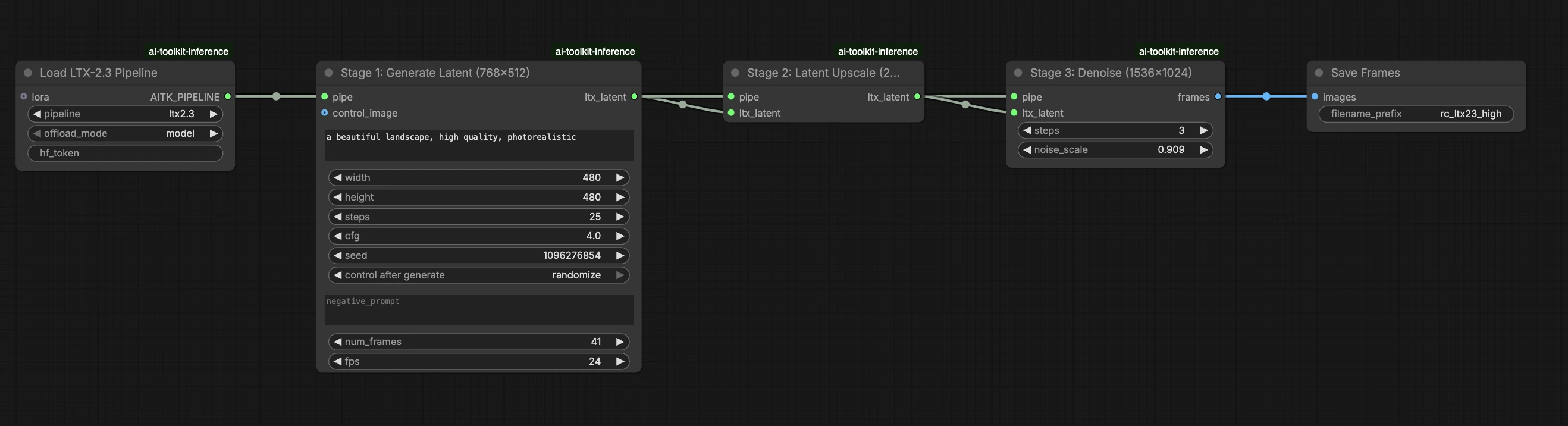
LTX 2.3 LoRA ComfyUI 推理:使用 LTX 2.3 流程的訓練匹配 AI Toolkit LoRA 輸出#
這個即時運行的 RunComfy 工作流程通過 RC LTX 2.3 (LTX2Pipeline) (流程級別對齊,而不是通用取樣器圖) 在 ComfyUI 中運行 LTX 2.3 LoRA 推理。RunComfy 構建並開源了這個自訂節點——請參見 runcomfy-com repositories——並且您可以通過 lora_path 和 lora_scale 控制適配器應用。
注意:此工作流程需要 2X Large 或更大的機器運行。
為什麼 LTX 2.3 LoRA ComfyUI 推理在 ComfyUI 中看起來經常不同#
AI Toolkit 訓練預覽是通過模型專用的 LTX 2.3 流程渲染的,其中文本編碼、調度和 LoRA 注入設計為協同工作。在 ComfyUI 中,使用不同的圖(或不同的 LoRA 加載路徑)重建 LTX 2.3 可以改變這些交互,因此即使複製相同的提示、步驟、CFG 和種子,仍然會產生可見的漂移。RunComfy RC 流程節點通過在 LTX2Pipeline 中從頭到尾執行 LTX 2.3 並在該流程中應用您的 LoRA,從而縮小了這一差距,保持推理與預覽行為一致。來源:RunComfy 開源倉庫。
如何使用 LTX 2.3 LoRA ComfyUI 推理工作流程#
步驟 1:獲取 LoRA 路徑並將其加載到工作流程中(2 種選擇)#
選擇 A — RunComfy 訓練結果 → 下載到本地 ComfyUI:
- 轉到 Trainer → LoRA Assets
- 找到您要使用的 LoRA
- 點擊右側的 ⋮ (三點) 菜單 → 選擇 複製 LoRA 連結
- 在 ComfyUI 工作流程頁面,將複製的連結粘貼到 UI 右上角的 下載 輸入框中
- 在點擊下載之前,確保目標文件夾設置為 ComfyUI > models > loras (此文件夾必須選為下載目標)
- 點擊 下載 — 這確保 LoRA 文件保存到正確的
models/loras目錄中 - 下載完成後,刷新頁面
- LoRA 現在出現在工作流程中的 LoRA 選擇下拉框 中 — 選擇它
選擇 B — 直接 LoRA URL(覆蓋選擇 A):
- 將 直接
.safetensors下載 URL 粘貼到 LoRA 節點 的path / url輸入框中 - 當此處提供 URL 時,它會 覆蓋選擇 A — 工作流程會在運行時直接從 URL 加載 LoRA
- 無需本地下載或文件放置
提示:確認 URL 解析為實際的 .safetensors 文件(而不是登陸頁面或重定向)。
步驟 2:將推理參數與您的訓練樣本設置匹配#
在 LoRA 節點中,選擇您的適配器在 lora_path (選擇 A),或將直接 .safetensors 連結粘貼到 path / url (選擇 B 覆蓋下拉框)。然後將 lora_scale 設置為您在訓練預覽中使用的相同強度,並從那裡調整。
其餘參數位於 生成 節點上(以及視圖中的 加載流程 節點上):
prompt:您的文本提示(如果您在訓練時使用觸發詞,請包括它們)width/height:輸出分辨率;匹配您的訓練預覽尺寸以獲得最清晰的比較(建議 LTX 2.3 使用 32 的倍數)num_frames:輸出視頻幀數sample_steps:推理步驟數(30 是常見的默認值)guidance_scale:CFG/引導值(5.5 是常見的默認值;不要超過 7)seed:固定種子以重現;更改它以探索變化seed_mode(僅在存在時):選擇fixed或randomizeframe_rate:輸出幀率;保持與訓練設置一致以實現運動對齊
訓練對齊提示:如果您在訓練期間自定義了取樣值(seed、guidance_scale、sample_steps、觸發詞、分辨率),請在此鏡像這些確切的值。如果您在 RunComfy 上進行訓練,請打開 Trainer → LoRA Assets > 配置以查看解析的 YAML 並將預覽/樣本設置複製到工作流程節點中。
步驟 3:運行 LTX 2.3 LoRA ComfyUI 推理#
點擊 Queue/Run — SaveVideo 節點將結果寫入您的 ComfyUI 輸出文件夾。
快速檢查表:
- ✓ LoRA 是:下載到
ComfyUI/models/loras(選擇 A),或通過直接.safetensorsURL 加載 (選擇 B) - ✓ 本地下載後刷新頁面(僅選擇 A)
- ✓ 推理參數與訓練
sample配置匹配(如果自定義)
如果以上所有內容正確,則此處的推理結果應該與您的訓練預覽非常接近。
LTX 2.3 LoRA ComfyUI 推理的故障排除#
大多數 LTX 2.3 "訓練預覽與 ComfyUI 推理" 差距來自 流程級別差異(模型如何加載、調度以及 LoRA 如何合併),而不是來自單個錯誤旋鈕。 這個 RunComfy 工作流程通過在 RC LTX 2.3 (LTX2Pipeline) 中從頭到尾運行推理並通過 lora_path / lora_scale 在該流程中應用您的 LoRA (而不是堆疊通用加載器/取樣器節點) 來恢復最接近的 "訓練匹配" 基線。
(1) LoRA 形狀不匹配或 "key not loaded" 警告#
為什麼會發生 LoRA 是為不同的模型系列或不同的 LTX 變體訓練的。您將看到許多 lora key not loaded 行,並可能出現形狀不匹配錯誤。
如何解決(推薦)
- 確保 LoRA 是專門為 LTX 2.3 與 AI Toolkit 訓練的 (LTX 2.0 / 2.1 / 2.2 LoRA 不能互換)。
- 保持圖形 "單一路徑" 用於 LoRA:僅通過工作流程的
lora_path輸入加載適配器,並讓 LTX2Pipeline 處理合併。不要並行堆疊額外的通用 LoRA 加載器。 - 如果您已經遇到不匹配並且 ComfyUI 隨後開始產生不相關的 CUDA/OOM 錯誤,請 重啟 ComfyUI 過程 以完全重置 GPU + 模型狀態,然後使用兼容的 LoRA 重試。
(2) 推理結果與訓練預覽不匹配#
為什麼會發生 即使 LoRA 加載,結果仍可能漂移,如果您的 ComfyUI 圖形與訓練預覽流程不匹配(不同的默認值、不同的 LoRA 注入路徑、不同的調度)。
如何解決(推薦)
- 使用此工作流程並將您的直接
.safetensors連結粘貼到lora_path。 - 從您的 AI Toolkit 訓練配置(或 RunComfy Trainer → LoRA Assets 配置)中複製取樣值:
width、height、num_frames、sample_steps、guidance_scale、seed、frame_rate。 - 除非您在訓練/取樣時使用它們,否則不要在比較中加入 "額外速度堆疊"。
(3) 使用 LoRAs 顯著增加推理時間#
為什麼會發生 當 LoRA 路徑強制額外的修補/去量化工作或在比僅基礎模型更慢的代碼路徑中應用權重時,LoRA 可能使 LTX 2.3 慢得多。
如何解決(推薦)
- 使用此工作流程的 RC LTX 2.3 (LTX2Pipeline) 路徑,並通過
lora_path/lora_scale傳遞您的適配器。在此設置中,LoRA 在 流程加載期間合併一次(AI Toolkit 樣式),因此 每步取樣成本 保持接近基礎模型。 - 當您追求預覽匹配行為時,避免堆疊多個 LoRA 加載器或混合加載路徑。保持為 一個
lora_path+ 一個lora_scale直到基線匹配。
(4) 大分辨率或長視頻的 OOM 錯誤#
為什麼會發生 LTX 2.3 是一個 22B 參數模型,視頻生成對 VRAM 要求很高。高分辨率或許多幀可能超過 GPU 記憶體,特別是與 LoRA 開銷一起。
如何解決(推薦)
- 使用 2X Large (80 GB VRAM) 或更大的機器。此工作流程不兼容 Medium、Large 或 X Large 機器。
- 如果您需要快速迭代,請減少分辨率或幀數,然後在最終渲染時放大。
- 如果可用,啟用 VAE 瓦片化——這可以節省約 3 GB VRAM,質量損失最小。
現在運行 LTX 2.3 LoRA ComfyUI 推理#
打開工作流程,設置 lora_path,然後點擊 Queue/Run 以獲得接近您 AI Toolkit 訓練預覽的 LTX 2.3 LoRA 結果。