
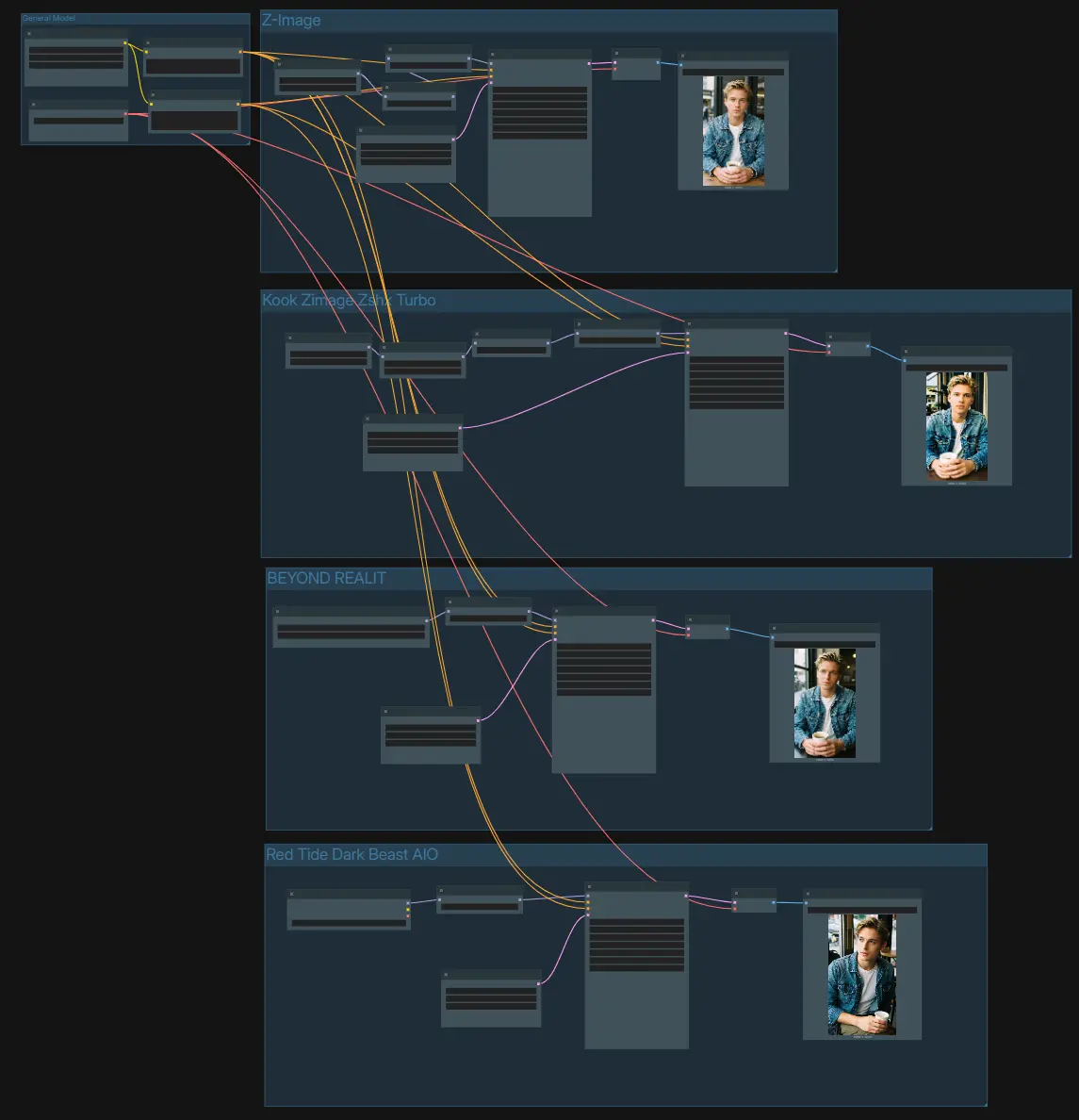





Z-Image 精调模型:在 ComfyUI 中进行多风格、高质量图像生成#
此工作流程将 Z-Image-Turbo 和一组旋转的 Z-Image 精调模型组合成一个单一的、生产就绪的 ComfyUI 图形。其设计目的是并排比较风格,保持提示行为一致,并在最少步骤内产生清晰、连贯的结果。它结合了优化的 UNet 加载、CFG 归一化、AuraFlow 兼容采样和可选的 LoRA 注入,因此您可以探索现实主义、电影肖像、暗黑幻想和动漫风格外观,而无需重新连接画布。
Z-Image 精调模型非常适合希望快速评估多个检查点和 LoRA 的艺术家、提示工程师和模型探索者,同时保持在一个一致的管道内。输入一个提示,从不同的 Z-Image 精调模型中渲染四种变体,并快速锁定最符合您要求的风格。
Comfyui Z-Image 精调模型工作流程中的关键模型#
- Tongyi-MAI Z-Image-Turbo。一个 6B 参数的单流扩散变换器,经过蒸馏以实现少步、逼真的文本到图像转换,具有强大的指令遵从性和双语文本渲染。官方权重和使用说明在模型卡上,技术报告和蒸馏方法详见 arXiv 和项目仓库。Model • Paper • Decoupled-DMD • DMDR • GitHub • Diffusers pipeline
- BEYOND REALITY Z-Image(社区精调)。一个倾向于真实感的 Z-Image 检查点,强调光泽纹理、清晰边缘和风格化的完成,适合肖像和产品类构图。Model
- Z-Image-Turbo-Realism LoRA(此工作流程的 LoRA 通道中的示例 LoRA)。一个轻量级的适配器,推动超现实渲染,同时保持基础 Z-Image-Turbo 提示对齐;无需替换基础模型即可加载。Model
- AuraFlow 家族(采样兼容参考)。工作流程使用 AuraFlow 风格的采样钩子进行稳定的少步生成;有关 AuraFlow 调度器及其设计目标的背景,请参见管道参考。Docs
如何使用 Comfyui Z-Image 精调模型工作流程#
该图形组织为四个独立的生成通道,共享一个公共文本编码器和 VAE。使用一个提示来驱动所有通道,然后比较从每个分支保存的结果。
- 通用模型
- 共享设置加载文本编码器和 VAE。在正面
CLIPTextEncode(#75) 中输入您的描述,并在负面CLIPTextEncode(#74) 中添加可选约束。这确保了各分支间的条件相同,以便您可以公平地判断每个精调模型的表现。VAELoader(#21) 提供了所有通道用于将潜在变量转回图像的解码器。
- 共享设置加载文本编码器和 VAE。在正面
- Z-Image(基础 Turbo)
- 此通道通过
UNETLoader(#100) 运行官方 Z-Image-Turbo UNet,并通过ModelSamplingAuraFlow(#76) 为少步稳定性打补丁。CFGNorm(#67) 标准化无分类指导行为,以便采样器的对比度和细节在提示间保持可预测性。一个EmptyLatentImage(#19) 定义了画布大小,然后KSampler(#78) 生成潜在变量,这些变量由VAEDecode(#79) 解码并由SaveImage(#102) 写入。使用此分支作为评估其他 Z-Image 精调模型时的基线。
- 此通道通过
- Z-Image-Turbo + Realism LoRA
- 此通道在基础
UNETLoader(#82) 之上通过LoraLoaderModelOnly(#106) 注入风格适配器。ModelSamplingAuraFlow(#84) 和CFGNorm(#64) 保持输出清晰,同时 LoRA 推动现实主义而不压倒主题。使用EmptyLatentImage(#71) 定义分辨率,用KSampler(#85) 生成,通过VAEDecode(#86) 解码,并使用SaveImage(#103) 保存。如果 LoRA 感觉太强,可以在此处减轻其权重,而不是过度编辑您的提示。
- 此通道在基础
- BEYOND REALITY 精调
- 此路径通过
UNETLoader(#88) 引入一个社区检查点,以提供风格化的高对比度外观。CFGNorm(#66) 驯服指导,使视觉签名在更改采样器或步骤时保持清晰。设置目标大小在EmptyLatentImage(#72),用KSampler(#89) 渲染,通过VAEDecode(#90) 解码,并通过SaveImage(#104) 保存。使用与基础通道相同的提示,查看此精调如何解释构图和照明。
- 此路径通过
- Red Tide Dark Beast AIO 精调
- 一个以暗黑幻想为导向的检查点通过
CheckpointLoaderSimple(#92) 加载,然后由CFGNorm(#65) 归一化。此通道倾向于阴郁的色调和更重的微对比,同时保持良好的提示合规性。选择您的框架在EmptyLatentImage(#73),用KSampler(#93) 生成,通过VAEDecode(#94) 解码,并从SaveImage(#105) 导出。这是一种在相同 Z-Image 精调模型设置中测试更粗犷美学的实用方法。
- 一个以暗黑幻想为导向的检查点通过
Comfyui Z-Image 精调模型工作流程中的关键节点#
ModelSamplingAuraFlow(#76, #84)- 目的:为模型打补丁以使用在非常低步数下稳定的 AuraFlow 兼容采样路径。
shift控件微调采样轨迹;将其视为一个微调拨盘,与您的采样器选择和步数预算互动。为了在各通道之间获得最佳可比性,保持相同的采样器,仅在每次测试中调整一个变量(例如,shift或 LoRA 权重)。参考:AuraFlow 管道背景和调度说明。Docs
- 目的:为模型打补丁以使用在非常低步数下稳定的 AuraFlow 兼容采样路径。
CFGNorm(#64, #65, #66, #67)- 目的:标准化无分类指导,以便在更改模型、步骤或调度器时对比度和细节不会大幅波动。如果高光洗出或纹理在通道之间感到不一致,则增加其
strength;如果图像开始看起来过于压缩,则减少它。当您想要对 Z-Image 精调模型进行干净的 A/B 测试时,请在各分支之间保持相似。
- 目的:标准化无分类指导,以便在更改模型、步骤或调度器时对比度和细节不会大幅波动。如果高光洗出或纹理在通道之间感到不一致,则增加其
LoraLoaderModelOnly(#106)- 目的:直接将 LoRA 适配器注入加载的 UNet 中,而不改变基础检查点。
strength参数控制风格影响;较低的值保留基础现实主义,而较高的值则施加 LoRA 的外观。如果 LoRA 力压面部或排版,首先减少其权重,然后微调提示措辞。
- 目的:直接将 LoRA 适配器注入加载的 UNet 中,而不改变基础检查点。
KSampler(#78, #85, #89, #93)- 目的:运行实际的扩散循环。选择一个与少步蒸馏相配的采样器和调度器;许多用户更喜欢 Euler 风格的采样器与统一或多步调度器用于 Turbo 类模型。在比较通道时保持种子固定,仅一次更改一个变量,以了解每个精调的表现。
可选附加项#
- 从一个描述性段落风格的提示开始,并在所有通道中重复使用它,以判断 Z-Image 精调模型之间的差异;仅在选择一个最喜欢的分支后才迭代风格词。
- 对于 Turbo 类模型,极低或甚至零 CFG 通常会产生最干净的结果;仅在必须排除特定元素时使用负面提示。
- 在进行 A/B 测试时保持相同的分辨率、采样器和种子;在小增量中更改 LoRA 权重或
shift以隔离原因和效果。 - 每个分支写入各自的输出;四个
SaveImage节点各自标记,以便您可以快速比较和策展。
进一步阅读的链接:
- Z-Image-Turbo 模型卡:Tongyi-MAI/Z-Image-Turbo
- 技术报告和方法:Z-Image • Decoupled-DMD • DMDR
- 项目仓库:Tongyi-MAI/Z-Image
- 示例精调:Nurburgring/BEYOND_REALITY_Z_IMAGE
- 示例 LoRA:Z-Image-Turbo-Realism-LoRA
致谢#
此工作流程实现并建立在以下作品和资源的基础上。我们对 HuggingFace 模型为本文的贡献和维护表示衷心感谢。有关权威详细信息,请参考下文链接的原始文档和存储库。
资源#
- HuggingFace 模型:
注意:所引用的模型、数据集和代码的使用受其作者和维护者提供的相应许可证和条款的约束。


