
Stable Audio Open 1.0 Текст-в-Музыку Рабочий процесс#
Этот рабочий процесс преобразует простой текст в оригинальную музыку и звуковые ландшафты, используя Stable Audio Open 1.0. Он разработан для композиторов, звуковых дизайнеров и создателей, которые хотят быструю, управляемую генерацию аудио, не покидая ComfyUI. Вы пишете подсказку, устанавливаете целевую продолжительность, и график рендерит MP3, который отражает ваш стиль, настроение, темп и инструментовку.
Под капотом рабочий процесс кодирует ваш текст с помощью текстового энкодера на основе T5, запускает процесс диффузии Stable Audio в латентном аудиопространстве, затем декодирует в звуковую волну и сохраняет результат. С четким руководством по подсказкам и простым контролем длины генерация Stable Audio становится предсказуемой и повторяемой для кинематографических, атмосферных или экспериментальных треков.
Ключевые модели в Comfyui Stable Audio рабочем процессе#
- Stable Audio Open 1.0. Открытая модель латентной диффузии для текст-в-музыку и звукового дизайна от Stability AI. Она мапирует намерение текста на аудио латенты и поддерживает различные музыкальные стили и структуры. Repository • Weights
- T5-Base Text Encoder. Общего назначения текстовая модель, используемая здесь для встраивания подсказок для кондиционирования генерации Stable Audio. Четкие, описательные входные данные ведут к более стабильной музыке. Model card
Как использовать Comfyui Stable Audio рабочий процесс#
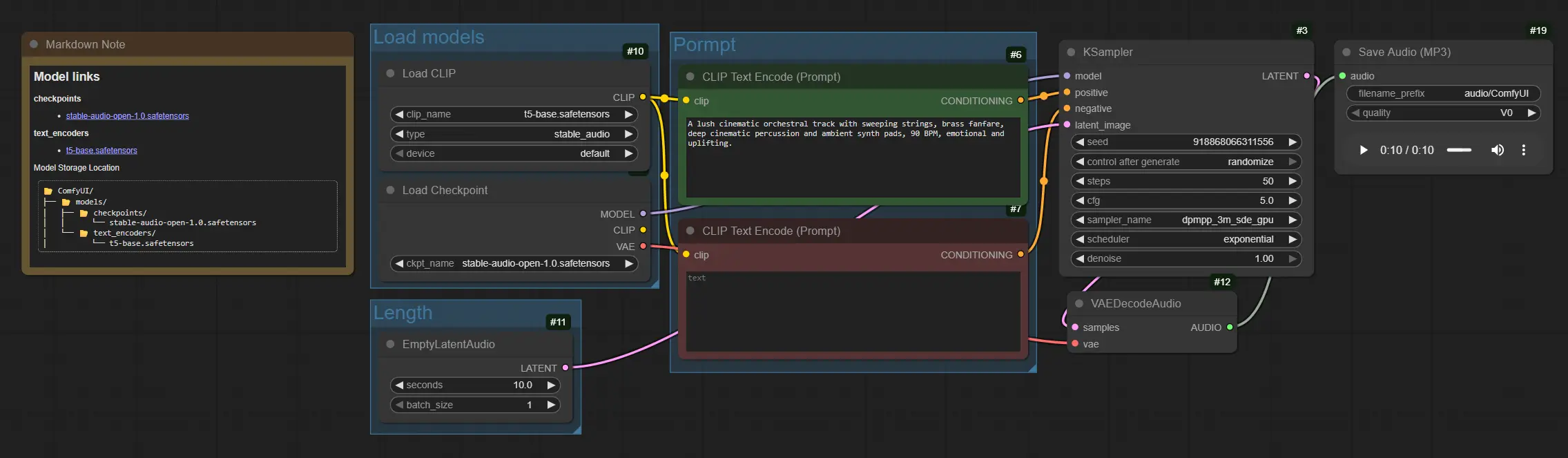
График течет от загрузки модели к кондиционированию подсказок, затем к семплингу, декодированию и сохранению. Группы организованы так, чтобы вы могли установить модели один раз, настроить длину, написать вашу подсказку и рендерить.
Загрузка моделей#
Эта группа инициализирует основные активы. CheckpointLoaderSimple (#4) загружает контрольную точку Stable Audio Open 1.0, которая включает в себя модель диффузии и ее аудио VAE. CLIPLoader (#10) загружает текстовый энкодер на основе T5, используемый для кондиционирования. После загрузки эти модели обеспечивают основы для генерации Stable Audio и остаются резидентными для последующих запусков.
Длина#
Эта группа определяет, как долго будет ваше аудио. EmptyLatentAudio (#11) создает пустой латентный трек с выбранной вами продолжительностью, чтобы семплер знал, сколько кадров генерировать. Более длинные клипы требуют больше времени и памяти, поэтому начните с умеренных значений, а затем масштабируйте. Вы также можете создать несколько вариаций, увеличив размер пакета при изучении идей.
Подсказка#
Эта группа преобразует текст в сигналы руководства для процесса диффузии. Используйте CLIPTextEncode (#6), чтобы написать положительную подсказку с инструментами, жанром, настроением, темпом и производственными подсказками, например: "lush cinematic orchestra, sweeping strings and brass, deep percussion, ambient pads, 90 BPM, uplifting." Используйте CLIPTextEncode (#7) для отрицательной подсказки, чтобы подавить артефакты, такие как "harsh noise, clipping, distortion." Вместе они направляют Stable Audio к текстурам и структурам, которые вам нужны.
Генерация и экспорт#
KSampler (#3) выполняет шаги диффузии, которые преобразуют пустой латент в музыкальный латент, управляемый вашими текстовыми кодировками. VAEDecodeAudio (#12) конвертирует латентное аудио обратно в звуковую волну. Наконец, SaveAudioMP3 (#19) записывает MP3 файл, чтобы вы могли просмотреть или сразу же добавить его в вашу временную шкалу. Для итеративной работы измените префикс имени файла, чтобы сохранять версии организованными.
Ключевые узлы в Comfyui Stable Audio рабочем процессе#
CLIPTextEncode(#6) Этот узел кодирует вашу положительную подсказку в кондиционирование, которому следует Stable Audio. Приоритет отдавайте четким спискам инструментов, жанру, настроению, темпу или BPM, а также производственным терминам, таким как "warm," "lo-fi," "cinematic," или "ambient." Незначительные изменения в формулировке могут значительно изменить композицию. См. основные узлы ComfyUI для общего поведения. ComfyUICLIPTextEncode(#7) Отрицательная подсказка помогает избежать нежелательных тембров или проблем с миксом. Добавьте термины, которые описывают, что удалить, например "screechy, metallic ringing, glitch pops, radio hiss." Краткость часто приводит к более чистым рендерам Stable Audio. ComfyUIEmptyLatentAudio(#11) Управляет продолжительностью клипа в секундах и, при необходимости, количеством пакетов для нескольких вариаций. Увеличьте секунды для более длинных произведений, учитывая, что вычисления масштабируются с длиной. Используйте пакетную генерацию, чтобы прослушать несколько версий Stable Audio из одной подсказки. ComfyUIKSampler(#3) Управляет процессом диффузии для аудио латентов. Наиболее влиятельные элементы управления - этоsteps,sampler,cfgиseed. Повышайтеstepsдля более детализированных деталей, настраивайтеcfgдля балансировки приверженности подсказке с креативностью и устанавливайте фиксированныйseed, чтобы воспроизвести версию или варьировать ее для новых идей. Обратитесь к заметкам семплера ComfyUI для общего руководства. ComfyUISaveAudioMP3(#19) Экспортирует финальную звуковую волну в MP3. Используйтеfilename_prefix, чтобы метить версии и держать итерации в порядке. При сравнении подсказок или семян, сохранение нескольких версий рядом делает выбор Stable Audio быстрее. ComfyUI
Дополнительные советы#
- Пишите подсказки как брифинг сессии: инструменты, жанр, настроение, темп или BPM и прилагательные для микса.
- Используйте короткие, сфокусированные отрицательные подсказки, чтобы уменьшить шипение, резкость или нежелательные инструменты.
- Закрепите
seedпри итерации текста, затем изменитеseed, чтобы исследовать новые вариации Stable Audio. - Начните с более коротких продолжительностей, чтобы настроить стиль, затем увеличивайте, когда звук будет правильным.
- Держите постоянный префикс имени файла для каждой концепции, чтобы вы могли сравнивать версии Stable Audio позже.
Ресурсы для более глубокого изучения: детали модели Stable Audio и примеры здесь, основные узлы и поведение в ComfyUI здесь, и модельная карточка T5-Base здесь.
Признания#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы благодарно признаем Stability AI за Stable Audio Open, comfyanonymous (ComfyUI) за узлы ComfyUI и рабочие процессы, а также Comfy-Org и ComfyUI-Wiki за контрольную точку Stable Audio Open 1.0 и текстовый энкодер T5-Base за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- Comfy-Org/Stable Audio Open 1.0 рабочий процесс
- GitHub: Stability-AI/stable-audio-open
Примечание: Использование упомянутых моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.
