
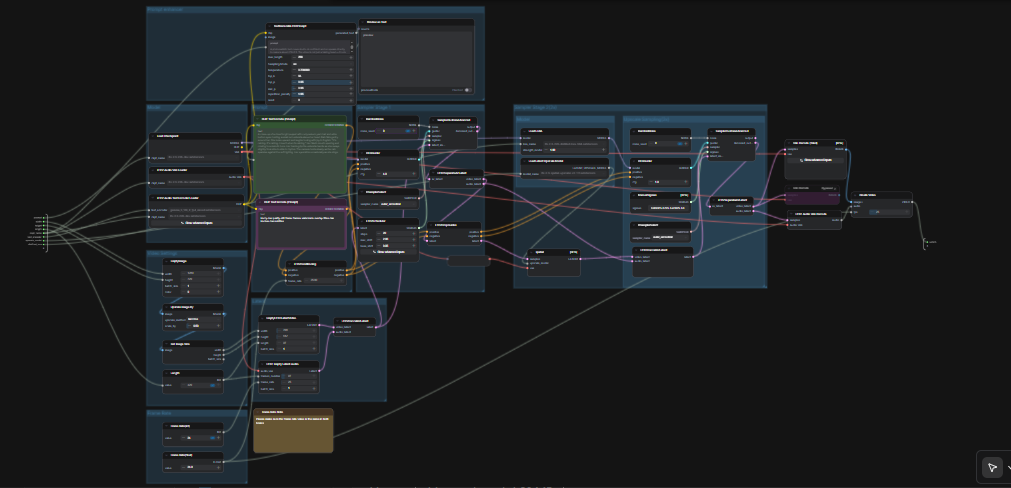
LTX 2.3 ComfyUI: Text‑to‑Video с чистым звуком, двухэтапной выборкой и 2× пространственным увеличением#
Этот рабочий процесс LTX 2.3 ComfyUI превращает короткие подсказки в отполированное, кинематографическое видео с синхронизированным звуком. Он основан на модели Lightricks’ LTX‑2.3 и настроен для высокой визуальной согласованности, стабильного движения и выхода, подходящего для трансляции. Создатели, редакторы и технические художники могут перейти от одной подсказки к MP4 с звуком за один проход, используя упрощенный граф, который включает усилитель подсказок, два этапа выборки и 2× латентное увеличение.
По сравнению с типичными настройками text‑to‑video, этот граф акцентирует внимание на согласованности сцены и точности подсказок. Путь по умолчанию создает AV латент, увеличивает его в латентном пространстве для более четких деталей, затем декодирует в кадры и аудио, прежде чем упаковать всё в готовый к распространению видеофайл. Если вы изучаете современные open‑source видеомодели, этот рабочий процесс LTX 2.3 ComfyUI — это быстрый способ получить производственное качество движения.
Ключевые модели в рабочем процессе Comfyui LTX 2.3 ComfyUI#
- Контрольная точка LTX‑2.3 22B (dev) от Lightricks. Основная модель text‑to‑video, которая обеспечивает высокую согласованность движения и сильную согласованность сцены. Hugging Face • GitHub
- Текстовый энкодер Gemma 3 12B Instruct (FP4 mixed). Обеспечивает надежное понимание языка для лучшего обоснования подсказок и более богатых деталей сцены. Hugging Face
- LTX‑2.3 Spatial Upscaler x2 1.0. Латентное пространство увеличения, которое улучшает пространственные детали без нарушения согласованности движения. Hugging Face
- LTX‑2.3 22B Distilled LoRA (384). Дистиллированный адаптер, который улучшает текстурную точность и стабилизирует стиль в процессе увеличения/улучшения. Hugging Face
- LTX Audio VAE. Аудиомодуль, соединенный с LTX‑2.3, который позволяет создавать чистый, синхронизированный звук из той же подсказки. Hugging Face
Как использовать рабочий процесс Comfyui LTX 2.3 ComfyUI#
Граф запускается в двух координированных проходах. Сначала он генерирует AV латент с рабочим разрешением с вашей подсказкой. Затем он выполняет 2× латентное увеличение и второй проход выборки с дистиллированным LoRA, прежде чем декодировать в кадры и аудио, в конечном итоге объединяя в MP4.
Усилитель подсказок#
Узел TextGenerateLTX2Prompt (#149) переписывает простой язык в модельно‑дружественную подсказку, которая охватывает действия, визуальные и аудиоподсказки. Подайте ему описание сцены; опциональные справочные изображения могут быть подключены, когда вы хотите получить руководство по кадрированию или стилю. Сгенерированный текст направляется в положительный энкодер, в то время как качественно ориентированная отрицательная подсказка снижает артефакты. Этот баланс помогает модели LTX‑2.3 оставаться в рамках задания, не ограничивая креативность.
Модель#
CheckpointLoaderSimple (#146) загружает контрольную точку LTX‑2.3 22B и предоставляет как модель, так и её VAE. LTXAVTextEncoderLoader (#147) подключает текстовый энкодер Gemma 3 12B Instruct, который используется в рабочем процессе как для положительного, так и для отрицательного кондиционирования. Сохраните эти выборы, если только вы не тестируете другие варианты LTX, так как остальная часть графа настроена для этой пары.
Настройки видео#
Разрешение и продолжительность устанавливаются с помощью легкого изображения и элемента управления Length. Граф считывает размер изображения, масштабирует его для рабочего разрешения и передает эти значения в создателя латентного видео. Модели LTX имеют ограничения по шагу; придерживайтесь размеров, соответствующих 32‑шаговому шаблону, и длительностей, которые согласуются с каденцией кадров модели. Граф плавно подстраивает недопустимые значения до ближайших допустимых, но выбор допустимых размеров с самого начала дает лучший композ.
Частота кадров#
Два небольших элемента управления устанавливают FPS как для кондиционирования, так и для окончательного кодирования: Frame Rate(int) (#141) и Frame Rate(float) (#140). Держите их идентичными, чтобы синхронизация движения и аудио оставалась согласованной по всей цепочке. Выберите кинематографическую частоту, если хотите более плавное движение, или следуйте платформенным стандартам при нацеливании на социальные форматы.
Латент#
EmptyLTXVLatentVideo (#121) инициализирует латентное видео, а LTXVEmptyLatentAudio (#119) делает то же самое для аудио. LTXVConcatAVLatent (#122) объединяет их в один AV латент, чтобы текстовая направляющая могла управлять обоими модальностями вместе. LTXVConditioning (#120) прикрепляет положительное и отрицательное кондиционирование, а LTXVCropGuides (#115) адаптирует руководство к пространственной компоновке латентного для более надежного кадрирования.
Этап выборки 1#
Этот этап создает начальный AV латент, используя RandomNoise (#151), KSamplerSelect (#144) и LTXVScheduler (#112) с CFGGuider (#139). Планировщик настроен для LTX, чтобы сбалансировать временную стабильность с соблюдением подсказок. Если вы хотите больше разнообразия, измените начальное значение шума; для более устойчивого соблюдения сценария, предпочтите выборки, которые поддерживают временную согласованность.
Модель (LoRA)#
LoraLoaderModelOnly (#143) применяет дистиллированный LoRA LTX‑2.3 перед улучшением. Этот адаптер тонко улучшает полировку текстур и точность стиля, не теряя согласованности движения. Это наиболее заметно на коже, ткани и зеркальных бликах.
Увеличение выборки (2×)#
LTXVLatentUpsampler (#130) выполняет 2× пространственное увеличение в латентном пространстве, используя загруженный LatentUpscaleModelLoader (#114) и базовый VAE. Поскольку увеличение происходит до декодирования, вы сохраняете временную плавность, получая при этом мелкие пространственные детали. Увеличенные видео и аудио латенты затем снова объединяются с LTXVConcatAVLatent (#129) для этапа улучшения.
Этап выборки 2 (2×)#
Второй проход уточняет увеличенный латент, используя RandomNoise (#127), KSamplerSelect (#145) и ManualSigmas (#113) под CFGGuider (#116). Этот этап, где микродетали и резкость краев окончательно уточняются. Он работает лучше всего, когда LoRA активен, и подсказка конкретна в отношении текстур и освещения.
Декодирование и вывод#
LTXVSeparateAVLatent (#135) разделяет уточненный латент, чтобы VAEDecodeTiled (#137) мог реконструировать кадры, а LTXVAudioVAEDecode (#138) восстанавливает аудио. CreateVideo (#133) объединяет кадры и аудио с выбранным FPS, а узел верхнего уровня SaveVideo записывает MP4 в папку видео рабочего процесса. Результат — чистый, готовый к распространению файл, полностью произведенный внутри конвейера LTX 2.3 ComfyUI.
Ключевые узлы в рабочем процессе Comfyui LTX 2.3 ComfyUI#
TextGenerateLTX2Prompt(#149): Преобразует простые описания в структурированные подсказки, охватывающие движение, визуальные атрибуты и аудио. Сначала измените формулировку здесь, когда управляете сюжетными линиями или ритмом; это обычно дает большие результаты, чем изменения выборки.LTXVScheduler(#112): Специфический для LTX планировщик, который определяет, как шум удаляется со временем. Используйте его вдумчиво с выбранной выборкой, чтобы сбалансировать временную стабильность и точность подсказок.LTXVLatentUpsampler(#130): Выполняет 2× пространственное увеличение непосредственно в латентном пространстве, сохраняя непрерывность движения и добавляя четкие детали. Используйте его, когда хотите получить более четкие результаты без использования постдекодеров увеличения.LoraLoaderModelOnly(#143): Применяет дистиллированный LoRA LTX‑2.3 для улучшения. Увеличьте влияние для более строгого контроля стиля; уменьшите его, если хотите более широкий вид базовой модели.CreateVideo(#133): Объединяет декодированные кадры с сгенерированным аудио на выбранном FPS, чтобы синхронизация и синхронизация губ оставались нетронутыми. Если вы изменяете FPS, держите оба элемента управления частотой кадров согласованными.
Дополнительные опции#
- Советы по подсказкам: Опишите действия во времени, перечислите ключевые визуальные элементы и укажите ожидаемый звук или диалог. Четкая, краткая формулировка дает энкодеру LTX‑2.3 лучший сигнал.
- Размеры и длина: Предпочитайте размеры с шагом 32 и длины, которые уважают каденцию кадров модели. Хотя граф автоматически подстраивает близкие значения, допустимые входные данные улучшают композицию и уменьшают незначительные дрожания.
- Быстрая итерация: Измените начальное значение
RandomNoiseмежду запусками, чтобы исследовать варианты, сохраняя ту же подсказку и настройки. - Переключение моделей: Значения по умолчанию настроены для LTX‑2.3 22B с Gemma 3 12B IT и 2× пространственным увеличителем. Меняйте модели только если вы понимаете, как каждая влияет на кондиционирование и декодирование.
Благодарности#
Этот рабочий процесс реализует и строится на следующих работах и ресурсах. Мы благодарны Lightricks за модель LTX-2.3 и EyeForAILabs за YouTube-учебник за их вклад и поддержку. Для получения авторитетных деталей, пожалуйста, обращайтесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: 2601.03233
- EyeForAILabs/YouTube Tutorial
- Документация / Примечания к выпуску: YouTube Channel from @eyeforailabs
Примечание: Использование упомянутых моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими организациями.

