
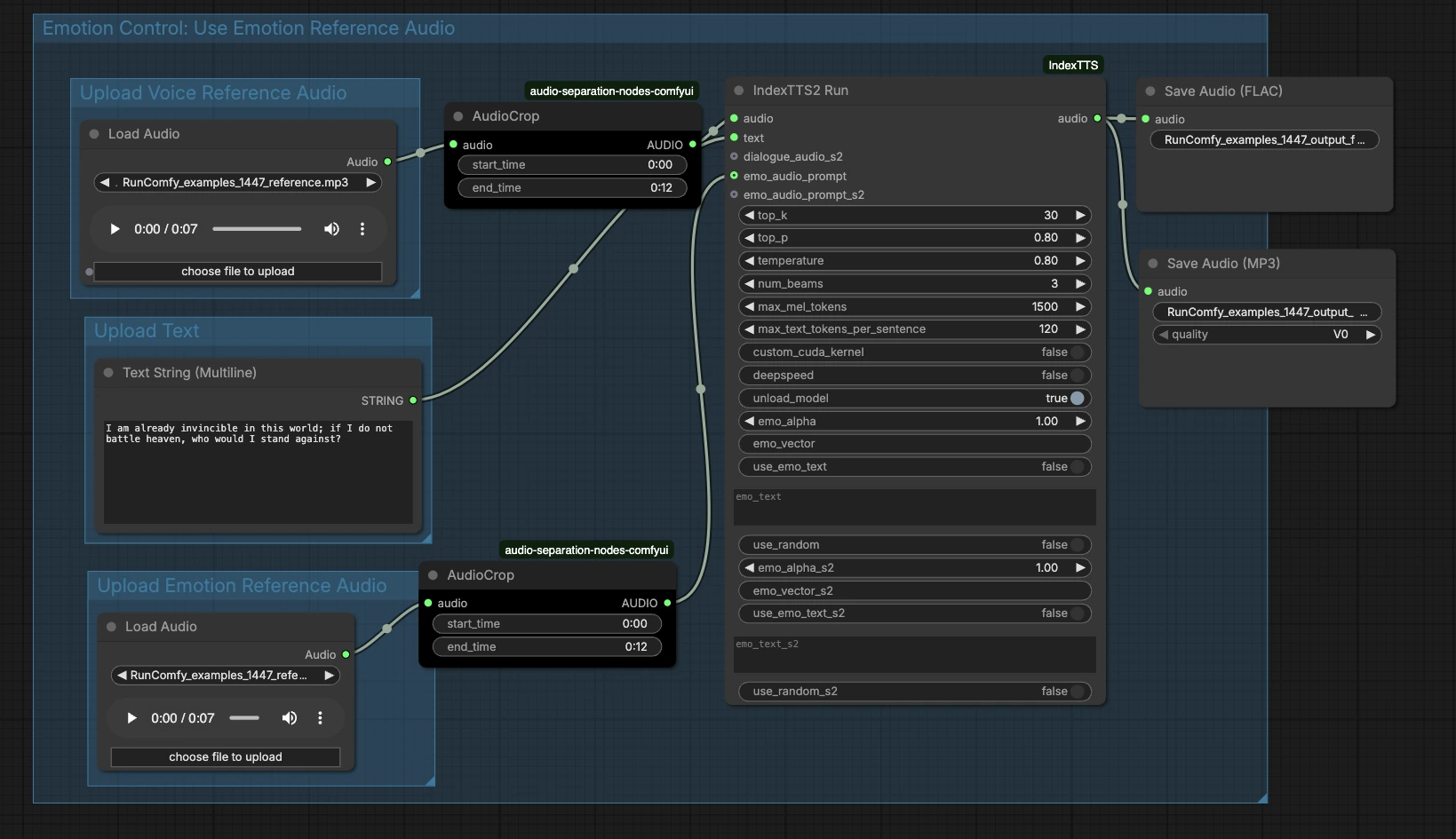
IndexTTS2 ComfyUI рабочий процесс: Эмоциональное клонирование голоса с использованием референсного аудио#
Этот рабочий процесс IndexTTS2 ComfyUI превращает короткий референсный клип в естественную, выразительную речь, соответствующую тембру и стилю говорящего. Вы предоставляете чистое референсное аудио, необязательные подсказки эмоций и ваш сценарий; график генерирует высококачественные голосовые клоны и экспортирует их в формате FLAC для архивного использования или MP3 для быстрого обмена.
Построенный вокруг модели IndexTTS‑2 и узлов ComfyUI IndexTTS, этот рабочий процесс идеально подходит для создателей, дизайнеров персонажей, педагогов и пользователей RunComfy, которые хотят быстрое, воспроизводимое эмоциональное TTS. Все происходит внутри ComfyUI, так что вы можете проверять входные данные, настраивать параметры и быстро повторять примеры повествования, диалога и озвучивания.
Ключевые модели в рабочем процессе Comfyui IndexTTS2 ComfyUI#
- IndexTTS‑2 от IndexTeam. Современная система текст-в-речь, выполняющая клонирование голоса с учетом референсов и контроль выразительности. Она условно ориентируется на короткий пример говорящего и, опционально, на эмоциональные подсказки для воспроизведения естественной речи из текста. См. карточку модели на Hugging Face и сопровождающую статью для получения деталей архитектуры и обучения: IndexTTS‑2, проект IndexTTS, статья IndexTTS‑2.
Как использовать рабочий процесс Comfyui IndexTTS2 ComfyUI#
На высоком уровне график принимает три входных данных — аудио тембра референса, текст и необязательное эмоциональное аудио — затем запускает генерацию и экспортирует результат. Группы ниже показывают, где добавить входные данные и как они связываются с конечной речью.
Загрузите аудио референса голоса#
Эта группа подготавливает идентичность говорящего. Загрузите чистый образец целевого голоса в LoadAudio (#13), желательно одного говорящего, говорящего четко без музыки или эффектов. Используйте AudioCrop (#37), чтобы изолировать стабильный сегмент, чтобы система научилась постоянному тембру. Короткие сегменты с устойчивым тоном и нейтральной подачей, как правило, обеспечивают наиболее надежное клонирование. Обрезанный референс отправляется вперед для кондиционирования генератора.
Загрузите текст#
Введите ваш сценарий в PrimitiveStringMultiline (#14). Четкая пунктуация помогает модели делать выводы о паузах и акцентах, так что пишите текст так, как вы хотите, чтобы он был произнесен. Если вы планируете много предложений, держите каждое предложение хорошо сформированным и избегайте эмодзи или редких символов. Текст напрямую поступает в узел синтеза для рендеринга.
Загрузите аудио референса эмоций#
Предоставьте необязательный клип, который захватывает эмоцию или подачу, которую вы хотите — например, возбуждение, спокойствие или мрачность — через LoadAudio (#15). Обрежьте его с помощью AudioCrop (#38), чтобы сохранить только ту выразительную часть, которую вы хотите имитировать. Это отдельно от референса тембра и фокусируется на ритме, энергии и тоне. Если вы пропустите этот шаг, рабочий процесс IndexTTS2 ComfyUI будет полагаться только на текст для произношения.
Контроль эмоций: Используйте аудио референса эмоций#
Эта область соединяет вашу подсказку эмоций с генератором. Обрезанный клип эмоций подает на вход emo_audio_prompt на IndexTTS2Run (#12), направляя каденцию и интенсивность, сохраняя при этом целевой голос. Вы также можете использовать текстовые контролы эмоций узла, чтобы направить стиль, если у вас нет примера аудио эмоций. На практике аудио эмоций, как правило, дает более сильную, более последовательную выразительность, в то время как текст эмоций обеспечивает легкое направление. Комбинируйте их, когда вы хотите как конкретный пример, так и текстовую подсказку.
Генерация и экспорт#
IndexTTS2Run (#12) синтезирует речь, используя ваш текст, референс тембра и любые указания по эмоциям. Выход направляется в SaveAudio (#17) для без потерь FLAC и в SaveAudioMP3 (#39) для небольшого, удобного для веба предпросмотра. Используйте поля имени файла на узлах сохранения, чтобы поддерживать организацию дублей при итерациях. Этот дизайн упрощает A/B тестирование различных текстов или эмоций, сохраняя ту же идентичность говорящего.
Ключевые узлы в рабочем процессе Comfyui IndexTTS2 ComfyUI#
IndexTTS2Run (#12)#
Это основной генератор, который оборачивает IndexTTS‑2 и предоставляет контролы для семплирования, поиска луча и кондиционирования эмоций. Настройте top_p, top_k и temperature, чтобы сбалансировать стабильность и разнообразие — более низкие значения дают более последовательные чтения, более высокие значения увеличивают спонтанность. Используйте num_beams, когда хотите, чтобы узел искал больше кандидатов на чтение, обменивая скорость на качество. Для длинных сценариев max_mel_tokens и max_text_tokens_per_sentence помогают предотвратить превышение, ограничивая размеры аудио и текстовых фрагментов. Эмоции можно управлять с помощью emo_audio_prompt, emo_alpha для силы смешивания или с помощью use_emo_text и emo_text, когда вы предпочитаете текстовую подсказку. Помощники по производительности, такие как deepspeed, custom_cuda_kernel и unload_model, доступны в зависимости от вашего оборудования. Реализация узла предоставляется настраиваемыми узлами ComfyUI IndexTTS: ComfyUI_IndexTTS, а основная модель задокументирована здесь: IndexTTS‑2, проект IndexTTS.
AudioCrop (#37) — референс тембра#
Используйте этот узел, чтобы изолировать чистый, устойчивый отрывок из вашего образца говорящего. Избегайте фонового шума, смеха или экстремальных эмоций, так как эти детали могут просочиться в клонированный голос. Обрезка до постоянного тона улучшает фиксацию идентичности и уменьшает нежелательные артефакты.
AudioCrop (#38) — подсказка эмоций#
Эта обрезка выбирает выразительную подсказку, которая контролирует подачу. Выберите часть с точным ритмом или интенсивностью, которую вы хотите, и держите её краткой, чтобы избежать размывания сигнала. Для лучшей согласованности используйте подсказки эмоций от того же говорящего, что и референс тембра, когда это возможно.
Дополнительные опции#
- Держите референсное аудио сухим и монофоническим; удалите реверберацию, фоновую музыку и сильную компрессию для более чистого клонирования.
- Пунктуируйте намеренно. Запятые, точки и вопросительные знаки помогают модели размещать паузы и интонации, которые соответствуют вашему намерению.
- Для воспроизводимых дублей отключите случайность в узле или ведите заметки о выборе текста и аудио, чтобы вы могли заново сгенерировать тот же вывод позже.
- Если VRAM ограничен, включите выгрузку модели между запусками; это может добавить небольшую временную стоимость, но освобождает память для других графиков.
- Уважайте права на голос. Используйте только те референсные записи, которые вы уполномочены клонировать, и раскрывайте синтетическую речь, где это требуется.
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы с благодарностью признаем RunningHub за референсный рабочий процесс, RunComfy за рабочий процесс Cloud Save, Index Team за IndexTTS и IndexTTS-2, авторов статьи IndexTTS2 и billwuhao за настраиваемые узлы ComfyUI IndexTTS за их вклад и поддержку. Для получения авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- RunningHub/Workflow Reference
- Документация / Примечания к выпуску: RunningHub пост
- RunComfy/Cloud Save Workflow
- Документация / Примечания к выпуску: RunComfy workflow
- index-tts/index-tts
- GitHub: index-tts/index-tts
- IndexTeam/IndexTTS-2
- Hugging Face: IndexTeam/IndexTTS-2
- IndexTTS2/Paper
- arXiv: 2506.21619
- billwuhao/ComfyUI_IndexTTS
- GitHub: billwuhao/ComfyUI_IndexTTS
Примечание: Использование упомянутых моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.