
Fish Audio S2 TTS для ComfyUI: высококачественный TTS, клонирование голоса и многоголосые диалоги#
Fish Audio S2 TTS — это готовый к использованию рабочий процесс ComfyUI, который превращает текст в естественную речь, клонирует голос из короткого эталонного клипа и генерирует многоголосые разговоры. Он работает на базе семейства Fish Audio S2-Pro и поддерживает богатое управление стилем с помощью тегов эмоций и прозодии, таких как [excited], [whisper] и [laughing].
Этот рабочий процесс идеально подходит для создателей, продуктовых команд и разработчиков, которые хотят иметь гибкий, выразительный синтез речи в ComfyUI. Он включает в себя опциональное преобразование речи в текст для быстрого захвата транскрипции, автоматическое обнаружение языка и несколько вариантов точности, включая fp8 и sage_attention для эффективного вывода.
Примечание: Запускайте этот рабочий процесс на машине типа 2X Large или больше. Более мелкие экземпляры могут столкнуться с нехваткой памяти (OOM).
Основные модели в рабочем процессе Comfyui Fish Audio S2 TTS#
- Fish Audio S2-Pro — основная генеративная модель синтеза текста в речь, используемая для одноголосого TTS, клонирования голоса и многоголосых диалогов. Она поддерживает обширные стилевые токены и многоязычный синтез model card и является частью проекта Fish-Speech repo.
- Fish Audio S2-Pro FP8 — вариант S2-Pro с эффективным использованием памяти, который снижает потребности в VRAM с минимальными потерями качества, рекомендуется для ограниченных GPU model card.
- OpenAI Whisper large-v3 — опциональная модель преобразования речи в текст, используемая для автоматической транскрипции вашего эталонного аудио при подготовке подсказок для клонирования голоса repo.
Как использовать рабочий процесс Comfyui Fish Audio S2 TTS#
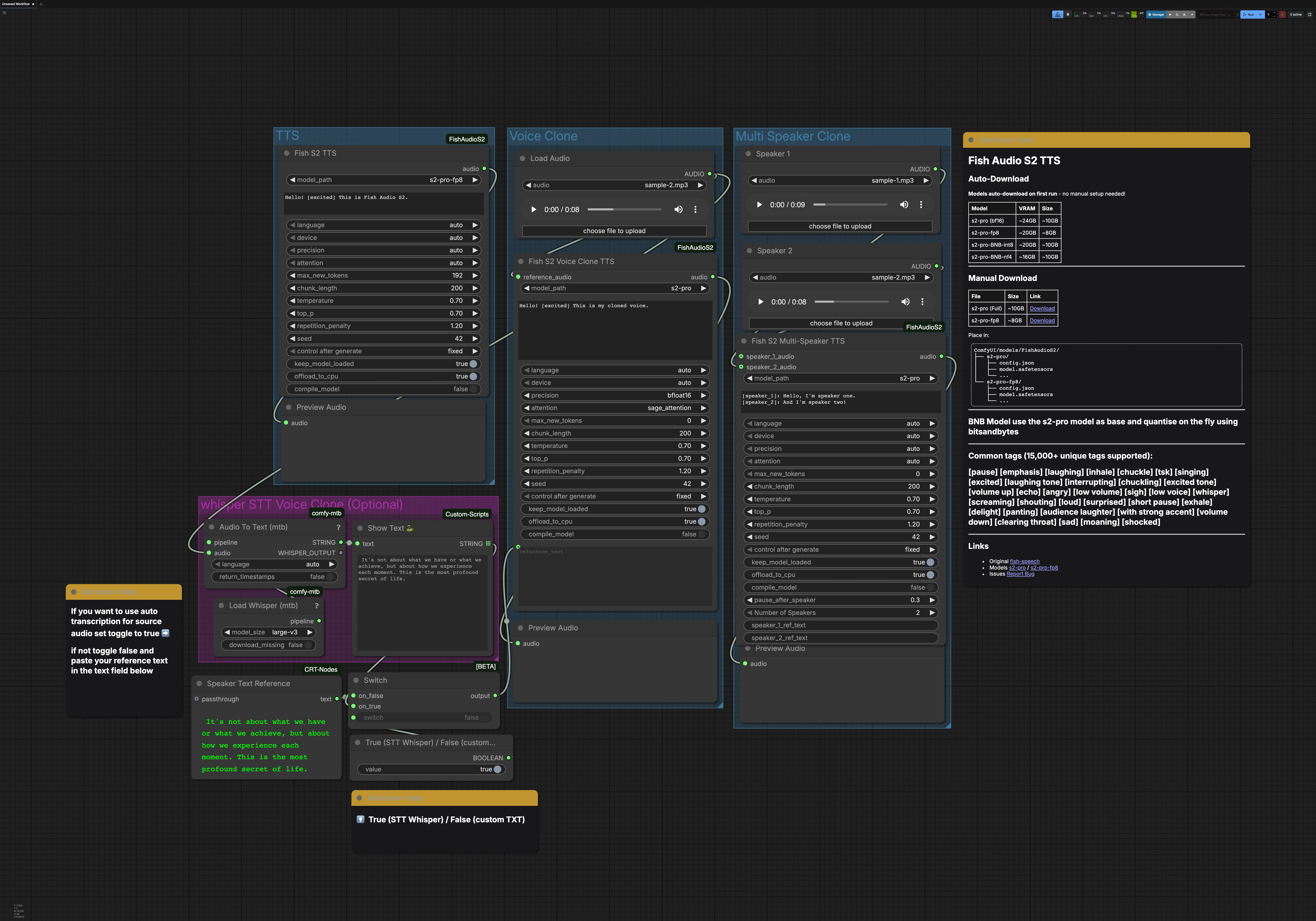
Этот рабочий процесс содержит три основных пути, которые можно запускать независимо: TTS, Voice Clone и Multi Speaker Clone. Опциональная группа Whisper STT может генерировать транскрипцию для клонирования голоса. Каждый путь заканчивается предварительным прослушиванием аудио, чтобы вы могли быстро оценить результаты.
Группа TTS#
Узел FishS2TTS (#42) выполняет прямое преобразование текста в речь с помощью Fish Audio S2 TTS. Введите свой сценарий в текстовое поле узла и добавьте теги стиля, такие как [excited], [pause] или [whisper], чтобы сформировать эмоции и темп. Обнаружение языка происходит автоматически, поэтому вы можете писать на целевом языке, и модель адаптируется. Выберите вариант S2-Pro, соответствующий памяти вашего GPU, например fp8 для меньших нагрузок. Выход направляется в PreviewAudio для мгновенного прослушивания.
Группа Voice Clone#
Используйте LoadAudio, чтобы предоставить короткий, чистый эталонный клип целевого голоса, затем направьте его в FishS2VoiceCloneTTS (#14). Предоставьте транскрипцию, соответствующую желаемому стилю речи; точный текст помогает модели сохранить ритм и акцент. Вы можете использовать текст из группы STT или ввести свой собственный, а также добавить теги стиля для уточнения эмоций и подачи. Настройки точности и внимания помогают сбалансировать скорость, память и стабильность для длинных строк. Синтезированный клон отправляется в PreviewAudio, чтобы вы могли быстро итератировать.
Группа Multi Speaker Clone#
Загрузите один эталонный клип на каждого говорящего, используя узлы LoadAudio, затем подключите их к FishS2MultiSpeakerTTS (#41). Предоставьте сценарий диалога, который маркирует каждый поворот с помощью [speaker_1], [speaker_2] и так далее. Этот шаблон по умолчанию включает двух говорящих, и узел поддерживает масштабирование до восьми различных голосов при соответствующей настройке. Вы можете смешивать повествовательную прозу, теги и диалог для управления потоком и эмоциями каждого персонажа. Финальный микс предварительно прослушивается для проверки времени и ясности.
Whisper STT для клонирования голоса (опционально)#
Load Whisper (mtb) (#6) с large-v3 обеспечивает работу Audio To Text (mtb) (#7) для автоматической транскрипции эталонного клипа. Распознанный текст отображается ShowText|pysssss (#8). Небольшой переключатель, построенный с использованием ComfySwitchNode (#34) и булевого управления, позволяет выбрать между выводом STT (true) или вашим собственным введенным текстом из Text Box line spot (#31) (false). Это полезно, когда вам нужна быстрая базовая транскрипция или при создании точной подсказки для клонирования.
Ключевые узлы в рабочем процессе Comfyui Fish Audio S2 TTS#
FishS2TTS (#42)#
Генерирует одноголосую речь из текста с опциональными тегами стиля и автоматическим обнаружением языка. Настройте вариант модели в соответствии с вашим оборудованием, например, выбрав fp8, когда VRAM ограничен. Используйте контроль семян для повторяемых дублей и вносите небольшие изменения при исследовании альтернативных подач. Для длинных сценариев выберите бэкэнд внимания, оптимизированный для стабильности.
FishS2VoiceCloneTTS (#14)#
Создает клонированный голос, используя в качестве условия reference_audio и reference_text. Лучшие результаты достигаются из чистой речи с постоянным тоном и транскрипцией, которая отражает предполагаемую каденцию. Теги стиля могут быть добавлены в финальный текст для управления настроением без ущерба для идентичности. Настройки точности и внимания помогают сбалансировать качество и память для расширенных строк.
FishS2MultiSpeakerTTS (#41)#
Синтезирует многоголосые разговоры, сочетая эталонное аудио каждого говорящего с диалогом, маркированным метками [speaker_n]. Увеличьте количество говорящих по мере необходимости и назначьте отдельные клипы для более сильного разделения. Поддерживайте постоянный тон эталонного аудио каждого говорящего, чтобы избежать смешивания. Используйте seed для детерминированного микширования при рендеринге сцен с несколькими дублями.
Дополнительные опции#
- Используйте теги стиля обдуманно. Начните с нескольких, таких как [excited], [whisper], [emphasis], [pause], и добавляйте только по мере необходимости для ясности.
- Для клонирования голоса обрежьте тишину в начале и конце эталонного аудио и избегайте фонового шума, чтобы сохранить тембр.
- Если память GPU ограничена, предпочитайте S2-Pro fp8 или варианты с квантованием во время выполнения. Для максимальной точности используйте более высокую точность.
- Пунктуация имеет значение. Запятые и точки улучшают фразировку, а теги, размещенные на границах клауз, звучат более естественно.
- Для многоголосых сценариев держите одно высказывание на строку и всегда префиксируйте правильной меткой [speaker_n] для поддержания разделения.
Ресурсы:
- Fish Audio S2-Pro model card: Hugging Face
- Вариант S2-Pro fp8: Hugging Face
- Проект Fish-Speech: GitHub
- Узлы ComfyUI Fish Audio S2: GitHub
- Whisper large-v3: GitHub
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы выражаем благодарность Saganaki22 за пользовательские узлы ComfyUI-FishAudioS2 и Fish Audio за модель S2-Pro за их вклад и поддержку. Для получения авторитетной информации, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- Saganaki22/ComfyUI-FishAudioS2 Custom Nodes
- GitHub: Saganaki22/ComfyUI-FishAudioS2
- Fish Audio/S2-Pro Model
- Hugging Face: fishaudio/s2-pro
Примечание: Использование ссылочных моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими организациями.
