
ComfyUI MOSS TTS: преобразование текста в речь, клонирование голоса, SFX и диалоги в одном рабочем процессе#
Этот рабочий процесс ComfyUI MOSS TTS преобразует текст в яркую речь 24 кГц с использованием семейства OpenMOSS MOSS-TTS. Он охватывает быстрое синтезирование одного говорящего, клонирование голоса zero-shot из короткого эталонного клипа, описательный дизайн голоса, процедурные звуковые эффекты и многоголосые диалоги с опциональными эталонными записями для каждого говорящего.
Основан на официальной стеке узлов MOSS-TTS и семейства моделей, он балансирует скорость и качество. Локальный путь 1.7B — это практичный быстрый путь на одном GPU, в то время как более крупные модели Delay 8B обменивают скорость на более широкие возможности и выразительность. Если вам нужны повторно используемые подсказки, клонированные голоса или диалоги внутри ComfyUI, этот рабочий процесс ComfyUI MOSS TTS создан для вас.
Ключевые модели в рабочем процессе Comfyui ComfyUI MOSS TTS#
- OpenMOSS MOSS-TTS Local 1.7B. Дружественный к одному GPU текстово-речевой трансформер, который обеспечивает быструю, естественную речь 24 кГц для повседневной производственной работы. Карточка модели: MOSS-TTS-Local-Transformer.
- OpenMOSS MOSS-TTS Delay 8B. Более крупная линейка моделей, которая делает акцент на качество, сходство говорящих и просодию за счет скорости и памяти. Карточка модели: MOSS-TTS.
- MOSS Audio Tokenizer. Изученный кодек, который связывает формы волн и дискретные токены для моделей MOSS-TTS, обеспечивая высококачественное декодирование. Карточка модели: MOSS-Audio-Tokenizer.
Для деталей реализации и обновлений смотрите официальные репозитории: OpenMOSS/MOSS-TTS и стек узлов, поддерживающий этот рабочий процесс richservo/comfyui-moss-tts.
Как использовать рабочий процесс Comfyui ComfyUI MOSS TTS#
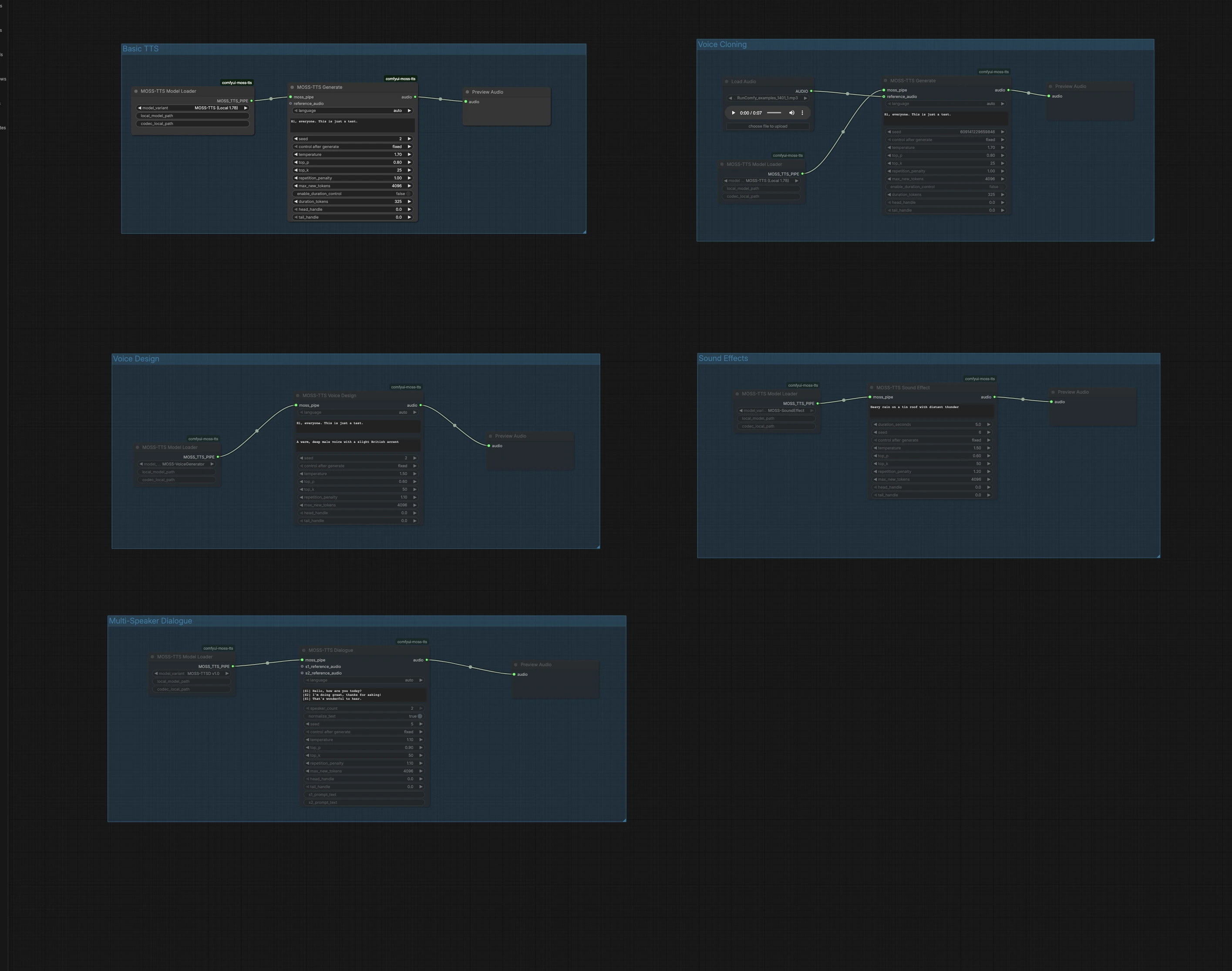
Этот граф организован в пять независимых групп. Выберите группу, которая соответствует вашей цели, запустите её, затем прослушайте аудио прямо на полотне. Вы можете запускать несколько групп параллельно для предварительного прослушивания различных подходов.
Основной TTS#
Группа Основной TTS преобразует обычный текст в речь с помощью локального быстрого пути 1.7B. Загрузите модель в MossTTSModelLoader (#1), передайте ваш текст в MossTTSGenerate (#2), затем прослушайте в PreviewAudio (#3). Генератор основывается на вашей подсказке, чтобы формировать произношение и просодию, поэтому пишите естественно с пунктуацией для ритма. Оставьте семя фиксированным, когда хотите повторяемость, или рандомизируйте его при исследовании вариантов подачи.
Клонирование голоса#
Группа Клонирование голоса выполняет клонирование голоса zero-shot из короткого эталонного аудиоклипа. Импортируйте чистый образец голоса с помощью LoadAudio (#4), подключите его к MossTTSGenerate (#6), управляемому MossTTSModelLoader (#5), и предоставьте целевой текст. Модель извлекает тембр и стиль говорящего из эталона и воспроизводит ваш новый сценарий в этом голосе. Используйте нейтральное содержимое и минимальный фоновый шум в эталоне для улучшения сходства и держите продолжительность умеренной для быстрейшего выполнения.
Дизайн голоса#
Дизайн голоса создает новый голос из описания на естественном языке, а не из примерного клипа. MossTTSVoiceDesign (#9) использует текстовое описание, например, "Теплый, глубокий мужской голос с легким британским акцентом", в сочетании с вашим сценарием, чтобы синтезировать речь 24 кГц. Узел работает на выделенном пути генератора голоса, загруженном через MossTTSModelLoader (#8). Это идеально, когда вы хотите согласованную, воспроизводимую персону без использования реальных записей. Уточняйте описания характеристиками, такими как возраст, тембр, акцент и энергия, чтобы управлять звуком.
Звуковые эффекты#
Звуковые эффекты генерируют несвязные аудио из текстовых подсказок, полезные для звуковых дорожек, переходов или фоновых слоев. С MossTTSSoundEffect (#12) и его модельным трубопроводом из MossTTSModelLoader (#11) подсказки, такие как "Сильный дождь на жестяной крыше с отдалённым громом", создают насыщенные, циклические текстуры. Используйте краткие существительные и действия для определения сцены, затем добавьте несколько прилагательных, чтобы задать интенсивность или дистанцию. Предварительно прослушайте в PreviewAudio (#13) и быстро итерайте, чтобы подогнать под ваш микс.
Многоголосый диалог#
Группа Многоголосый диалог воспроизводит прописанные разговоры с опциональными эталонными клипами для каждого говорящего. Напишите ваш сценарий, используя теги говорящих в скобках, например, [S1] Привет. и [S2] Привет!, затем передайте его в MossTTSDialogue (#15) под модельным трубопроводом из MossTTSModelLoader (#14). Вы можете подключить эталонные аудиовходы для S1 и S2, чтобы клонировать конкретные голоса для каждой роли, или оставить их пустыми, чтобы модель выбрала различных говорящих только из контекста текста. Этот путь хорошо подходит для вызовов-ответов, повествования с репликами персонажей или макетов голосового интерфейса.
Ключевые узлы в рабочем процессе Comfyui ComfyUI MOSS TTS#
MossTTSModelLoader (#1)#
Загружает выбранное семейство моделей OpenMOSS и собирает внутренний TTS трубопровод. Выберите вариант Local 1.7B для быстрой итерации на одном GPU или переключитесь на более крупную модель Delay 8B, когда вы придаёте приоритет выразительности и сходству. Держите один загрузчик на семейство задач, чтобы каждая нисходящая ветвь оставалась автономной.
MossTTSGenerate (#2)#
Основной синтезатор одного говорящего, который потребляет ваш текстовый запрос и опциональные эталонные аудиозаписи для создания речи 24 кГц. Предоставьте чистый, хорошо пунктуированный текст для более чёткого ритма и подключите короткий голосовой клип, когда вам нужно клонирование zero-shot. Переключайте семена между фиксированным и случайным, чтобы сбалансировать воспроизводимость и исследование.
MossTTSVoiceDesign (#9)#
Генерирует новый голос из описательной подсказки вместе с текстом для озвучивания. Сосредоточьтесь на описании тембра, возраста, акцента и энергии, чтобы управлять идентичностью, оставаясь кратким. Это сильный выбор, когда лицензирование или использование реального голоса нецелесообразно.
MossTTSSoundEffect (#12)#
Синтезирует невербальное аудио из короткого текстового описания. Пишите компактные подсказки, которые закрепляют источник, действие и пространство, затем итерайте, чтобы соответствовать сцене. Отлично подходит для атмосферы и одноразовых эффектов внутри того же графа ComfyUI MOSS TTS, который вы используете для диалогов.
MossTTSDialogue (#15)#
Анализирует теги говорящих в скобках и воспроизводит многократные разговоры в виде одного аудиовыхода. Используйте [S1], [S2] и так далее, чтобы отметить каждую реплику, и опционально подключите эталонные клипы для каждого говорящего, чтобы сохранить идентичность на протяжении всех реплик. Держите реплики краткими для наиболее надёжных переходов между говорящими.
Дополнительные возможности#
- Начните с модели Local 1.7B для быстрых черновиков, затем переключитесь на контрольную точку Delay 8B, когда вам нужно большее сходство или более богатая просодия.
- Для клонирования zero-shot используйте чистый голосовой клип продолжительностью 5–15 с минимальным реверберацией и шумом для улучшения передачи тембра.
- В диалоге держите теги говорящих консистентными и без пунктуации, как
[S1], чтобы избежать ошибок разбора. - Создавайте подсказки для дизайна голоса с 3–6 характеристиками, такими как тембр, возраст, акцент, стиль и энергия, для предсказуемых результатов.
- Используйте пунктуацию и разрывы строк в вашем тексте, чтобы контролировать паузы и ритм в выходах ComfyUI MOSS TTS.
- Добавьте узел
SaveAudioпосле любого предпросмотра, если хотите автоматический экспорт файлов для пакетного рендеринга.
Ссылки: OpenMOSS/MOSS-TTS • MOSS-TTS-Local-Transformer • MOSS-TTS • MOSS-Audio-Tokenizer • comfyui-moss-tts
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы с благодарностью признаем richservo за пользовательские узлы ComfyUI MOSS-TTS, OpenMOSS за репозиторий MOSS-TTS и OpenMOSS-Team за модели MOSS-TTS (Delay 8B и Local 1.7B) и MOSS Audio Tokenizer за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, приведённым ниже.
Ресурсы#
- richservo/comfyui-moss-tts
- GitHub: richservo/comfyui-moss-tts
- OpenMOSS/MOSS-TTS
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS (Delay 8B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS-Local-Transformer (Local 1.7B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS-Local-Transformer
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-Audio-Tokenizer
- Hugging Face: OpenMOSS-Team/MOSS-Audio-Tokenizer
- arXiv: 2602.10934
Примечание: Использование упомянутых моделей, наборов данных и кода регулируется соответствующими лицензиями и условиями, предоставленными их авторами и поддерживающими организациями.
