
InfiniteTalk: синхронизированное с речью портретное видео из одного изображения в ComfyUI#
Этот рабочий процесс ComfyUI InfiniteTalk создает естественные, синхронизированные с речью портретные видео из одного исходного изображения и аудиоклипа. Он сочетает генерацию изображения-видео WanVideo 2.1 с моделью говорящей головы MultiTalk для создания выразительного движения губ и стабильной идентичности. Если вам нужны короткие социальные клипы, дублирование видео или обновления аватаров, InfiniteTalk превращает неподвижное фото в плавное говорящее видео за считанные минуты.
InfiniteTalk основан на отличных исследованиях MultiTalk от MeiGen-AI. Для справочной информации и атрибуций, см. проект с открытым исходным кодом: MeiGen-AI/MultiTalk.
Основные модели в рабочем процессе ComfyUI InfiniteTalk#
- MultiTalk (GGUF, вариант InfiniteTalk): Обеспечивает фонамное движение лица из аудио, чтобы движения рта и челюсти естественно следовали за речью. Ссылка: Kijai/WanVideo_comfy_GGUF › InfiniteTalk и исходная идея: MeiGen-AI/MultiTalk.
- WanVideo 2.1 I2V 14B (GGUF): Основной генератор изображения-видео, который сохраняет идентичность, освещение и позу при анимации кадров. Рекомендуемые веса: city96/Wan2.1-I2V-14B-480P-gguf.
- Wan 2.1 VAE (bf16): Декодирует латентные кадры в RGB с минимальным сдвигом цвета; предоставляется в пакете WanVideo выше.
- UMT5-XXL текстовый энкодер: Интерпретирует ваши положительные и отрицательные подсказки, чтобы направлять стиль, сцену и контекст движения. Семейство моделей: google/umt5-xxl.
- CLIP Vision: Извлекает визуальные встраивания из вашего эталонного изображения, чтобы закрепить идентичность и общий внешний вид.
- Wav2Vec2 (Tencent GameMate): Преобразует необработанную речь в надежные аудио характеристики для встраиваний MultiTalk, улучшая синхронизацию и просодию: TencentGameMate/chinese-wav2vec2-base.
Совет: этот граф InfiniteTalk создан для GGUF. Держите веса InfiniteTalk MultiTalk и основу WanVideo в GGUF, чтобы избежать несовместимостей. Также доступны опциональные сборки fp8/fp16: Kijai/WanVideo_comfy_fp8_scaled и Kijai/WanVideo_comfy.
Как использовать рабочий процесс ComfyUI InfiniteTalk#
Рабочий процесс выполняется слева направо. Вы предоставляете три вещи: чистое портретное изображение, аудиофайл с речью и короткую подсказку для управления стилем. Затем граф извлекает текстовые, визуальные и аудио подсказки, объединяет их в видео латенты, учитывающие движения, и рендерит синхронизированный MP4.
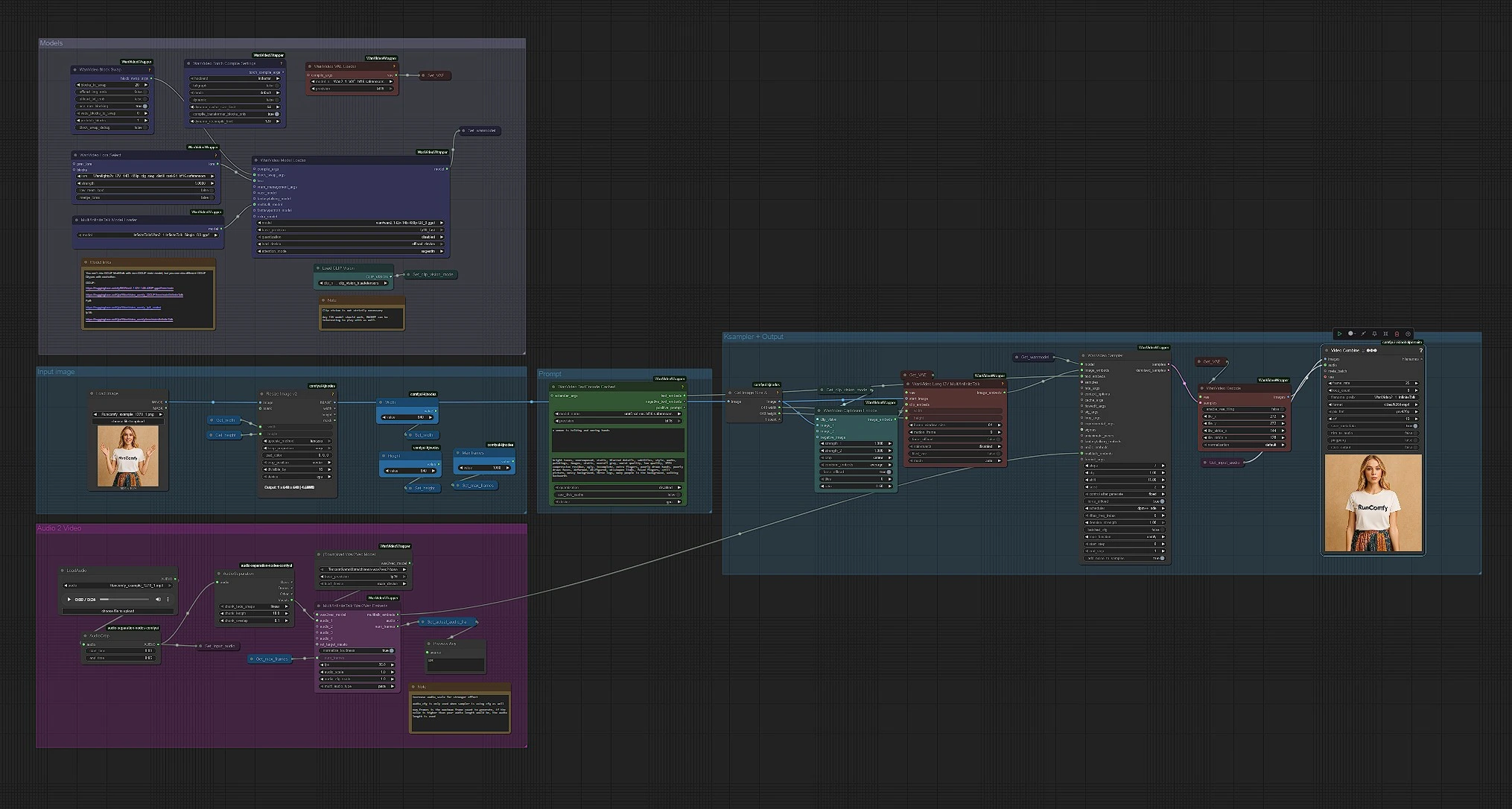
Модели#
Эта группа загружает WanVideo, VAE, MultiTalk, CLIP Vision и текстовый энкодер. WanVideoModelLoader (#122) выбирает основу Wan 2.1 I2V 14B GGUF, а WanVideoVAELoader (#129) подготавливает соответствующий VAE. MultiTalkModelLoader (#120) загружает вариант InfiniteTalk, который управляет движением, основанным на речи. Вы можете опционально прикрепить Wan LoRA в WanVideoLoraSelect (#13) для изменения внешнего вида и движения. Оставьте их нетронутыми для быстрого первого запуска; они заранее настроены для 480p конвейера, который подходит большинству GPU.
Подсказка#
WanVideoTextEncodeCached (#241) принимает ваши положительные и отрицательные подсказки и кодирует их с помощью UMT5. Используйте положительную подсказку для описания темы и тона сцены, а не идентичности; идентичность исходит из эталонного фото. Держите отрицательную подсказку сосредоточенной на артефактах, которых вы хотите избежать (размытости, лишние конечности, серый фон). Подсказки в InfiniteTalk в основном формируют освещение и энергию движения, в то время как лицо остается постоянным.
Входное изображение#
CLIPVisionLoader (#238) и WanVideoClipVisionEncode (#237) встраивают ваш портрет. Используйте четкое, фронтально снятое фото с головой и плечами и равномерным освещением. При необходимости, обрежьте аккуратно, чтобы у лица было пространство для движения; сильное обрезание может дестабилизировать движение. Встраивания изображения передаются вперед, чтобы сохранить идентичность и детали одежды, когда видео анимируется.
Аудио для MultiTalk#
Загрузите вашу речь в LoadAudio (#125); обрежьте её с помощью AudioCrop (#159) для быстрого предварительного просмотра. DownloadAndLoadWav2VecModel (#137) загружает Wav2Vec2, а MultiTalkWav2VecEmbeds (#194) преобразует клип в фонамные характеристики движения. Короткие нарезки 4-8 секунд отлично подходят для итераций; вы можете запускать более длинные, когда вам понравится результат. Чистые, сухие голосовые дорожки работают лучше всего; сильная фоновая музыка может сбивать тайминг губ.
Изображение-видео, выборка и вывод#
WanVideoImageToVideoMultiTalk (#192) объединяет ваше изображение, встраивания CLIP Vision и MultiTalk в покадровые встраивания изображения, размер которых задается константами Width и Height. WanVideoSampler (#128) генерирует латентные кадры с использованием модели WanVideo из Get_wanmodel и ваших текстовых встраиваний. WanVideoDecode (#130) преобразует латенты в RGB кадры. Наконец, VHS_VideoCombine (#131) объединяет кадры и аудио в MP4 с частотой 25 кадров в секунду с сбалансированной настройкой качества, создавая финальный клип InfiniteTalk.
Основные узлы в рабочем процессе ComfyUI InfiniteTalk#
WanVideoImageToVideoMultiTalk (#192)#
Этот узел является сердцем InfiniteTalk: он определяет анимацию говорящей головы, объединяя начальное изображение, характеристики CLIP Vision и руководство MultiTalk на вашей целевой разрешении. Настройте width и height, чтобы установить соотношение сторон; 832×480 - хороший выбор для скорости и стабильности. Используйте его как основное место для согласования идентичности с движением перед выборкой.
MultiTalkWav2VecEmbeds (#194)#
Преобразует характеристики Wav2Vec2 в встраивания движения MultiTalk. Если движение губ слишком тонкое, увеличьте его влияние (масштабирование аудио) на этом этапе; если оно чрезмерно, уменьшите влияние. Убедитесь, что аудио доминирует в речи для надежного тайминга фонамов.
WanVideoSampler (#128)#
Генерирует латенты видео, учитывая встраивания изображения, текста и MultiTalk. Для первых запусков оставьте планировщик и шаги по умолчанию. Если вы видите мерцание, увеличение общего количества шагов или включение CFG может помочь; если движение кажется слишком жестким, уменьшите CFG или силу выборки.
WanVideoTextEncodeCached (#241)#
Кодирует положительные и отрицательные подсказки с помощью UMT5-XXL. Используйте краткий, конкретный язык, например "студийный свет, мягкая кожа, естественный цвет" и держите отрицательные подсказки сосредоточенными. Помните, что подсказки уточняют кадрирование и стиль, в то время как синхронизация рта исходит от MultiTalk.
Опциональные дополнения#
- Держите MultiTalk и WanVideo в одной семье развертывания (все GGUF или все не-GGUF), чтобы избежать несовместимостей.
- Итерируйте с 5-8 секундным обрезком аудио и стандартным размером 480p; при необходимости увеличьте позже.
- Если идентичность колеблется, попробуйте более чистый исходный фото или более мягкий LoRA. Сильные LoRA могут перебивать сходство.
- Записывайте речь в тихой комнате и нормализуйте уровни; InfiniteTalk лучше всего отслеживает фонамы с чистым, сухим голосом.
Благодарности#
Рабочий процесс InfiniteTalk представляет собой значительный скачок в создании видео на основе ИИ, сочетая гибкую систему узлов ComfyUI с моделью MultiTalk AI. Эта реализация стала возможной благодаря оригинальным исследованиям и выпуску MeiGen-AI, чей проект MultiTalk обеспечивает естественную синхронизацию речи InfiniteTalk. Особая благодарность также команде проекта InfiniteTalk за предоставление исходной справочной информации, а также сообществу разработчиков ComfyUI за обеспечение бесшовной интеграции рабочих процессов.
Кроме того, выражаем благодарность Kijai, который внедрил InfiniteTalk в Wan Video Sampler node, упростив создание высококачественных говорящих и поющих портретов непосредственно внутри ComfyUI. Оригинальная ссылка на ресурс для InfiniteTalk доступна здесь: InfiniteTalk Example Workflow.
Вместе эти вклады делают возможным для создателей превращение простых портретов в реалистичные, непрерывные говорящие аватары, открывая новые возможности для повествования, дублирования и производительности контента на основе ИИ.