
ChatterBox TTS ComfyUI: Многорежимный TTS, преобразование голоса, многоязычный и диалоговый синтез в одном графе#
ChatterBox TTS ComfyUI — это компактный, ориентированный на создателей аудиорабочий процесс, который позволяет генерировать речь в нескольких режимах с одного холста: стандартный TTS, Turbo TTS для быстрых черновиков, многоязычное повествование, клонирование голоса на основе ссылок, преобразование голоса и сценарные диалоги на двух говорящих. Он поддерживается набором узлов FL ChatterBox от ComfyUI_Fill-ChatterBox, который интегрирует проект с открытым исходным кодом Resemble AI Chatterbox.
Используйте этот рабочий процесс для прототипирования AI голосов, локализации реплик на другие языки, преобразования одного исполнения в другой голос или блокировки обменов персонажей. Макет сохраняет каждый путь отдельно, чтобы вы могли прослушивать результаты рядом и быстро решать, какой режим ChatterBox TTS ComfyUI подходит для вашей задачи.
Основные модели в рабочем процессе Comfyui ChatterBox TTS ComfyUI#
- Resemble AI Chatterbox TTS модели. Основные нейронные TTS, которые превращают сценарий в естественную речь с дополнительным референсным аудио для управления голосом и стилем. Resemble AI Chatterbox
- Resemble AI Chatterbox Turbo TTS. Вариант TTS с низкой задержкой, оптимизированный для скорости, когда вам нужны быстрые дубли и интерактивные подсказки. Resemble AI Chatterbox
- Resemble AI Chatterbox Multilingual TTS. Модели, которые воспроизводят текст на нескольких языках, сохраняя выбранный стиль или референсный голос. Resemble AI Chatterbox
- Resemble AI Chatterbox Voice Conversion. Преобразует тембр одной записи в целевой голос, сохраняя тайминг и содержание. Resemble AI Chatterbox
Как использовать рабочий процесс Comfyui ChatterBox TTS ComfyUI#
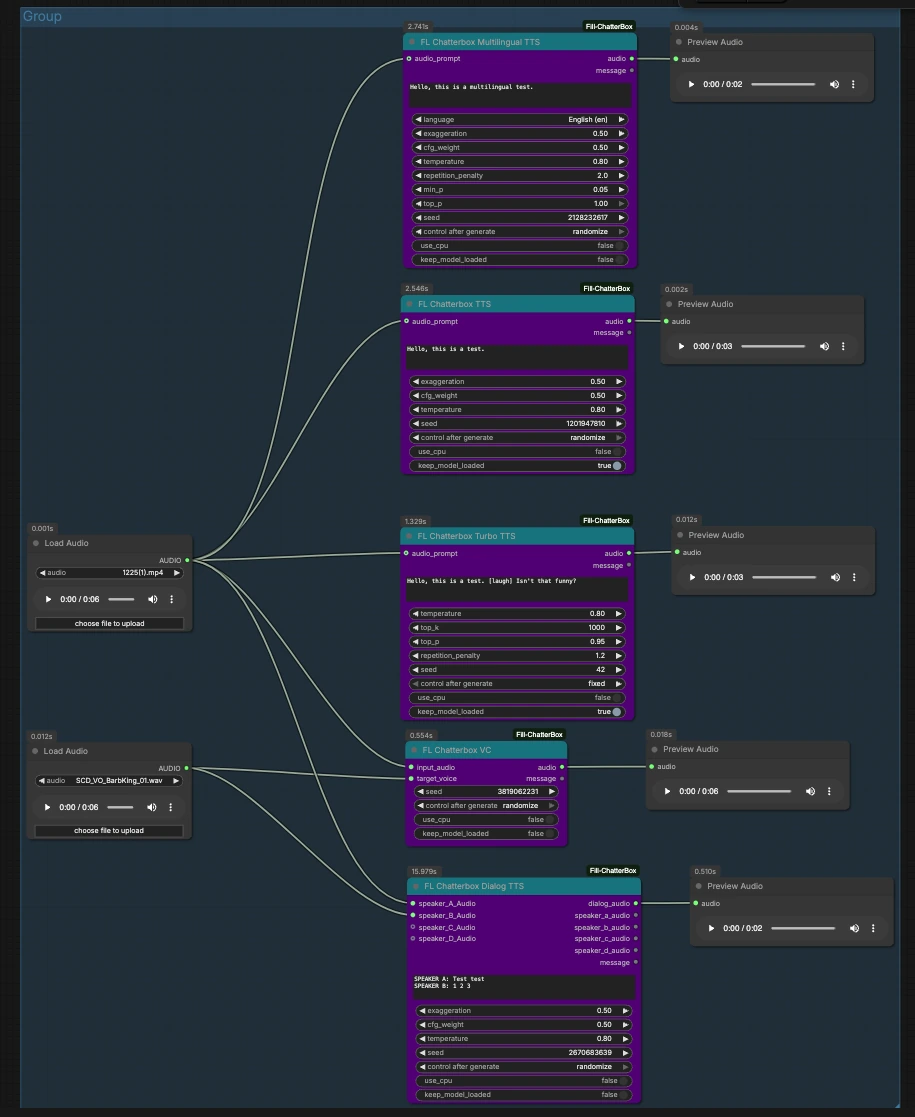
Этот граф организован как параллельные пути, которые начинаются с общих аудиовходов и переходят в узлы ChatterBox, каждый из которых предварительно просматривает свой собственный результат. Загрузите или замените два входных клипа, затем запустите нужный путь.
Входы: референсное и исходное аудио#
Два узла LoadAudio предоставляют повторно используемые входы. LoadAudio (#12) подает несколько путей в качестве стиля или референса источника. LoadAudio (#20) служит альтернативным референсом или целевым голосом. Вы можете указать на короткие, чистые клипы, представляющие стиль речи или идентичность, которую вы хотите сымитировать. Оба принимают распространенные аудиофайлы и могут также извлекать аудио из видео.
Стандартный TTS с необязательной стилевой ссылкой#
FL_ChatterboxTTS (#16) генерирует речь из вашего сценария и может опционально взять audio_prompt из LoadAudio (#12) для захвата голоса и исполнения. Введите ваш текст, подключите подходящую ссылку, если хотите сходство голосов, и поставьте узел в очередь. Используйте прикрепленный PreviewAudio для прослушивания. Исправьте seed, когда вам нужны воспроизводимые дубли, или рандомизируйте для изучения вариаций.
Turbo TTS для быстрой итерации#
FL_ChatterboxTurboTTS (#15) сосредоточен на быстрой синтезе для быстрых черновиков и интерактивного редактирования. Он принимает audio_prompt из LoadAudio (#20), если вы хотите подправить тон или идентичность. Держите сценарии краткими при быстром движении и экспериментируйте с разметкой, как в примере “[laugh]” для тестирования невербальных сигналов. Прослушайте выходные данные, затем переключитесь на стандартный или многоязычный TTS, если хотите более богатое исполнение.
Многоязычное повествование#
FL_ChatterboxMultilingualTTS (#25) воспроизводит ваш сценарий на выбранном языке и может заимствовать стиль из audio_prompt на LoadAudio (#12). Выберите метку языка (например, English (en), как показано в графе) и предоставьте текст на этом языке. Короткий референсный клип помогает поддерживать последовательный акцент или персонажа на разных языках. Слушайте в PreviewAudio и итеративно улучшайте фразировку для ясности.
Преобразование голоса#
FL_ChatterboxVC (#19) преобразует тембр строки input_audio из LoadAudio (#12) в target_voice из LoadAudio (#20). Это идеально, когда у вас уже есть идеально синхронизированное чтение, и вы просто хотите, чтобы оно было произнесено другим голосом. Удалите тишину и держите целевой голос чистым, чтобы уменьшить артефакты. Используйте превью, чтобы подтвердить, что содержание сохранено, в то время как идентичность изменяется.
Синтез диалога с двумя говорящими#
FL_ChatterboxDialogTTS (#23) превращает многострочный сценарий в один dialog_audio трек. Предоставьте необязательные speaker_A_Audio и speaker_B_Audio из двух узлов LoadAudio, чтобы закрепить голос каждого персонажа. В окне сценария добавьте префиксы к строкам с тегами говорящих, такими как “SPEAKER A:” и “SPEAKER B:”, чтобы назначить очереди, как показано в графе. Вы можете расширить до говорящих C и D, добавив референсные клипы к их входам.
Просмотр и сравнение#
Каждый путь разветвляется на свой собственный PreviewAudio, чтобы вы могли немедленно прослушать и сравнить режимы. Запустите один путь за раз или поставьте в очередь несколько, чтобы прослушать различия между стандартными, Turbo, многоязычными, конверсионными и диалоговыми выходами в рамках одной сессии ChatterBox TTS ComfyUI.
Основные узлы в рабочем процессе Comfyui ChatterBox TTS ComfyUI#
FL_ChatterboxTTS (#16)#
Универсальный TTS, который принимает сценарий и необязательную ссылку audio_prompt для имитации стиля. Используйте его, когда качество и управляемость имеют наибольшее значение. Держите один и тот же референсный клип на протяжении дублей для последовательной идентичности и заблокируйте seed, когда вам нужна точная воспроизводимость.
FL_ChatterboxTurboTTS (#15)#
Быстрый TTS для набросков строк, итерации на подсказках или предварительного просмотра идей разметки. Он также принимает audio_prompt для управления голосом. Если вы заметите более тонкую просодию по сравнению со стандартным путем, завершите с FL_ChatterboxTTS, используя тот же сценарий и референс.
FL_ChatterboxMultilingualTTS (#25)#
Языково-осознанный TTS, который сохраняет выбранную персону при переключении языков. Выберите метку языка и предоставьте текст на этом языке. Соответствующий audio_prompt сохраняет акцент и энергию в соответствии с вашим референсным голосом.
FL_ChatterboxVC (#19)#
Преобразование голоса, которое отображает исполнение input_audio на target_voice. Используйте чистый, представительский целевой клип и хорошо темпированное исходное чтение. Для наилучших результатов удалите длинные паузы и избегайте сильного фонового шума в любом из клипов.
FL_ChatterboxDialogTTS (#23)#
Много-спикерный TTS, который разбирает помеченные строки в один разговор. Назначьте референсы для каждого входного персонажа, который вы планируете использовать, затем структурируйте сценарий с четкими тегами “SPEAKER X:”. Держите очереди разумно короткими для естественного темпа и более простых редактирований времени позже.
Дополнительные опции#
- Держите референсные клипы короткими, чистыми и выразительными; комнатный шум и шум снижают качество голоса.
- Используйте фиксированный seed, когда вам нужно совпадение времени и исполнения при пересмотрах; рандомизируйте, чтобы исследовать альтернативы.
- Если путь звучит слишком громко или обрезан, нормализуйте свои референсы и уменьшите входное усиление перед синтезом.
- Turbo отлично подходит для исследования подсказок; повторно запустите перспективные строки с стандартным или многоязычным TTS для финальной полировки.
- Сценарии диалогов легче поддерживать, если вы размещаете одну реплику на строку и последовательно помечаете говорящих.
- Добавьте узел
SaveAudioпосле любого просмотра, если хотите экспортировать файлы прямо с холста.
ChatterBox TTS ComfyUI предоставляет гибкую, единую графическую площадку для испытания голосов, языков и диалогов без переключения контекста, все поддерживается ComfyUI_Fill-ChatterBox и Resemble AI Chatterbox.
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы с благодарностью признаем filliptm за ComfyUI_Fill-ChatterBox и Resemble AI за Chatterbox за их вклад и поддержку. Для получения авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, приведенным ниже.
Ресурсы#
- filliptm/ComfyUI_Fill-ChatterBox
- GitHub: filliptm/ComfyUI_Fill-ChatterBox
- resemble-ai/chatterbox
- GitHub: resemble-ai/chatterbox
Примечание: Использование упомянутых моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.
