
Мультимодальная генерация и редактирование видео Bernini#
Этот рабочий процесс мультимодальной генерации и редактирования видео Bernini является готовым решением ComfyUI для редактирования видео с учетом идентичности и преобразования видео-видео с использованием эталонов. Он сочетает исходное видео, одно или несколько эталонных изображений и сфокусированную подсказку, чтобы сохранить движение и поведение камеры при замене или рестайлинге объекта. Рабочий процесс сочетает высокие и низкие диффузионные основы Bernini с текстовым кодированием в стиле Wan, совместимым с Bernini VAE, LightX2V LoRAs и специфической для Bernini кондиционированием, чтобы результаты выглядели согласованно от кадра к кадру.
Создан для создателей и исследователей, оценивающих Bernini внутри ComfyUI, рабочий процесс превосходно справляется с заменой персонажей, редактированием с сохранением движения, имитацией и генерацией коротких форматов с учетом камеры. Он экспортирует отредактированный MP4 плюс необязательное сравнение "бок о бок", что позволяет легко оценить влияние вашей подсказки и эталонного набора. На протяжении всего этого README термин "мультимодальная генерация и редактирование видео Bernini" относится к этому полному графу.
Ключевые модели в мультимодальной генерации и редактировании видео Bernini в ComfyUI#
- Семейство диффузионных моделей ByteDance Bernini (высокие и низкие основы). Обеспечивает основные сети денойзинга, используемые в двухэтапном расписании: высокая модель обрабатывает структуру при более сильном шуме, в то время как низкая модель уточняет детали и временную согласованность. См. хаб моделей для эталонных весов и заметок: ByteDance/Bernini.
- Кодировщик текста Wan (umT5-XXL). Кодировщик в стиле Wan T5, который превращает вашу инструкцию в кондиционирование для Bernini; доступен в ComfyUI через интерфейс, совместимый с CLIP. Подходящие активы для ComfyUI доступны здесь: Kijai/WanVideo_comfy_fp8_scaled.
- VAE Wan 2.1. Выполняет латентное декодирование, чтобы превратить денойзированные латенты в видеокадры с цветовой точностью, соответствующей обучению Wan/Bernini. VAE, готовый к использованию в ComfyUI, включен в тот же пакет активов: Kijai/WanVideo_comfy_fp8_scaled.
- Пара LightX2V LoRA (high_noise и low_noise). Легкие адаптеры, которые направляют Bernini к стабильному движению, сохраняя эталонную идентичность на протяжении кадров. Предоставленные FP8 веса LoRA соответствуют двухэтапной выборке, используемой в этом рабочем процессе, и упакованы с активами Bernini: Kijai/WanVideo_comfy_fp8_scaled.
Как использовать мультимодальную генерацию и редактирование видео Bernini в ComfyUI#
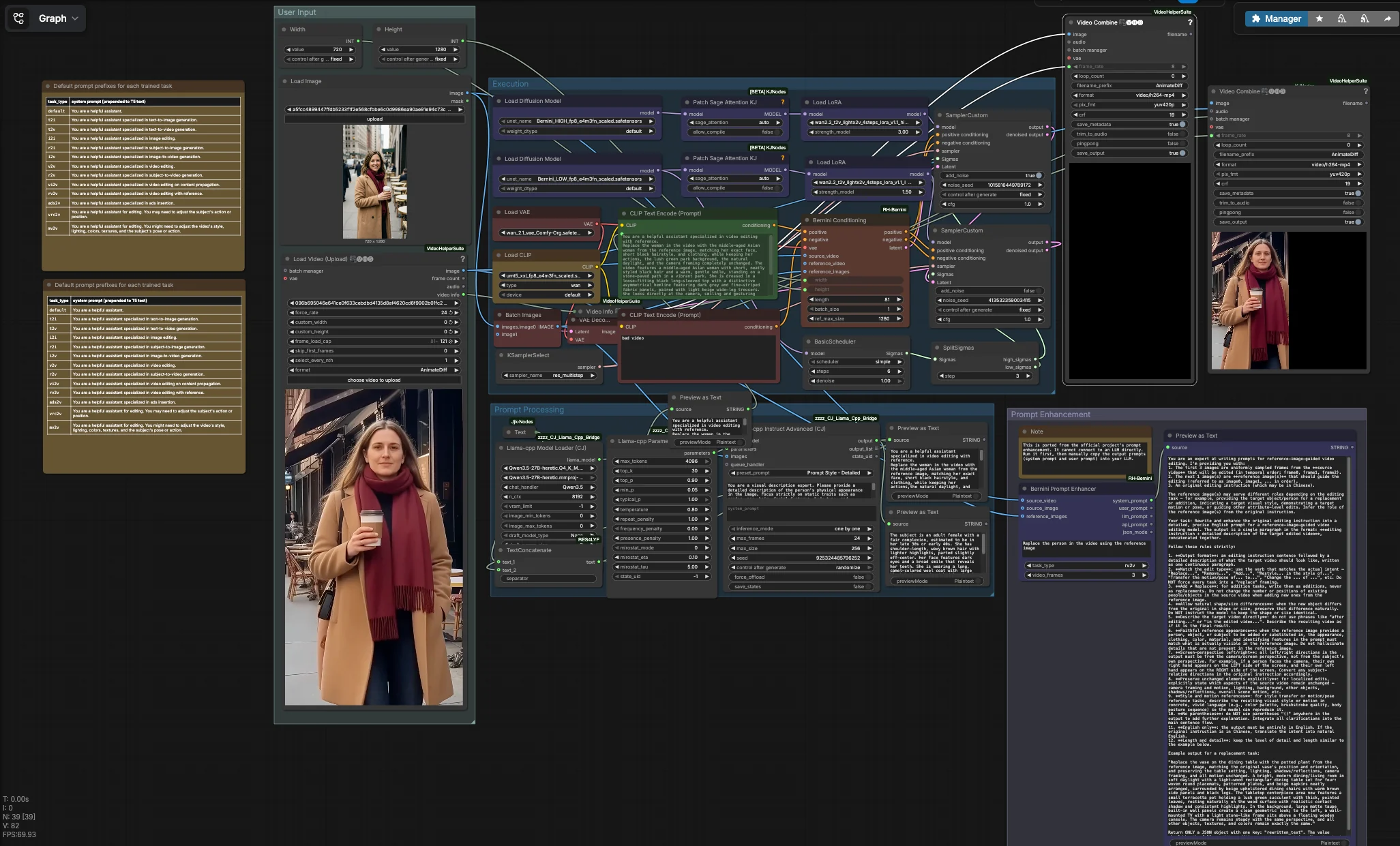
Этот рабочий процесс имеет четыре координированные группы. Вы предоставляете исходное видео и одно или несколько эталонных изображений, формируете текст инструкции, затем группа Execution выполняет двухфазный проход Bernini, который декодирует в кадры и собирает ваше выходное видео. Параллельная утилита может генерировать скелетные системные и пользовательские подсказки для написания подсказок с поддержкой LLM.
Ввод пользователя#
Загрузите ваше исходное видео с помощью VHS_LoadVideo (#90). Узел читает клип и раскрывает его метаданные, чтобы окончательная визуализация унаследовала исходную частоту кадров, что помогает сохранить ощущение движения. Добавьте одну или несколько эталонных идентичностей с помощью LoadImage (#31); фронтальные, хорошо освещенные лица с нейтральными выражениями работают лучше всего. Установите целевой размер, используя Width (#109) и Height (#110), желательно совпадая с исходным соотношением сторон, чтобы избежать растяжения. Стандартная отрицательная подсказка кодируется CLIPTextEncode (#4), чтобы подавлять общие артефакты в видео низкого качества; при необходимости вы можете уточнить ее.
Обработка подсказок#
Если вы хотите, чтобы инструкция точно соответствовала эталонной идентичности, граф может суммировать статические черты из ваших эталонных изображений с помощью локального LLM. llama_cpp_model_loader (#93) и llama_cpp_instruct_adv (#92) анализируют изображения, сгруппированные узлом BatchImagesNode (#74), и возвращают краткое описание неизменяемых атрибутов, таких как волосы, возраст и одежда. Это описание конкатенируется с вашей директивой задачи из JjkText (#104) через TextConcatenate (#102). Результат поступает в CLIPTextEncode (#3), который становится положительным кондиционированием для Bernini. Узлы предварительного просмотра показывают составленный текст, чтобы вы могли быстро итеративно работать, прежде чем запускать тяжелые стадии.
Усиление подсказок#
BerniniPromptEnhancer (#60) генерирует структурированные "системные" и "пользовательские" подсказки, адаптированные к выбранному типу задачи и входным данным. Запустите его, чтобы получить более сильные инструкции, которые вы можете вставить в ваш LLM для более богатого расширения подсказок; по дизайну он не подключен к основному графу. Эта утилита исходит из пользовательского пакета узлов Bernini: ComfyUI-RH-Bernini. Рассматривайте его как инструмент предварительного написания для стандартизации языка, который хорошо работает с кондиционированием Bernini.
Выполнение#
Основной путь начинается с загрузки UNet-ов HIGH и LOW Bernini и присоединения LightX2V LoRA для каждого этапа. BerniniConditioning (#34) объединяет ваши положительные и отрицательные кодировки, VAE, кадры исходного видео и эталонные изображения, чтобы построить специфическое для Bernini кондиционирование и начальный латент, согласованный с вашим разрешением и количеством кадров. BasicScheduler (#18) создает расписание денойзинга, затем SplitSigmas (#17) делит его на высокие и низкие диапазоны. Высокий семплер SamplerCustom (#19) устанавливает структуру и идентичность при более сильном шуме, передавая свой латент низкому семплеру SamplerCustom (#15) для деталей и временной полировки. KSamplerSelect (#27) выбирает алгоритм семплера, VAEDecode (#16) преобразует конечный латент в кадры, а VHS_VideoCombine (#87) визуализирует MP4, который наследует исходную частоту кадров. Параллельно ImageConcanate (#97) и второй VHS_VideoCombine (#96) создают визуализацию "бок о бок" для быстрого контроля качества. Ввод и сборка видео обеспечиваются Video Helper Suite: ComfyUI-VideoHelperSuite.
Ключевые узлы в мультимодальной генерации и редактировании видео Bernini в ComfyUI#
BerniniConditioning (#34) Создает кондиционирование, нативное для Bernini, комбинируя ваши текстовые кодировки, VAE, исходное видео и эталонные изображения. Он также подготавливает начальный объем латентов и обрабатывает пространственное и временное масштабирование. Настройте width и height в соответствии с вашим целевым разрешением и используйте length, чтобы контролировать количество генерируемых кадров. Если эталонный объект мал на изображении, увеличьте ref_max_size, чтобы модель лучше воспринимала детали идентичности. Этот узел является частью пользовательского пакета Bernini: ComfyUI-RH-Bernini.
LoraLoaderModelOnly (#11) Применяет LightX2V high_noise LoRA к основе HIGH. Увеличение его strength_model повышает соответствие эталону на структурной стадии, полезно, когда силуэт объекта или грубые черты не соответствуют исходному видео. Уменьшите его, если редактирование становится слишком жестким или подавляет естественное движение. Используйте в тандеме с LoRA низкой стадии, чтобы сбалансировать точность и плавность.
LoraLoaderModelOnly (#29) Применяет LightX2V low_noise LoRA к основе LOW. Этот LoRA уточняет текстуры, такие как волосы, кожа и одежда, сохраняя движение, заданное высокой стадией. Если детали идентичности дрейфуют между кадрами, немного увеличьте силу; если текстуры чрезмерно заострены или выглядят переобученными, уменьшите ее. Вместе с LoRA высокой стадии они образуют дополнительную пару.
SplitSigmas (#17) Делит расписание денойзинга на высокие и низкие диапазоны. Перемещение раздела раньше дает более мягкие редактирования, которые сохраняют больше исходного видео, в то время как перемещение его позже дает высокой стадии больше влияния для более сильной замены. Настройте раздел, когда вы изменяете подсказки или силы LoRA, чтобы обе стадии оставались сбалансированными. Этот контроль особенно полезен для редактирования с сохранением движения, зафиксированного камерой.
KSamplerSelect (#27) Выбирает алгоритм семплера, используемый обоими стадиями денойзинга. Некоторые семплеры отдают предпочтение стабильности и временной плавности, в то время как другие подчеркивают детали или скорость. Если вы видите мерцание, попробуйте семплер, известный своей согласованностью; если вам нужна дополнительная четкость, попробуйте алгоритм, который вносит больше разнообразия. Сохраняйте тот же выбор для обеих стадий, чтобы поддерживать предсказуемое поведение.
VHS_VideoCombine (#87) Кодирует декодированные кадры в окончательный MP4, наследуя частоту кадров, сообщаемую VHS_VideoInfo, чтобы скорость воспроизведения соответствовала исходному клипу. Используйте элементы управления именами файлов для организации запусков и включите сохранение метаданных, если вы планируете проверять настройки. Второй экземпляр (#96) выводит визуализацию "бок о бок" для быстрого визуального сравнения. Предоставляется ComfyUI-VideoHelperSuite.
Дополнительные опции#
- Для задач, критичных к идентичности, предоставьте два или три высококачественных эталонных изображения, показывающих согласованные волосы, освещение и выражения. Используйте пакетный ввод, чтобы подать их вместе.
- Держите целевое соотношение сторон близким к исходному видео. Большие несоответствия могут растянуть лица и дестабилизировать движение.
- Если фон или камера дрейфуют, усилите язык в вашей инструкции, который фиксирует позицию камеры и сцены, и укрепите его с помощью краткой отрицательной подсказки.
- Используйте экспорт "бок о бок" при настройке сил LoRA или раздела сигм. Это сокращает время итерации, делая различия очевидными.
- Для более быстрых испытаний ограничьте количество загружаемых кадров, затем увеличьте масштаб, когда вы довольны соответствием идентичности и качеством движения.
Этот рабочий процесс мультимодальной генерации и редактирования видео Bernini разработан для безопасного редактирования: начните с настроек по умолчанию, итеративно работайте над инструкцией и эталонами, затем тонко настройте силы LoRA и раздел сигм для вашего объекта и сцены.
Признания#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы благодарны ByteDance за Bernini, RH-RunningHub за ComfyUI-RH-Bernini и Kosinkadink за ComfyUI-VideoHelperSuite за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- RunningHub/Bernini Multimodal Video Generation and Editing (ComfyUI Workflow)
- Документация / Примечания к выпуску: RunningHub workflow reference
- RunComfy/Cloud Save workflow
- Документация / Примечания к выпуску: RunComfy Cloud Save workflow
- ByteDance/Bernini-R
- GitHub: bytedance/Bernini
- Hugging Face: ByteDance/Bernini-R
- arXiv: arXiv:2605.22344
- Документация / Примечания к выпуску: ByteDance Bernini model source
- Kijai/WanVideo_comfy_fp8_scaled (Bernini assets)
- Hugging Face: Kijai/WanVideo_comfy_fp8_scaled
- Документация / Примечания к выпуску: Kijai Bernini ComfyUI fp8 model assets
- RH-RunningHub/ComfyUI-RH-Bernini
- GitHub: RH-RunningHub/ComfyUI-RH-Bernini
- Документация / Примечания к выпуску: RunComfy Bernini custom nodes
- Kosinkadink/ComfyUI-VideoHelperSuite
- GitHub: Kosinkadink/ComfyUI-VideoHelperSuite
- Документация / Примечания к выпуску: ComfyUI Video Helper Suite
Примечание: Использование указанных моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.