
Gemma 4 Text Generation ComfyUI workflow: texto multimodal com contexto de imagem, vídeo e áudio#
Este workflow Gemma 4 Text Generation ComfyUI é um modelo compacto, pronto para RunComfy, que gera texto de alta qualidade enquanto entende imagens e áudio, com um exemplo de vídeo incluído. É projetado para iteração rápida em prompts multimodais, sumarização de revisões de produtos, análise de conteúdo e protótipos de assistentes leves dentro do ComfyUI.
O gráfico utiliza os nativos TextGenerate e CLIPLoader do ComfyUI para executar o Gemma 4 E4B com entradas opcionais de imagem, áudio e vídeo. Você pode mantê-lo simples para geração de texto puro ou anexar mídia para guiar o raciocínio do modelo e produzir saídas mais ricas.
Modelos principais no workflow Gemma 4 Text Generation ComfyUI#
- Modelo multimodal Gemma 4 E4B Instruct. Fornece geração de texto com compreensão visual e de áudio para respostas concisas, resumos e análises. Os ativos do modelo para ComfyUI estão organizados sob o pacote comunitário Comfy-Org/gemma-4.
- Codificador de texto Gemma 4 E4B (FP8 escalado). O workflow carrega os pesos do codificador embalados
gemma4_e4b_it_fp8_scaled.safetensorsque suportam as entradas de linguagem e multimodais do nóTextGenerate. Link direto do arquivo para usuários locais: `text_encoders/gemma4_e4b_it_fp8_scaled.safetensors`.
Como usar o workflow Gemma 4 Text Generation ComfyUI#
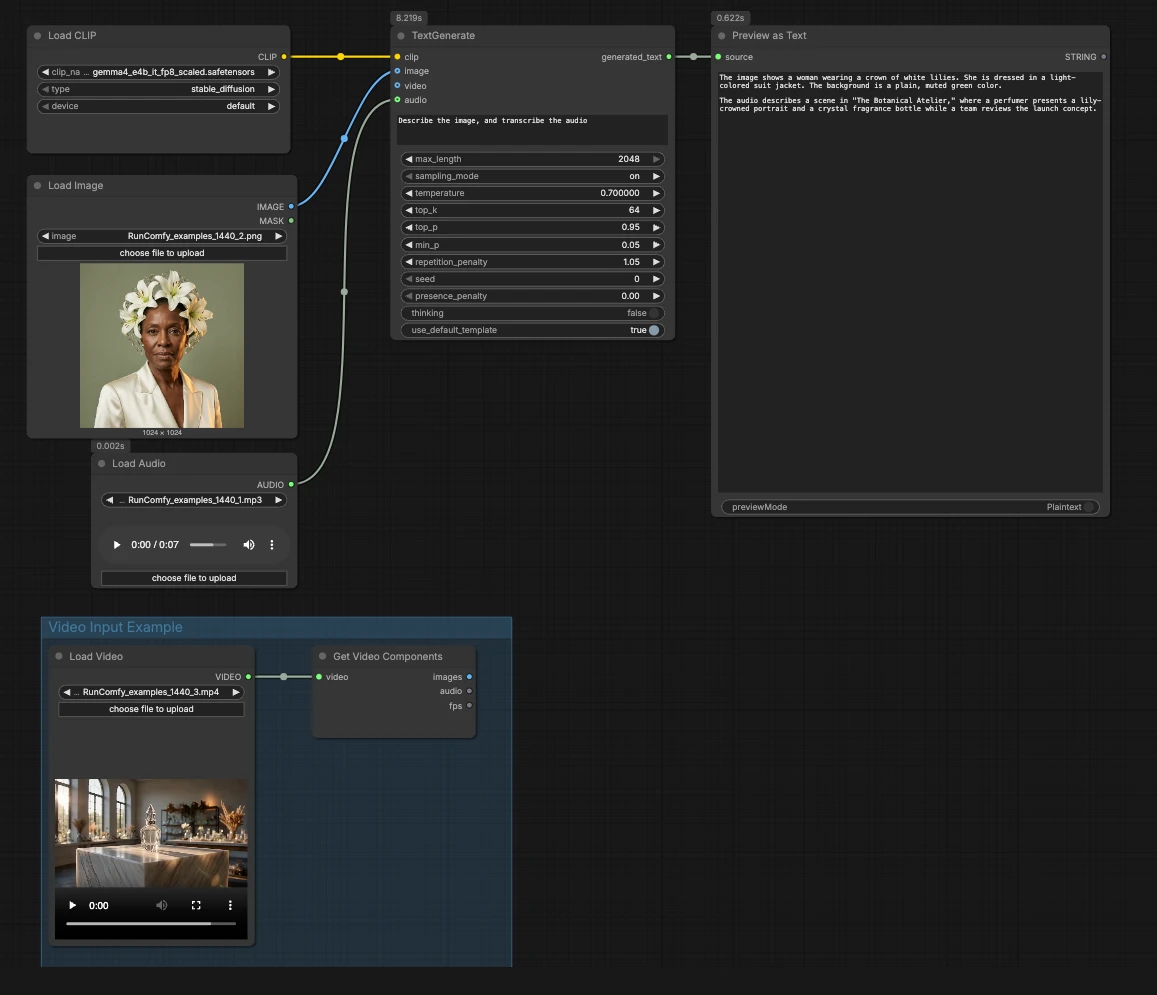
Lógica geral: o workflow carrega o codificador Gemma 4, aceita mídia opcional e então usa TextGenerate para produzir uma resposta que é renderizada em uma pré-visualização. Você pode executá-lo apenas como texto, conectar uma imagem e áudio ou estendê-lo para vídeo conectando o grupo de exemplo.
CLIPLoader(#3) Carrega o codificador de texto Gemma 4 E4B necessário pelo gerador. Ao executar localmente, selecionegemma4_e4b_it_fp8_scaled.safetensorspara que o modelo de linguagem tenha o tokenizador correto e o codificador multimodal. Em ambientes gerenciados, o arquivo correto é geralmente pré-selecionado. Você não precisa ajustar nada aqui uma vez que os pesos escolhidos estejam visíveis.- Entrada de imagem com
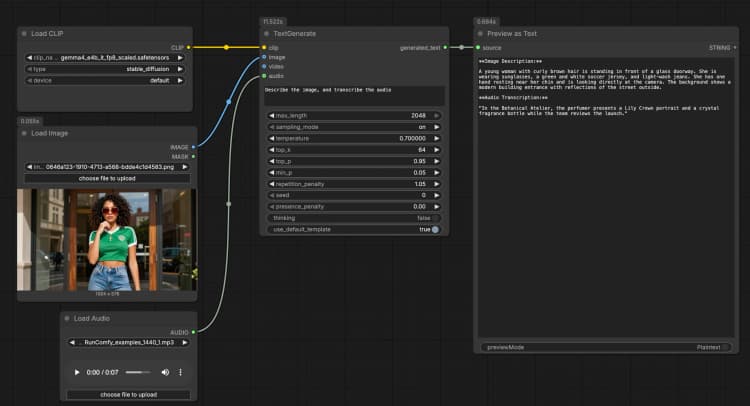
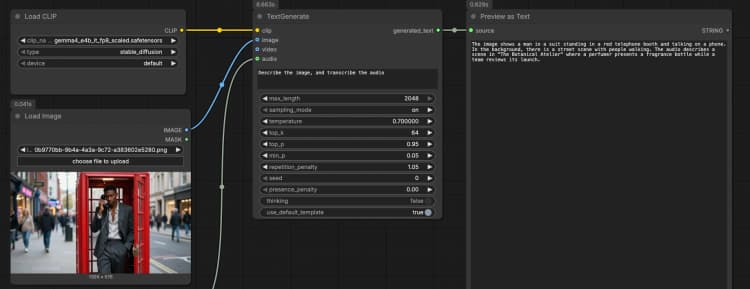
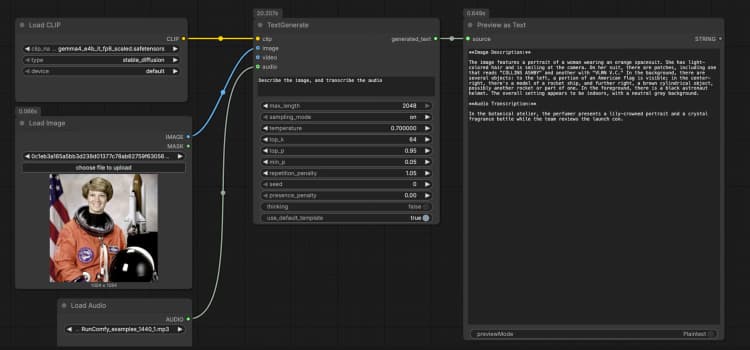
LoadImage(#2) Fornece uma única imagem de referência que o modelo pode descrever, realizar OCR ou analisar como parte do prompt. Troque o arquivo de exemplo pela sua própria captura de tela, gráfico, documento ou foto de produto. A imagem é passada diretamente paraTextGenerate, que condiciona a resposta ao conteúdo visual. Se você deseja um comportamento apenas de texto, deixe este nó desconectado. - Entrada de áudio com
LoadAudio(#5) Adiciona um clipe de áudio para transcrição ou raciocínio consciente de áudio. Substitua o arquivo de amostra por uma nota de voz, trecho de reunião ou gravação de revisão. O fluxo de áudio é alimentado paraTextGeneratepara que você possa pedir ao modelo para transcrever ou resumir junto com a imagem. Para tarefas apenas de texto, mantenha esta entrada vazia. - Grupo de Exemplo de Entrada de Vídeo O grupo "Exemplo de Entrada de Vídeo" mostra como trazer vídeo para o mesmo fluxo usando
LoadVideo(#6) eGetVideoComponents(#7).GetVideoComponentsexpõe quadros representativos e a trilha sonora para que você possa analisar cenas, slides ou texto na tela. Para habilitar a compreensão de vídeo, conecte a saídaimagesà entradaimagedeTextGeneratee a saídaaudioà sua entradaaudio. Isso permite que o workflow Gemma 4 Text Generation ComfyUI raciocine sobre quadros e fala de um clipe. - Geração de texto com
TextGenerate(#1) Este é o nó central que aceita sua instrução mais qualquer mídia anexada e retorna o texto gerado. Forneça um prompt claro, como "Descreva a imagem e transcreva o áudio, depois escreva um resumo de 2 frases." O nó funde contexto visual e de áudio automaticamente, para que você escreva instruções naturais sem marcadores de posição. Você pode manter prompts conversacionais ou orientados para tarefas, dependendo do seu caso de uso. - Visualização de resultados com
PreviewAny(#4) Exibe o texto gerado para que você possa copiá-lo para suas anotações ou ferramentas a jusante. Execute novamente após editar o prompt ou trocar a mídia para comparar saídas rapidamente. Use esta pré-visualização para validar quanto cada modalidade influencia a resposta.
Nós principais no workflow Gemma 4 Text Generation ComfyUI#
TextGenerate(#1) Conduz a saída final e é onde ocorre a maior parte do ajuste. Ajuste quanto tempo a resposta pode ser e quão exploratória deve parecer alterando os tokens máximos e a temperatura de amostragem. Habilite o modo de raciocínio opcional se quiser um pensamento mais passo a passo antes da resposta. Para detalhes de implementação, veja o código fonte do nó de geração de texto do ComfyUI aqui.CLIPLoader(#3) Seleciona e carrega o pacote de codificador Gemma 4 E4B necessário para compreensão de texto e multimodal. Se você mantém modelos localmente, coloque o arquivo em: ComfyUI/models/text_encoders/gemma4_e4b_it_fp8_scaled.safetensors Após a seleção, raramente você precisa revisitar este nó, a menos que mude as variantes do modelo.GetVideoComponents(#7) Útil quando você quer que o modelo considere vídeo. Ele expõe quadros e áudio para que você possa condicionarTextGenerateem ambos. Se o seu clipe for longo, escolha um conjunto menor de quadros para um retorno mais rápido; se precisar de detalhes mais finos, aumente a amostragem de quadros ao custo da velocidade.
Extras opcionais#
- Comece com instruções explícitas como "Considere a imagem e o áudio anexados" para tornar o fundamento multimodal óbvio.
- Para revisões de produtos, peça prós, contras e um veredicto de uma frase para manter as saídas estruturadas.
- Se sua tarefa for puramente textual, desconecte imagem e áudio para execuções mais rápidas.
- Para experimentos em lote, duplique o nó
TextGeneratecom prompts diferentes e compare pré-visualizações lado a lado. - Arquivos e variantes de modelo para Gemma 4 estão organizados no pacote comunitário; explore os ativos disponíveis aqui: Comfy-Org/gemma-4.
Reconhecimentos#
Este workflow implementa e constrói sobre os seguintes trabalhos e recursos. Agradecemos a Comfy-Org pelo pacote de modelo Gemma 4 ComfyUI e codificador de texto E4B, Comfy-Org (mantenedores do ComfyUI) pelo nó embutido TextGenerate, e Comfy.org pelo tutorial oficial do Gemma 4 e blog de lançamento por suas contribuições e manutenção. Para detalhes autorizados, consulte a documentação original e repositórios vinculados abaixo.
Recursos#
- ComfyUI Docs/Gemma 4 ComfyUI workflow example
- GitHub: Comfy-Org/ComfyUI
- Hugging Face: Comfy-Org/gemma-4
- Docs / Release Notes: Gemma 4 ComfyUI workflow example
- ComfyUI Blog/Novos Modelos Open-Source Agora no ComfyUI: VOID, BiRefNet & Gemma 4
- GitHub: Comfy-Org/workflow_templates
- Hugging Face: Comfy-Org/gemma-4
- Docs / Release Notes: Novos Modelos Open-Source Agora no ComfyUI: VOID, BiRefNet & Gemma 4
- Comfy-Org/gemma-4
- Hugging Face: Comfy-Org/gemma-4
- Comfy-Org/gemma-4 E4B text encoder
- Hugging Face: Comfy-Org/gemma-4: gemma4_e4b_it_fp8_scaled.safetensors
- Comfy-Org/ComfyUI TextGenerate node
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.
