
LTX 2.3 무비 빌더 워크플로우: ComfyUI에서의 일관된 멀티 씬, 오디오 인식 영화 제작#
LTX 2.3 무비 빌더 워크플로우는 Qwen/Gemma 프롬프트 인텔리전스를 LTX‑2.3 비디오 모델과 결합하여 일관된 멀티 씬 영화, 스토리 중심 클립, 뮤직 비디오를 제작하는 시네마틱 AI 영화 제작 시스템입니다. 이는 씬 계획, 프롬프트 시퀀싱, 샷 구성을 자동화하면서 캐릭터 정체성, 움직임의 연속성, 시네마틱 페이싱을 유지합니다. 텍스트만으로 결과를 유도하거나 이미지-비디오 시작, 또는 입술 동기화 및 제스처 타이밍을 위한 오디오 참조를 사용할 수 있으며 스타일, 카메라 움직임, 길이, 편집 순서에 대한 창의적 통제력을 유지합니다.
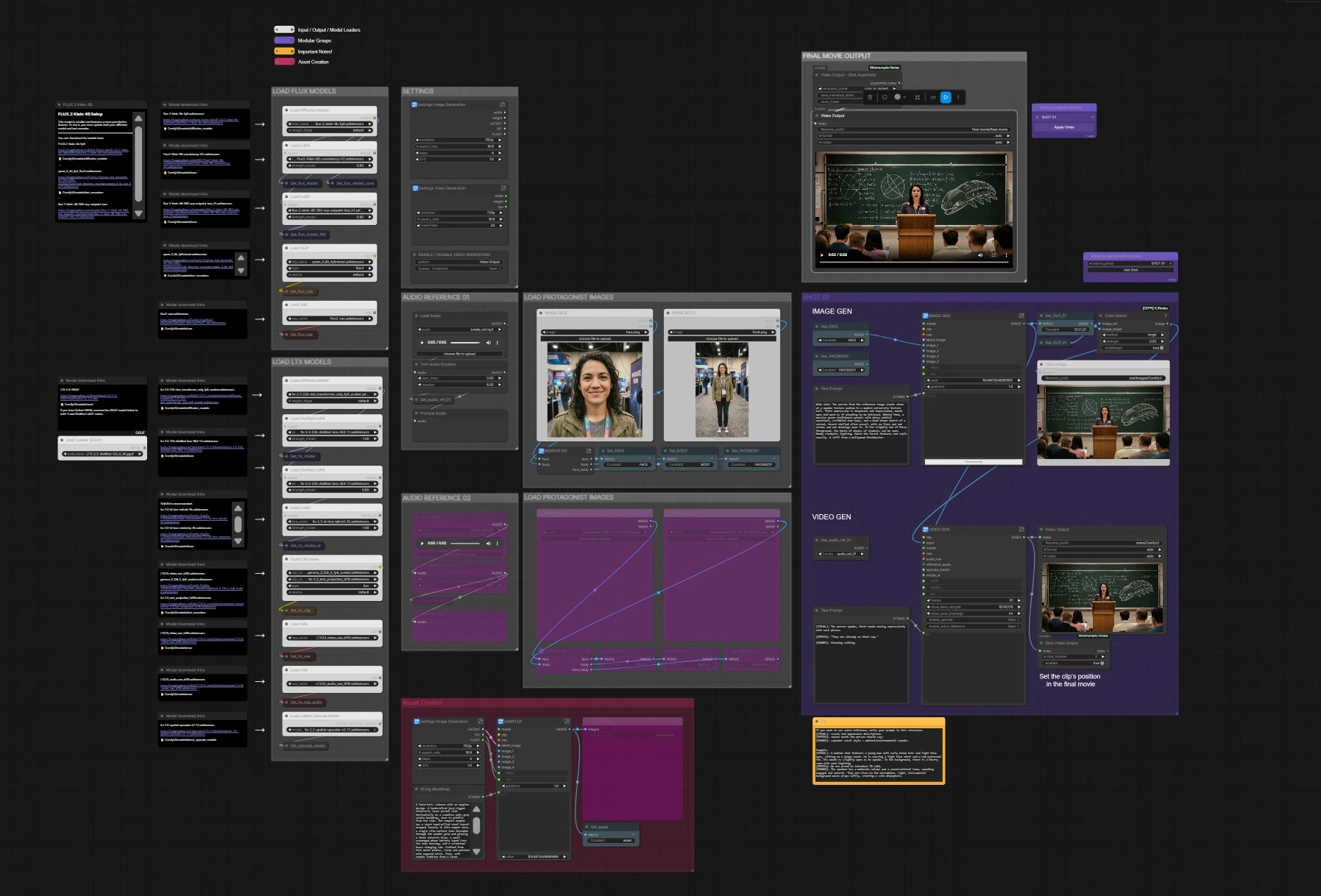
Mickmumpitz.ai가 제작한 이 ComfyUI 그래프는 시작 이미지 생성과 FLUX.2, 구조화된 스피치 프롬프트, 오디오 인식 조건 설정, 선택적 잠재 업스케일링, 최종 샷 어셈블러를 통합합니다. 준비된 촬영 파이프라인이 필요하다면 LTX 2.3 무비 빌더 워크플로우는 최소한의 수동 설정으로 참조 및 스크립트 라인에서 완성된 컷까지 제공합니다.
Comfyui LTX 2.3 무비 빌더 워크플로우의 주요 모델#
- Lightricks LTX‑2.3 22B (transformer only, FP8): 이미지-비디오 및 텍스트-비디오 생성을 위한 주요 텍스트-비디오 백본. Model
- LTX‑2.3 Distilled LoRA 384 1.1: LTX‑2.3 샘플링을 가속화하고 안정화하는 증류 가중치. LoRA
- LTX‑2.3 Spatial Upscaler x2 1.1: 더 깨끗하고 큰 비디오를 위한 선택적 잠재 업스케일러. Model
- LTX‑2.3 Video VAE (BF16) and Audio VAE (BF16): LTX 비디오 및 오디오 잠재를 위한 VAE. Video VAE · Audio VAE
- LTX‑2.3 ID LoRA TalkVid 3k: 말하기 정체성과 입 움직임을 개선하는 정체성 인식 LoRA. LoRA
- Gemma 3 12B IT + LTX‑2.3 Text Projection: LTX 프롬프트에 사용되는 텍스트 인코딩 스택. Encoder · Projection
- FLUX.2‑klein‑9B FP8: 시작 프레임, 소품 및 외관 개발을 위한 빠른 이미지 생성기. Model
- FLUX.2‑klein‑9B Consistency LoRA V2 and 360 ERP Outpaint LoRA: 자산의 시간적 안정성과 넓은 컨텍스트를 개선합니다. Consistency · 360 ERP
- Flux2 VAE and Qwen 3 8B text encoder for FLUX: 자산 생성 경로에 사용되는 인코더. Flux2 VAE · Qwen 3 8B
- Optional low‑VRAM path: LTX‑2.3 GGUF quantized UNet. GGUF
Comfyui LTX 2.3 무비 빌더 워크플로우 사용 방법#
간략하게: 영화 해상도와 fps를 선택하고 주인공 이미지를 로드하며 (얼굴/몸체), 선택적 음성 참조를 추가하고 FLUX로 시작 프레임을 생성하거나 자체 정지를 제공한 후 구조화된 프롬프트를 작성한 다음 샷을 렌더링하세요. 새로운 씬을 위한 샷을 복제하고 최종 영화를 내보내기 위해 어셈블러에서 재정렬합니다.
설정#
비디오 캔버스와 페이싱을 LtxResolutionPicker (#13492)와 Frame Rate (#13480)에서 설정하세요. 전역 샘플링 제어는 Set_steps (#845)와 Set_cfg (#851)에 있으며 자산 생성 및 LTX 비디오 생성 모두에 영향을 미칩니다. 정지 영상만 반복하는 경우 ENABLE / DISABLE VIDEO GENERATION (#13715) 우회로 시간을 절약하세요. 이러한 설정은 각 클립이 얼마나 오래 실행되는지와 최종 타임라인에 어떻게 구성되는지를 정의합니다.
LTX 모델 로드#
LTX 스택은 UNETLoader (#13450), 두 개의 Load Distilled LoRA 노드 (#10370, #10159), 그리고 캐릭터 일관성을 위한 ID LoRA LoraLoaderModelOnly (#10324)로 로드됩니다. 프롬프트는 Gemma + LTX 프로젝션을 사용하여 DualCLIPLoader (#13451)로 인코딩됩니다. 비디오 및 오디오 VAE는 VAELoader (#13449) 및 VAELoader (#13832)를 통해 로드되며, 선택적 잠재 업스케일러는 LatentUpscaleModelLoader (#10349)에서 제공됩니다. 그래프는 이를 재사용 가능한 “Get/Set” 값으로 저장하여 모든 샷이 동일한 모델 팩을 읽습니다.
FLUX 모델 로드#
시작 이미지 생성 및 외관 개발을 위해 FLUX 경로는 Consistency 및 360 ERP LoRA (LoraLoaderModelOnly #6228, #13261)와 함께 UNETLoader (#1992)를 로드합니다. 텍스트는 Qwen을 사용하여 CLIPLoader (#362)로 인코딩되고, 이미지는 VAELoader (#360)로 디코딩됩니다. 이 단계는 독립적이므로 소품, 환경 또는 설립 샷을 신속하게 반복한 후 이를 LTX에 전달할 수 있습니다.
주인공 이미지 로드#
LoadImage (#4867, #1284)와 필요 시 동반 세트 (#13472, #13473)로 얼굴 및 몸체 참조를 추가하세요. 포함된 “REMOVE BG” 도구 체인은 얼굴을 자동 자르고 배경을 제거하여 FACE, BODY, FACEBODY 세트를 생성합니다 (Set_FACE #3093, Set_BODY #3291, Set_FACEBODY #1334). 깨끗한 참조는 샷 간 정체성 유지를 위해 중요합니다.
자산 생성기 (선택 사항)#
워크플로우가 정확한 시작 정지를 생성하도록 하려면 Text Prompt (#13442)에 설명을 작성하고 FLUX 샘플러 KSampler (#13361)를 실행하세요. 결과 프레임은 OUT_01로 캐시되고 SaveImage (#13439)를 통해 저장된 다음, ColorMatch (#13478)를 사용하여 참조와 선택적으로 조화됩니다. 이는 이미지-비디오 패스에 대한 시각적 앵커가 됩니다.
오디오 참조 (선택 사항)#
LoadAudio (#10343)로 음성 또는 공연 큐를 로드하고 TrimAudioDuration (#10344)에서 트림하며 PreviewAudio (#10346)로 미리보기 합니다. 오디오가 Enable Voice Reference (#13320)가 켜져 있을 때 LTXVReferenceAudio (#13329)로 전달되어 입 모양, 구문, 제스처 박자를 안내합니다. 두 번째 참조 슬롯 (AUDIO REFERENCE 02)은 중간 반복에서 테이크를 비교하거나 전환하려는 경우 사용할 수 있습니다.
샷 01#
각 샷은 공유 풀에서 모델 및 설정을 읽은 다음 자산, 프롬프트 및 선택적 오디오를 블렌딩하여 비디오로 만듭니다. Text Prompt (#13384)에 시네마틱 설명 또는 음성 중심 프롬프트를 입력하세요; 포함된 형식 [VISUAL] / [SPEECH] / [SOUNDS]를 사용하여 최상의 결과를 얻으세요. 시작 정지는 LTXVPreprocess (#13308)에서 사전 처리되고 LTXVImgToVideoInplace (#13289)에서 애니메이션화되며, 오디오 조건 설정은 LTXVReferenceAudio (#13329)가 활성화되어 있을 때 제공됩니다. 파이프라인은 두 단계 샘플러 (SamplerCustomAdvanced #13316, #13331)를 실행하며, Enable Upscale (#13322)가 켜져 있을 때 LTXVLatentUpsampler (#13306)로 세부 사항을 개선합니다. CreateVideo (#13310)는 프레임과 오디오를 믹스하며, ShotVideoOutput (#13379) 및 Video Output (#13393)을 통해 샷별 출력을 저장할 수 있습니다.
최종 영화 출력#
도우미 노드 MickmumpitzShotOrder (#8230) 및 MickmumpitzShotDuplicator (#6357)로 샷 순서를 정렬한 다음 Video Output - Shot Assembler (#5598)에서 컷을 조립합니다. 어셈블러는 클립을 자르고 연결하여 하나의 타임라인을 내보내기 위해 준비합니다. Video Output (#5521)로 최종 영화를 렌더링하세요. 더 긴 영화를 만들려면 SHOT 01을 복제하고 프롬프트와 입/출 위치를 조정하여 재수출하세요.
Comfyui LTX 2.3 무비 빌더 워크플로우의 주요 노드#
LTXVImgToVideoInplace (#13289)#
고품질 정지를 시간적으로 일관된 비디오 잠재로 변환하며 정체성과 구성을 유지합니다. FLUX로 만든 시작 또는 자체 참조를 움직임으로 변환하는 데 사용합니다. Text Prompt에서 명확한 씬 방향과 함께 사용하고 비교 가능한 대안을 원할 때 동일한 시드를 유지하세요.
LTXVReferenceAudio (#13329)#
음성 또는 음악 배드에서 타이밍 및 음소 큐를 주입하여 말과 제스처가 자연스럽게 정렬되도록 합니다. [VISUAL], [SPEECH], [SOUNDS]를 분리하는 프롬프트와 함께 사용할 때 최상의 성능을 발휘합니다. Enable Voice Reference를 전환하여 오디오 안내 및 순수 프롬프트 기반 움직임 간 전환할 수 있습니다.
LTXVLatentUpsampler (#13306)#
LTX‑2.3 Spatial Upscaler를 사용하여 잠재 공간에서 세부 사항을 정제하여 더 선명한 텍스처와 가장자리를 제공합니다. 샷이 클로즈업 또는 텍스트 오버레이와 교차될 때 활성화하세요; 외관 개발 중에는 비활성화하여 더 빠르게 반복하세요.
ColorMatch (#13478)#
시작 정지와 참조 출력 간 색상을 일치시켜 씬 간의 연속성을 유지합니다. 여러 FLUX 생성 자산을 합성하거나 조명 설정을 혼합할 때 유용합니다.
KSampler (#13361)#
비디오 단계용 소품, 장소 및 주요 정지를 생성하는 FLUX 자산 생성기입니다. 시드를 잠그면 시퀀스 전반에 걸쳐 일관된 시각적 언어를 유지할 수 있으며, 텍스트를 약간 변경하여 연속성을 깨지 않고 스타일 변화를 탐색할 수 있습니다.
Video Output - Shot Assembler (#5598)#
개별 샷 렌더를 수집하고 단일 컷을 출력합니다. 씬을 재정렬하고, 일관되게 자르고, 한 번에 영화를 내보내는 데 사용합니다.
선택적 추가 기능#
- 그래프의 팁에 표시된 프롬프트 구조를 사용하세요: [VISUAL] 씬 설명, [SPEECH] 정확한 단어, [SOUNDS] 음성 스타일 및 분위기. 이는 LTX 텍스트 및 오디오 인코더가 협력하는 데 도움이 됩니다.
- 얼굴 및 몸체 참조를 모두 제공하고 LTX‑2.3 ID LoRA를 활성화하여 캐릭터 정체성을 유지하세요.
- 빠른 반복을 위해 업스케일러와 음성 참조를 비활성화하고 샷 길이를 줄이며 비디오 우회를 사용하여 시작 프레임만 생성하세요.
- 낮은 VRAM 시스템에서는 LTX‑2.3의 GGUF 빌드를 시도하고 최종 패스까지 추가 LoRA를 쌓는 것을 피하세요. GGUF
- 새로운 씬을 위해 SHOT 01을 복제하고 샷 간 프롬프트를 최소한으로 변경하며 시드를 재사용하여 전체 LTX 2.3 무비 빌더 워크플로우에서 컷 투 컷 톤과 조명을 안정적으로 유지하세요.
감사의 말#
이 워크플로우는 다음 작품 및 리소스를 구현하고 확장합니다. 우리는 Mickmumpitz의 LTX 2.3 무비 빌더 워크플로우 소스에 대한 기여와 유지 보수에 대해 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 저장소를 참조하십시오.
리소스#
- Mickmumpitz/LTX 2.3 Movie Builder Workflow Source
- Docs / Release Notes: mickmumpitz.ai/posts/new-video-free-i-157336696
참고: 참조된 모델, 데이터셋 및 코드의 사용은 해당 저자 및 유지 관리자가 제공하는json
라이선스 및 조건에 따릅니다.