
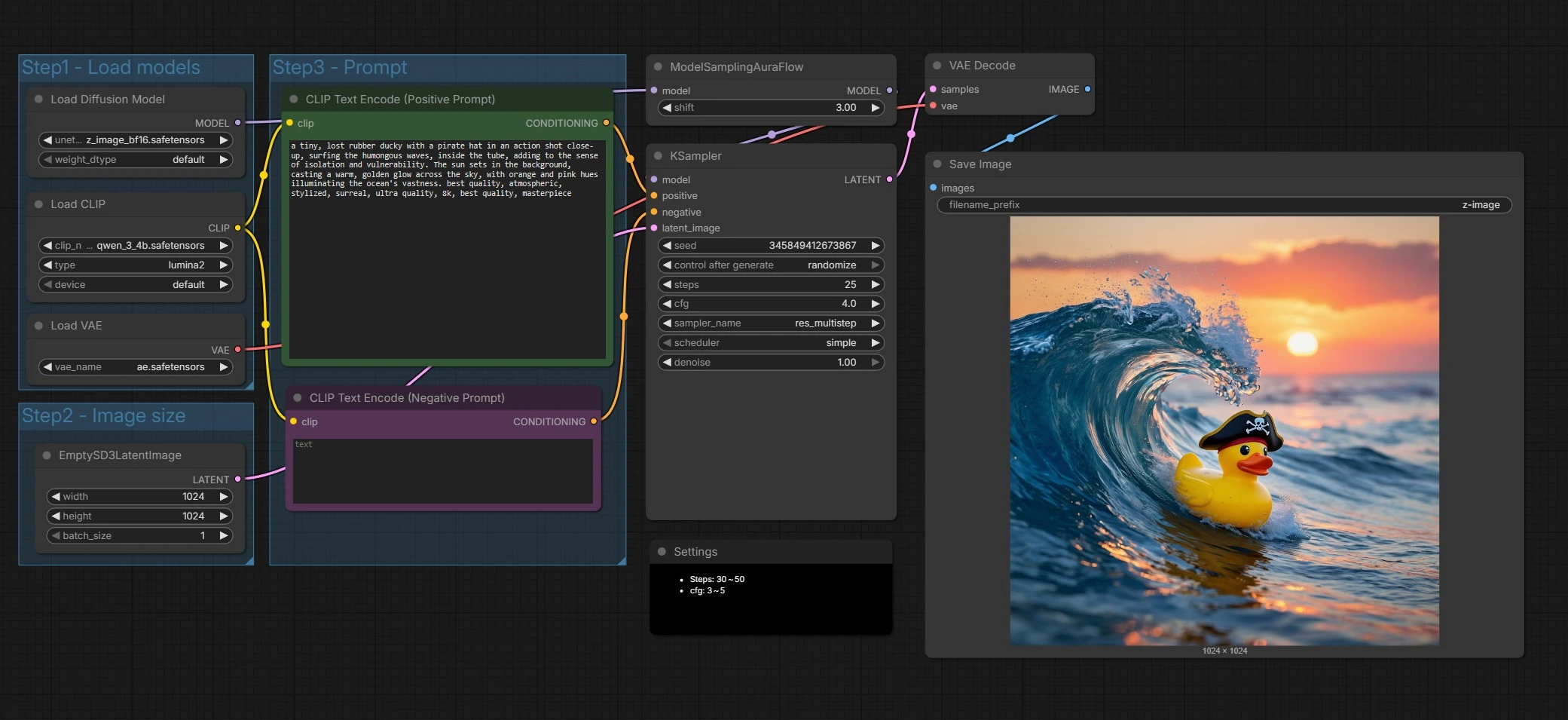
















ComfyUIのためのZ-Imageテキストから画像へのワークフロー#
このComfyUIワークフローは、次世代の拡散トランスフォーマーであるZ-Imageを紹介します。高速で高精度な画像生成を目的として設計されています。約60億のパラメータを持つスケーラブルなシングルストリームアーキテクチャに基づいて構築され、フォトリアリズム、強力なプロンプトの遵守、バイリンガルテキストレンダリングのバランスを保ちます。
初期設定では、Z-Imageベースが一般的なGPUで効率を保ちながら品質を最大化するように設定されています。また、スピードが重要な場合にはZ-Image Turboバリアントとも相性が良く、その構造は画像から画像へのタスク向けにZ-Image Editへの拡張を容易にします。明確なプロンプトをクリーンな結果に変える信頼性のある最小限のグラフが必要な場合、このZ-Imageワークフローは堅実な出発点です。
Comfyui Z-Imageワークフローの主要モデル#
- Z-Image Base拡散トランスフォーマー (bf16)。Z-Imageのシングルストリームトポロジーとプロンプト制御を備えたコアジェネレーターで、潜在を画像に変換します。モデルページ • bf16ウェイト
- Qwen 3 4Bテキストエンコーダー。強力なバイリンガルカバレッジと明確なトークン化でZ-Image用のプロンプトをエンコードします。エンコーダーウェイト
- Z-ImageオートエンコーダーVAE。ピクセル空間とZ-Image潜在空間の間で画像を圧縮し再構築します。VAEウェイト
Comfyui Z-Imageワークフローの使用方法#
大まかに言えば、グラフはZ-Imageコンポーネントをロードし、潜在キャンバスを準備し、ポジティブおよびネガティブプロンプトをエンコードし、Z-Imageに調整されたサンプラーを実行し、結果をデコードして保存します。主にプロンプトを提供し、出力サイズを選択します。残りは合理的なデフォルトに設定されています。
ステップ1 - モデルをロード#
このグループは、Z-Image UNet、Qwen 3 4Bテキストエンコーダー、およびVAEを初期化し、すべてのコンポーネントが整列するようにします。UNETLoader (#66)はデフォルトでZ-Image Baseを指し、忠実性と編集余地を重視します。CLIPLoader (#62)は多言語プロンプトとテキストトークンを適切に処理するQwenベースのエンコーダーを導入します。VAELoader (#63)は後にデコードに使用されるオートエンコーダーを設定します。Z-Image Turboを試したい場合はここでウェイトを交換してください。
ステップ2 - 画像サイズ#
このグループはEmptySD3LatentImage (#68)を介して潜在キャンバスを設定します。生成したい幅と高さを選択し、構図のためにアスペクト比を考慮してください。Z-Imageは一般的なクリエイティブサイズで良好に機能するため、ストーリーボードや配信形式に合わせた寸法を選んでください。サイズが大きいほど詳細と計算コストが増加します。
ステップ3 - プロンプト#
ここで物語を書きます。CLIP Text Encode (Positive Prompt) (#67)ノードはZ-Image用のシーンの説明とスタイルの指示を受け取ります。CLIP Text Encode (Negative Prompt) (#71)はアーティファクトや不要な要素を避けるのに役立ちます。Z-Imageはバイリンガルテキストレンダリングに調整されているため、必要に応じてプロンプトに複数の言語でテキストコンテンツを含めることができます。最も一貫した結果を得るためにプロンプトを具体的かつ視覚的に保ってください。
サンプルとデノイズ#
ModelSamplingAuraFlow (#70)はZ-Imageのシングルストリーム設計に合わせたサンプリングポリシーを適用し、KSampler (#69)はプロンプトに一致する画像にノイズを変換するデノイズプロセスを駆動します。サンプラーはポジティブおよびネガティブな条件付けを潜在キャンバスと組み合わせて、構造と詳細を反復的に洗練します。ここでサンプラー設定を調整して、スピードと品質をトレードオフすることができます。このステージでZ-Imageのプロンプト遵守とテキストの明瞭さが本当に発揮されます。
デコードと保存#
VAEDecode (#65)は最終的な潜在をRGB画像に変換します。SaveImage (#9)はノードに設定されたプレフィックスを使用してファイルを書き込むので、Z-Imageの出力を簡単に見つけて整理できます。これでプロンプトからピクセルへのフルパスが完了します。
Comfyui Z-Imageワークフローの主要ノード#
UNETLoader (#66)#
実際にデノイズを行うZ-Imageバックボーンをロードします。スピードや編集のユースケースを探索する際に別のZ-Imageバリアントにスワップします。バリアントを変更する場合は、エンコーダーとVAEを互換性のあるものに保ち、色やコントラストのシフトを避けてください。
CLIP Text Encode (Positive Prompt) (#67)#
Z-Image用のメインの説明をエンコードします。被写体、照明、カメラ、ムード、および画像上のテキストを指定する簡潔で視覚的なフレーズを書いてください。テキストレンダリングのために、望ましい単語を引用符で囲み、読みやすさを確保するために短く保ちます。
CLIP Text Encode (Negative Prompt) (#71)#
Z-Imageが正しい詳細に集中できるように避けるべきことを定義します。ぼかし、余分な手足、乱雑なタイポグラフィ、またはスタイル外の要素を抑制するために使用します。簡潔で話題に沿ったものにして、構図を過度に制約しないようにしてください。
EmptySD3LatentImage (#68)#
Z-Imageが描画する潜在キャンバスを作成します。最終使用に適した寸法を選択し、効率的なメモリ使用のために64 pxの倍数に保ちます。キャンバスが広かったり高かったりすることは構成と視点に影響を与えるため、プロンプトを適宜調整してください。
ModelSamplingAuraFlow (#70)#
Z-Imageのトレーニングと潜在空間に一致するサンプラープリセットを選択します。代替サンプラーをテストしている場合を除き、これを変更する必要はほとんどありません。安定したアーティファクトのない結果を得るために提供されたままにしておいてください。
KSampler (#69)#
Z-Imageの品質とスピードのトレードオフを制御します。詳細と安定性を高めるためにstepsを増やし、速いドラフトのために減らします。プロンプトの遵守と自然な質感をバランスさせるためにcfgを中程度に保ちます。このグラフの典型的な値はsteps: 30から50、cfg: 3から5です。再現性のために固定seedを設定するか、変動を探索するためにランダム化します。
VAEDecode (#65)#
Z-Imageからの最終的な潜在をRGB画像に変換します。VAEを変更する場合は、モデルファミリーに一致させて色の正確さとシャープさを保ちます。
SaveImage (#9)#
Z-Imageの出力を簡単にカタログ化できるように明確なファイル名プレフィックスで結果を書き込みます。実験、モデルバリアント、またはアスペクト比を分けるためにプレフィックスを調整します。
オプションのエクストラ#
- 急速なアイデアのためにZ-Image Turboを使用し、その後Z-Image Baseに切り替えて最終レンダリングのためにステップを増やします。
- バイリンガルプロンプトや画像上のテキストの場合、プロンプト内で言葉を短くし、コントラストを高くしてZ-Imageが鮮明なタイポグラフィをレンダリングできるようにします。
- 小さなプロンプト編集を比較する際には、シードを固定し、変更を反映するようにし、ノイズを新たにしないようにします。
- 過剰な彩度やハローが見られる場合は、
cfgを少し下げるかネガティブプロンプトを強化してバランスを取り戻してください。
謝辞#
このワークフローは以下の作業とリソースに基づいて実装されています。Z-Image Day-0 ComfyUIワークフローテンプレートの提供と保守に対して、Comfy-Orgに感謝の意を表します。権威ある詳細については、以下のオリジナルドキュメントおよびリポジトリを参照してください。
リソース#
- Comfy-Org/ComfyUIにおけるZ-Image Day-0サポート
- GitHub: Comfy-Org/workflow_templates
- ドキュメント / リリースノート: ソース
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者および保守者によって提供されるライセンスおよび条件に従います。


