
Wan 2.1 Ditto video restyle workflow for ComfyUI#
This workflow applies Wan 2.1 Ditto to restyle any input video while preserving scene structure and motion. It is designed for editors and creators who want cinematic, artistic, or experimental looks with strong temporal consistency. You load a clip, describe the target look, and Wan 2.1 Ditto produces a clean stylized render plus an optional side‑by‑side comparison for quick review.
The graph pairs the Wan 2.1 text‑to‑video backbone with Ditto’s style transfer at the model level, so changes happen coherently across frames rather than as frame‑by‑frame filters. Common use cases include anime conversions, pixel art, claymation, watercolor, steampunk, or sim‑to‑real edits. If you already generate content with Wan, this Wan 2.1 Ditto workflow slots directly into your pipeline for dependable, flicker‑free video styling.
Key models in Comfyui Wan 2.1 Ditto workflow#
- Wan2.1‑T2V‑14B text‑to‑video model. Serves as the generative backbone that synthesizes temporally consistent motion given text and visual conditioning.
- Wan 2.1 VAE. Encodes and decodes video latents so the sampler can work in a compact space and then reconstruct full‑resolution frames reliably.
- mT5‑XXL text encoder. Converts prompts to rich language embeddings that steer scene content and style. For background on mT5, see the paper by Xue et al. mT5: A Massively Multilingual Pre‑trained Text‑to‑Text Transformer.
- Ditto stylization model for Wan 2.1. Provides robust, global restyling with strong temporal coherence. The Ditto approach and model files are documented here: EzioBy/Ditto.
- Optional LoRA for Wan 2.1 14B. Adds lightweight style or behavior shifts without retraining the base model, following the LoRA method described in Hu et al., 2021.
How to use Comfyui Wan 2.1 Ditto workflow#
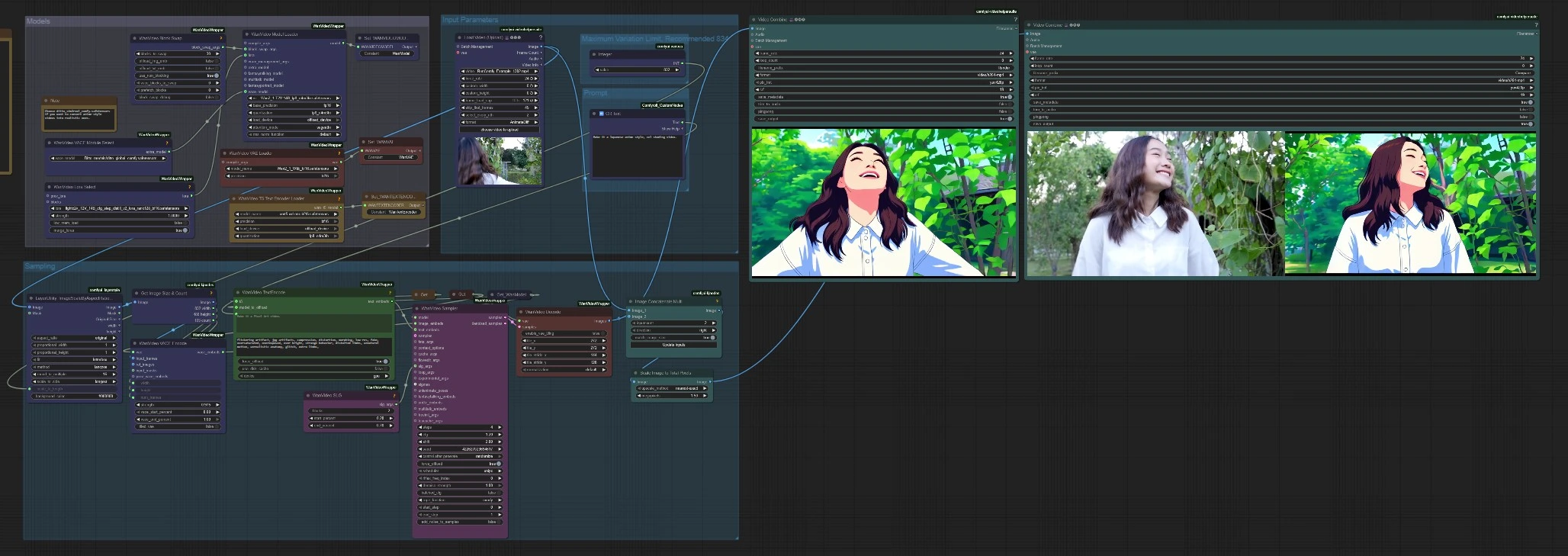
The workflow runs in four stages: load models, prepare the input video, encode text and visuals, then sample and export. Groups operate in sequence to produce both a stylized render and an optional side‑by‑side comparison.
Models#
This group prepares everything Wan 2.1 Ditto needs. The base backbone is loaded with WanVideoModelLoader (#130) and paired with the WanVideoVAELoader (#60) and LoadWanVideoT5TextEncoder (#80). The Ditto component is selected with WanVideoVACEModelSelect (#128), which points the backbone to the dedicated Ditto stylization weights. If you need a stronger transformation, you can attach a LoRA with WanVideoLoraSelect (#122). WanVideoBlockSwap (#68) is available for memory management so larger models can run smoothly on limited VRAM.
Input parameters#
Load your source clip with VHS_LoadVideo (#101). The frames are then resized for consistent geometry using LayerUtility: ImageScaleByAspectRatio V2 (#76), which preserves aspect while targeting a long‑side resolution controlled by a simple integer input JWInteger (#89). GetImageSizeAndCount (#65) reads the prepared frames and forwards width, height, and frame count to downstream nodes so Wan 2.1 Ditto samples the correct spatial size and duration. A small prompt helper CR Text (#104) is included if you prefer to author the prompt in its own field. The group titled “Maximum Variation Limit” reminds you to keep the long‑side pixel target in a practical range for consistent results and stable memory use.
Sampling#
Conditioning happens in two parallel lanes. WanVideoTextEncode (#111) turns your prompt into text embeddings that define the intent and style. WanVideoVACEEncode (#126) encodes the prepared video into visual embeddings that preserve structure and motion for editing. An optional guidance module WanVideoSLG (#129) controls how the model balances style and content through the denoising trajectory. WanVideoSampler (#119) then fuses the Wan 2.1 backbone with Ditto, the text embeddings, and the visual embeddings to generate stylized latents. Finally, WanVideoDecode (#87) reconstructs frames from latents to produce the stylized sequence with the temporal consistency that Wan 2.1 Ditto is known for.
Outputs and comparisons#
The primary export uses VHS_VideoCombine (#95) to save the Wan 2.1 Ditto render at your selected frame rate. For quick review, the graph joins original and stylized frames using ImageConcatMulti (#94), sizes the comparison with ImageScaleToTotalPixels (#133), and writes a side‑by‑side movie via VHS_VideoCombine (#100). You will typically get two videos in the output folder: a clean stylized render and a comparison clip that helps stakeholders approve or iterate faster.
Prompt ideas#
You can begin with short, clear prompts and iterate. Examples that work well with Wan 2.1 Ditto:
- Make it a Japanese anime style, cel shading video.
- Make it a Pixel Art video.
- Make it a pencil sketch style video.
- Make it a Claymation video.
- Make it a watercolor drawing style video.
- Make it Steampunk style with gears, pipes and brass details.
- Make it Cyberpunk style with neon and futuristic implants.
- Make it a Ukiyo‑e style video.
- Make it a Renaissance art style video.
- Make it a drawing by Van Gogh.
- Turn it into the LEGO style.
- Turn it into the Ghibli style.
- Turn it into the 3D Chibi style.
- Turn it into the Paper Cutting style.
Key nodes in Comfyui Wan 2.1 Ditto workflow#
WanVideoVACEModelSelect (#128) Choose which Ditto weights to use for stylization. The default global Ditto model is a balanced choice for most footage. If your goal is anime‑to‑real conversion, select the sim‑to‑real Ditto variant referenced in the node note. Switching Ditto variants changes the character of the restyle without touching other settings.
WanVideoVACEEncode (#126) Builds the visual conditioning from your input frames. The key controls are width, height, and num_frames, which should match the prepared video for best results. Use strength to adjust how assertively Ditto’s style influences the edit, and vace_start_percent and vace_end_percent to limit when conditioning applies across the diffusion trajectory. Enable tiled_vae on very large resolutions to reduce memory pressure.
WanVideoTextEncode (#111) Encodes positive and negative prompts via the mT5‑XXL encoder to guide style and content. Keep positive prompts concise and descriptive, and use negatives to suppress artifacts such as flicker or over‑saturation. The force_offload and device options let you trade speed for memory if you are running large models.
WanVideoSampler (#119) Runs the Wan 2.1 backbone with Ditto stylization to generate the final latents. The most impactful settings are steps, cfg, scheduler, and seed. Use denoise_strength when you want to preserve more of the original structure, and keep slg_args connected to balance content fidelity against style strength. Increasing steps or guidance may improve detail at the cost of time.
ImageScaleByAspectRatio V2 (#76) Sets a stable target size for all frames before conditioning. Drive the long‑side target with the standalone integer so you can test small, fast previews and then increase resolution for final renders. Keep the scale consistent between iterations to make A/B comparisons meaningful.
VHS_LoadVideo (#101) and VHS_VideoCombine (#95, #100) These nodes handle decoding and encoding. Match frame rates to the source when you care about timing. The comparison writer is useful during exploration and can be disabled for final exports if you only want the stylized result.
Optional extras#
- For anime‑to‑real edits, pick the sim‑to‑real Ditto variant in
WanVideoVACEModelSelectbefore sampling. - Start with short prompts like “Make it watercolor drawing style” and refine with 1 or 2 descriptors. Long lists tend to dilute style strength.
- Use negative prompts to reduce flicker, compression artifacts, and over‑bright highlights when pushing strong looks.
- Keep your long‑side resolution consistent across iterations to stabilize results and make seeds reproducible.
- When VRAM is tight, enable model offloading and tiling options, or preview at a smaller long‑side value before rendering at full size.
This Wan 2.1 Ditto workflow makes high‑quality video restyling predictable and fast, with clean prompts, coherent motion, and outputs ready for immediate review or delivery.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge EzioBy for Wan 2.1 Ditto Source for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- EzioBy/Wan 2.1 Ditto Source
- GitHub: EzioBy/Ditto
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.