
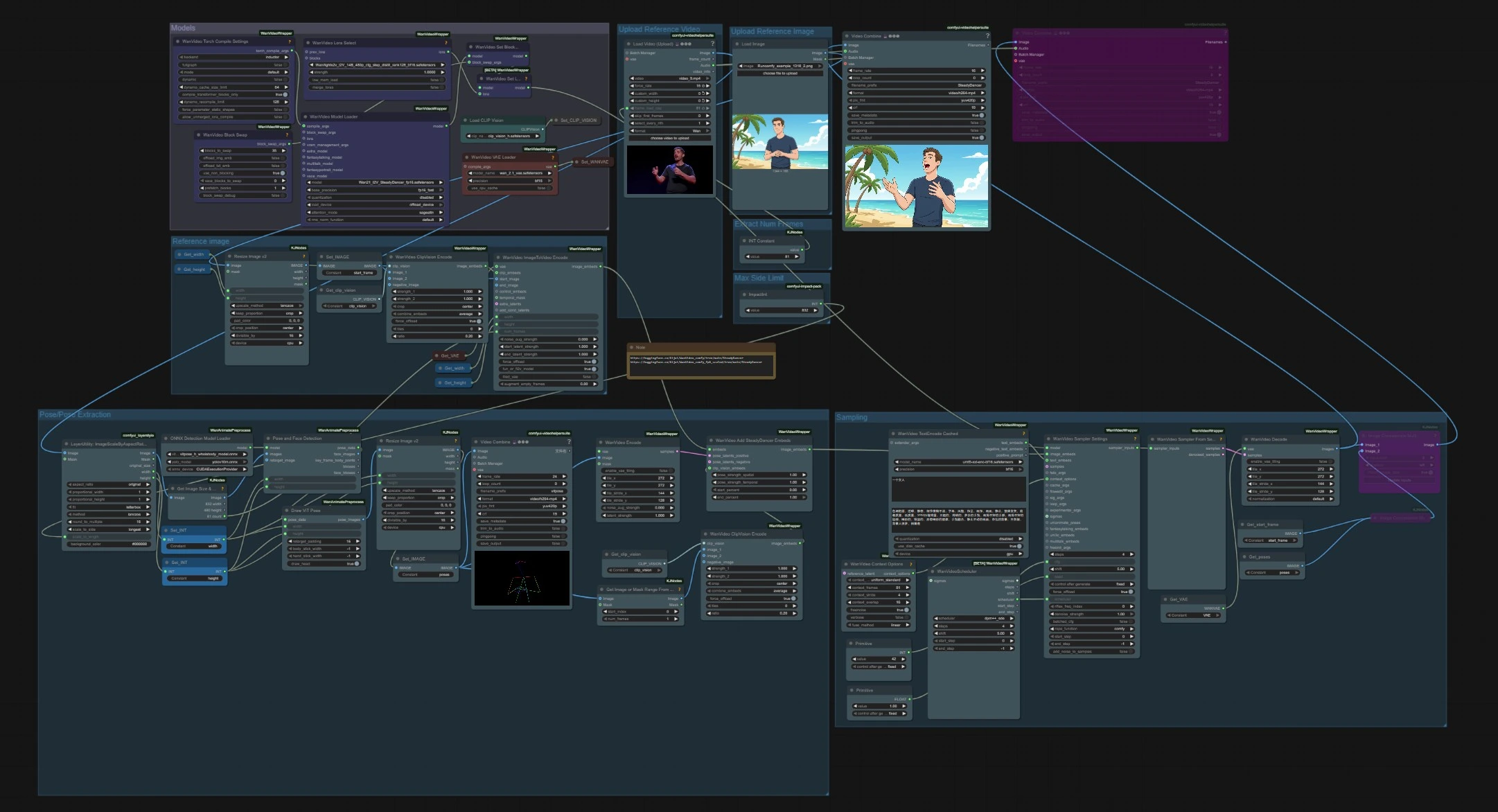
SteadyDancer画像からビデオへのポーズアニメーションワークフロー#
このComfyUIワークフローは、単一の参照画像を別のポーズソースの動きによって駆動される一貫したビデオに変換します。SteadyDancerの画像からビデオへのパラダイムに基づいて構築されており、最初のフレームが入力画像のアイデンティティと外観を保存しながら、シーケンスの残りはターゲットの動きに従います。グラフはSteadyDancer固有の埋め込みとポーズパイプラインを通じてポーズと外観を調和させ、滑らかでリアルな全身の動きを強い時間的一貫性で生成します。
SteadyDancerは、人間のアニメーション、ダンス生成、キャラクターやポートレートを生き生きとさせるのに理想的です。静止画像とモーションクリップを一つずつ提供し、ComfyUIパイプラインがポーズの抽出、埋め込み、サンプリング、デコードを処理して共有可能なビデオを提供します。
Comfyui SteadyDancerワークフローの主要モデル#
- SteadyDancer。アイデンティティを保持する画像からビデオへの研究モデルで、条件調整メカニズムとシナジスティックポーズモジュレーションを備えています。ここではコアI2Vメソッドとして使用されています。 GitHub
- Wan 2.1 I2V SteadyDancerウェイト。ComfyUI用に移植されたチェックポイントで、Wan 2.1スタック上でSteadyDancerを実装します。 Hugging Face: Kijai/WanVideo_comfy (SteadyDancer) と Kijai/WanVideo_comfy_fp8_scaled (SteadyDancer)
- Wan 2.1 VAE。パイプライン内での潜在エンコードとデコードに使用されるビデオVAE。上記のHugging FaceのWanVideoポートに含まれています。
- OpenCLIP CLIP ViT‑H/14。参照画像から強力な外観埋め込みを抽出するビジョンエンコーダー。 Hugging Face
- ViTPose‑H WholeBody (ONNX)。体、手、顔の高品質なキーポイントモデルで、駆動ポーズシーケンスを導出します。 GitHub
- YOLOv10 (ONNX)。多様なビデオでのポーズ推定の前に人物の位置特定を改善する検出器。 GitHub
- umT5‑XXLエンコーダー。参照画像に沿ったスタイルやシーンガイダンス用のオプションのテキストエンコーダー。 Hugging Face
Comfyui SteadyDancerワークフローの使用方法#
ワークフローには、サンプリングで合流する2つの独立した入力があります: アイデンティティ用の参照画像と動き用の駆動ビデオです。モデルは最初にロードされ、ポーズは駆動クリップから抽出され、SteadyDancerの埋め込みがポーズと外観をブレンドして生成とデコードを行います。
モデル#
このグループは、グラフ全体で使用されるコアウェイトをロードします。WanVideoModelLoader (#22) はWan 2.1 I2V SteadyDancerチェックポイントを選択し、注意と精度の設定を処理します。WanVideoVAELoader (#38) はビデオVAEを提供し、CLIPVisionLoader (#59) はCLIP ViT‑Hビジョンバックボーンを準備します。高度なユーザーがメモリ動作を変更したり、追加のウェイトをアタッチしたい場合のために、LoRA選択ノードとBlockSwapオプションがあります。
参照ビデオのアップロード#
VHS_LoadVideo (#75) を使用してモーションソースをインポートします。このノードはフレームとオーディオを読み込み、ターゲットフレームレートを設定したり、フレーム数を制限したりできます。クリップはダンスやスポーツの動きなど、あらゆる人間の動きが可能です。ビデオストリームはアスペクト比スケーリングとポーズ抽出に流れます。
フレーム数の抽出#
単純な定数で駆動ビデオからロードされるフレーム数を制御します。これにより、ポーズの抽出と生成されたSteadyDancer出力の長さが制限されます。シーケンスを長くするには増やし、迅速に反復するには減らします。
最大サイド制限#
LayerUtility: ImageScaleByAspectRatio V2 (#146) はアスペクト比を保持しながらフレームをスケーリングし、モデルのストライドとメモリ予算に適合させます。あなたのGPUと望ましい詳細レベルに適した長辺制限を設定します。スケーリングされたフレームは下流の検出ノードで使用され、出力サイズの参照として使用されます。
ポーズ/ポーズ抽出#
スケーリングされたフレームで人物検出とポーズ推定を実行します。PoseAndFaceDetection (#89) はYOLOv10とViTPose‑Hを使用して人とキーポイントを堅牢に見つけます。DrawViTPose (#88) は動きのクリーンなスティックフィギュア表現を描画し、ImageResizeKJv2 (#77) は生成キャンバスに一致するように結果のポーズ画像をサイズ変更します。WanVideoEncode (#72) はポーズ画像を潜在変数に変換し、SteadyDancerが外観信号と戦わずに動きを調整できるようにします。
参照画像のアップロード#
SteadyDancerでアニメーション化したいアイデンティティ画像をロードします。画像は、移動させたい被写体を明確に示している必要があります。最も忠実な転送を行うために、駆動ビデオと広く一致するポーズとカメラアングルを使用します。フレームは埋め込みのために参照画像グループに転送されます。
参照画像#
静止画像はImageResizeKJv2 (#68) でリサイズされ、Set_IMAGE (#96) で開始フレームとして登録されます。WanVideoClipVisionEncode (#65) は、アイデンティティ、衣服、粗いレイアウトを保持するCLIP ViT‑H埋め込みを抽出します。WanVideoImageToVideoEncode (#63) は、SteadyDancerのI2V条件付けを準備するために、開始フレームとともに幅、高さ、フレーム数をパックします。
サンプリング#
ここで外観と動きが出会い、ビデオを生成します。WanVideoAddSteadyDancerEmbeds (#71) はWanVideoImageToVideoEncodeから画像条件付けを受け取り、ポーズ潜在変数とCLIPビジョン参照を追加し、SteadyDancerの条件調整を可能にします。時間的一貫性のためにWanVideoContextOptions (#87) でコンテキストウィンドウとオーバーラップが設定されます。オプションで、WanVideoTextEncodeCached (#92) はスタイルのニュアンスを追加するためのumT5テキストガイダンスを追加します。WanVideoSamplerSettings (#119) とWanVideoSamplerFromSettings (#129) はWan 2.1モデルで実際のノイズ除去ステップを実行し、その後WanVideoDecode (#28) が潜在変数をRGBフレームに戻します。最終ビデオはVHS_VideoCombine (#141, #83) で保存されます。
Comfyui SteadyDancerワークフローの主要ノード#
WanVideoAddSteadyDancerEmbeds (#71)#
このノードはグラフのSteadyDancerの心臓部です。画像条件付けをポーズ潜在変数とCLIPビジョンキューと融合させ、最初のフレームがアイデンティティをロックしながら自然に動きが展開されます。pose_strength_spatialを調整して、四肢が検出されたスケルトンにどれだけ緊密に従うかを制御し、pose_strength_temporalで時間を通じた動きの滑らかさを調整します。シーケンス内でポーズ制御が適用される範囲を制限するために、start_percentとend_percentを使用してより自然なイントロとアウトロを作成します。
PoseAndFaceDetection (#89)#
駆動ビデオでYOLOv10検出とViTPose‑Hキーポイント推定を実行します。小さな四肢や顔がポーズから外れる場合は、上流で入力解像度を上げるか、遮蔽が少なく照明が良好な映像を選択してください。複数の人がいる場合、ターゲットの被写体をフレーム内で最大に保ち、検出器とポーズヘッドが安定するようにします。
VHS_LoadVideo (#75)#
モーションソースのどの部分を使用するかを制御します。フレームキャップを増やして長い出力を得たり、迅速にプロトタイプ化するためにそれを下げたりします。force_rate入力はポーズの間隔を生成レートに合わせ、オリジナルクリップのFPSが異常な場合にスタッターを減らすのに役立ちます。
LayerUtility: ImageScaleByAspectRatio V2 (#146)#
選択した長辺制限内でアスペクト比を保持し、割り切れるサイズにバケッティングします。ここでのスケールを生成キャンバスに合わせ、SteadyDancerがアップサンプリングや積極的なクロップを行う必要がないようにします。ソフトな結果やエッジアーティファクトが見られる場合は、モデルのネイティブトレーニングスケールに長辺を近づけてクリーンなデコードを得ます。
WanVideoSamplerSettings (#119)#
Wan 2.1サンプラーのノイズ除去プランを定義します。schedulerとstepsが全体の品質と速度を設定し、cfgが画像とプロンプトへの従順性と多様性をバランスします。seedは再現性をロックし、denoise_strengthは参照画像の外観により近づけたい場合に下げることができます。
WanVideoModelLoader (#22)#
Wan 2.1 I2V SteadyDancerチェックポイントをロードし、精度、注意実装、デバイス配置を処理します。安定性のためにこれらを設定されたままにしておきます。高度なユーザーは、動作を変更したり、計算コストを軽減するためにI2V LoRAをアタッチすることができます。
オプションの追加#
- 明るく、よく照らされた参照画像を選択してください。駆動ビデオのカメラに似た正面またはわずかに角度のついたビューが、SteadyDancerのアイデンティティをより信頼性高く保持します。
- 単一の顕著な被写体と最小限の遮蔽を持つモーションクリップを選びます。忙しい背景や速いカットはポーズの安定性を低下させます。
- 手足が揺れる場合は、
WanVideoAddSteadyDancerEmbedsでポーズの時間的強度をわずかに増やすか、ビデオのFPSを上げてポーズを密にします。 - 長いシーンの場合は、コンテキストを重ねてセグメントごとに処理し、出力を縫い合わせます。これによりメモリ使用量を合理的に保ち、時間的な連続性を維持します。
- 内蔵のプレビューモザイクを使用して、生成されたフレームを開始フレームやポーズシーケンスと比較しながら設定を調整します。
このSteadyDancerワークフローは、静止画像からアイデンティティを保持したまま忠実なポーズ駆動ビデオへの実用的なエンドツーエンドの道を提供します。
謝辞#
このワークフローは以下の作品やリソースを実装し、それに基づいて構築されています。MCG-NJUのSteadyDancerに対する貢献とメンテナンスに心より感謝します。権威ある詳細については、以下にリンクされたオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- MCG-NJU/SteadyDancer
- GitHub: MCG-NJU/SteadyDancer
- Hugging Face: MCG-NJU/SteadyDancer-14B
- arXiv: arXiv:2511.19320
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者および管理者によって提供されるライセンスと条件に従います。
