






Flux Kontext Zoom Out LoRA | ComfyUI Workflow#
This ComfyUI workflow creates a clean zoomed-out view of any input image by extending the canvas and naturally continuing the scene, while preserving the subject’s position and look. It is built around Flux Kontext and a purpose-built LoRA so you can "pull back the camera" without warping faces, textures, or perspective. If you want a fast, reliable way to enlarge framing for thumbnails, product photos, portraits, or cinematic stills, this Flux Kontext Zoom Out LoRA workflow is for you.
At its core, the graph loads a Flux Kontext UNet, applies the Flux Kontext Zoom Out LoRA, encodes your image to a reference latent, and samples a wider composition guided by a prompt explicitly designed for zoom-out integrity. The result is a seamless expansion that matches original lighting, style, and geometry.
Key models in Comfyui Flux Kontext Zoom Out LoRA workflow#
- Flux 1 Kontext UNet. The diffusion backbone used here is a Kontext-aware Flux 1 variant prepared for ComfyUI (
flux1-dev-kontext_fp8_scaled.safetensors). It captures long-range structure and scene layout needed for realistic outpainting. Model pack: Comfy-Org/flux1-kontext-dev_ComfyUI. - Flux Kontext Zoom Out LoRA. A lightweight adapter that conditions the model to extend borders convincingly while keeping the visible subject unchanged. Repository: reverentelusarca/flux-kontext-zoom-out-lora.
- Dual text encoders for Flux. The graph uses CLIP-L and T5-XXL encoders tuned for Flux to interpret prompts with high fidelity. Text encoders: comfyanonymous/flux_text_encoders.
- AE VAE. A fast, high-quality autoencoder used for encode/decode steps (
ae.safetensors). Source: Comfy-Org/Lumina_Image_2.0_Repackaged.
How to use Comfyui Flux Kontext Zoom Out LoRA workflow#
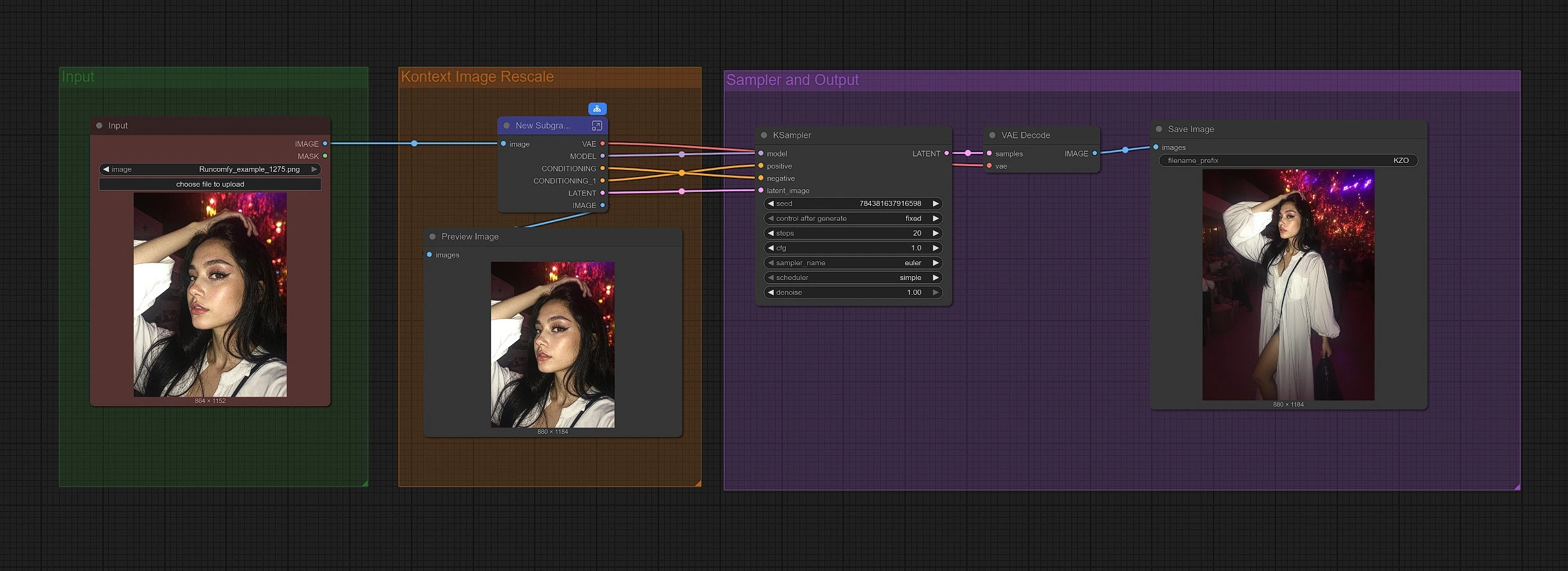
This workflow is organized into three groups. Start by loading your image, then the graph rescales it for Kontext zoom-out, and finally sampling reconstructs a wider frame and saves the result.
Group: Input#
Load your source image via LoadImage (#190). The default positive prompt in CLIP Text Encode (Positive Prompt) (#6) is crafted to preserve the subject and expand the canvas evenly in all directions. You can keep that prompt as is for faithful zoom-outs or lightly tailor it to your scene’s style. The DualCLIPLoader (#38) is prewired with CLIP-L and T5-XXL so text conditioning is ready out of the box.
Group: Kontext Image Rescale#
FluxKontextImageScale (#42) prepares the image for zoom-out by resizing and padding in a way that Kontext models handle gracefully. This staging step helps the model understand where to extend content and how to keep perspective and lighting consistent. The scaled image is then encoded by VAEEncode (#124) so the sampler works from a latent that still “remembers” the original framing.
Group: Sampler and Output#
The model stack is assembled by UNETLoader (#37) and LoraLoaderModelOnly (#191), which applies the Flux Kontext Zoom Out LoRA to the base model. ReferenceLatent (#177) uses your encoded image as a structural anchor so the subject remains unchanged as the borders grow. FluxGuidance (#35) shapes how strongly the reference influences generation; higher values increase faithfulness while lower values allow slightly more novel fill. KSampler (#31) performs the actual diffusion pass, and VAEDecode (#8), PreviewImage (#173), and SaveImage (#136) display and save the final zoomed-out image.
Key nodes in Comfyui Flux Kontext Zoom Out LoRA workflow#
FluxKontextImageScale (#42)#
Prepares the input by scaling and framing for context-aware outpainting. Use it as the only place to change how much canvas you want to add. If you need more breathing room, increase the scale-out amount; if edges look too new, reduce it to keep more of the original pixels.
LoraLoaderModelOnly (#191)#
Loads and applies kontext/zoomout-fal-v1.safetensors onto the Flux 1 Kontext UNet. If your outputs look under- or over-biased, adjust the LoRA strength here. Keep changes modest to preserve the Zoom Out LoRA’s intended behavior.
ReferenceLatent (#177)#
Locks composition and identity by conditioning the sampler on the VAE-encoded original. If you see subtle drift in subject pose or scale, route conditioning through this node as provided and avoid removing it. Pairing this with a neutral or minimal prompt maximizes fidelity.
FluxGuidance (#35)#
Controls how much the reference and prompt guide the sampler. Raise guidance when the extended areas mismatch lighting or perspective; lower it if you want slightly more creative background fill. Treat it as a balance knob between strict preservation and organic continuation.
Optional extras#
- Keep the positive prompt minimal. The included prompt is tuned for this Flux Kontext Zoom Out LoRA and usually needs no edits.
- If borders show tiny seams, try a smaller scale-out in
FluxKontextImageScaleor a slightly higherFluxGuidance. - For stylistic scenes, add 1–2 words to the prompt describing tone or medium, not subject shape, to avoid changing the main figure.
- Save iterative variants by changing seed only; this lets you pick the cleanest continuation without altering composition.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge reverentelusarca for Flux Kontext Zoom Out LoRA for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- reverentelusarca/Flux Kontext Zoom Out LoRA
- Hugging Face: Flux Kontext Zoom Out LoRA
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.


