
SkyReels V3 ComfyUI: アイデンティティを忠実に再現する画像、ビデオ、音声からのビデオ作成#
SkyReels V3 ComfyUIは、SkyReels V3のマルチモーダルビデオモデルをComfyUIに導入するプロダクション対応のワークフローで、静止画像をアニメーション化したり、既存のショットを拡張したり、正確なリップシンクで音声駆動の話すアバターを構築できます。これは、シネマティックな動き、強い対象のアイデンティティ、時間的な一貫性を求めるクリエイター向けに設計されています。
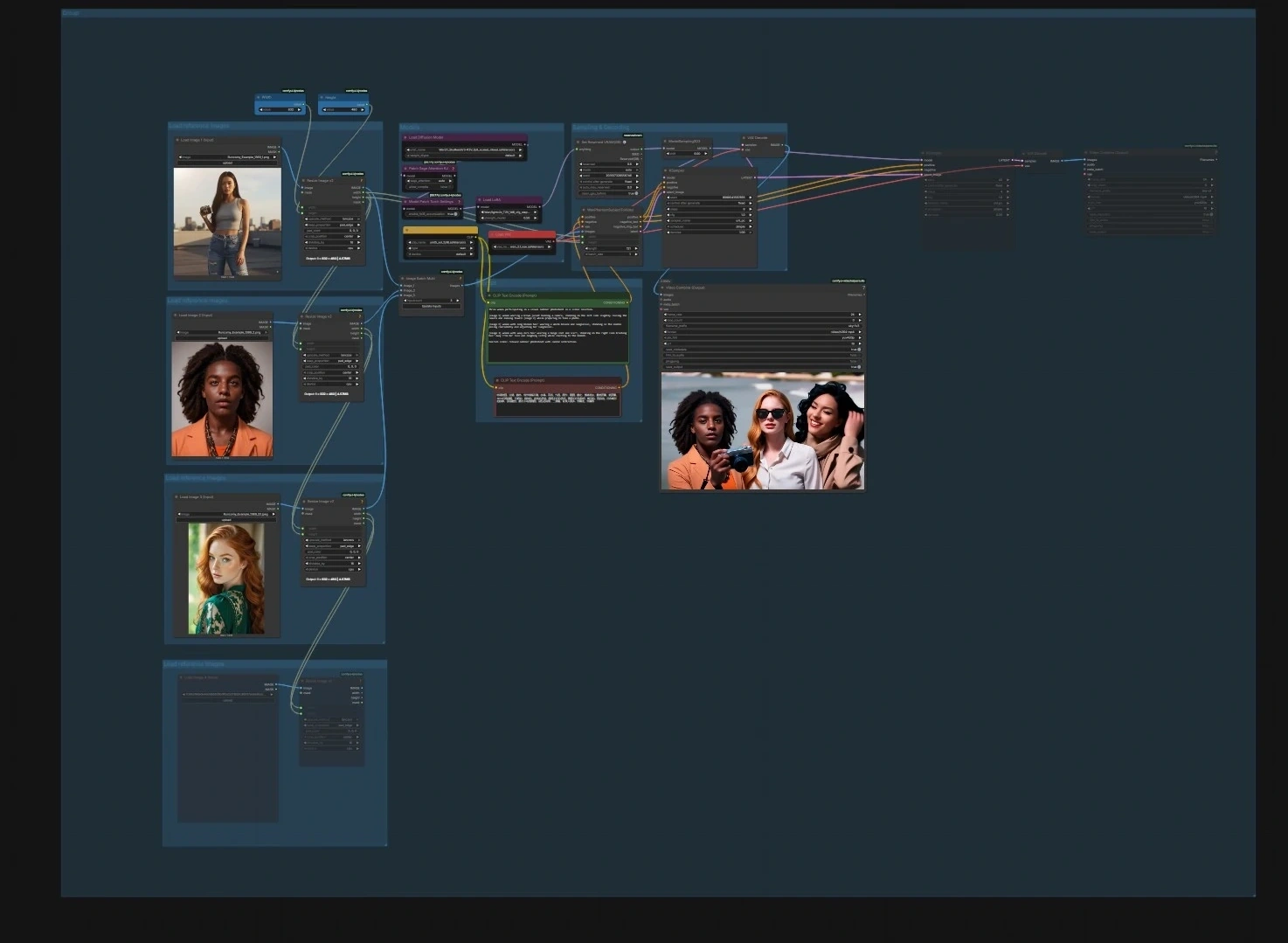
ワークフローは、独立して実行できるか、またはチェーン化できる4つのフォーカスパイプラインを備えています:画像からビデオへのキャラクターアニメーション、ビデオからビデオへの継続、音声からビデオへの話すアバター、ストーリーフローの次のショット生成。各パスには、明確な入力ポイントと合理的なデフォルトが含まれており、アセットを簡単にドロップインして高品質のSkyReels V3出力を迅速にレンダリングできます。
2X Largeおよびそれ以上のマシン(R2Vワークフロー)への注意: 実行前に
Patch Sage Attention KJ(#240)sage_attentionをdisabledに設定してください。有効にしたままにするとSM90 kernel is not availableエラーが発生することがあります。
Comfyui SkyReels V3 ComfyUIワークフローの主要モデル#
- WanVideo FP8パックからのSkyReels V3ビデオバックボーン(R2V、V2Vショット、A2V)。これらは、アイデンティティを意識した動き、ビデオの継続、および音声条件付きリップシンクを処理するコアジェネレーターです。Hugging FaceのWanVideoパックでSkyReels V3の重みを確認してください。こちら
- 画像ガイダンスと参照埋め込みのためのOpenCLIP Vision ViTモデル。これらは、フレーム全体でルックとスタイルを維持するのに役立つ堅牢なビジュアル機能を提供します。プロジェクトページ: open_clip
- プロンプト理解のためのUMT5テキストエンコーダ。スタイル、シーン、アクションを誘導する豊かな言語条件を提供します。リポジトリ: umt5
- リップシンクと音声分析のためのWav2Vec2音声機能。中国語のベースバリアントがデフォルトでサポートされており、同様の英語バリアントも機能します。モデルカード: TencentGameMate/chinese-wav2vec2-base
- 音声からテキストへのQwen3-ASR-1.7B。参照音声を転写し、音声クローンTTSプロンプトをブートストラップするために使用されます。モデルカード: Qwen/Qwen3-ASR-1.7B
- ボーカル分離のためのMelBandRoFormer。リップシンク埋め込みを行う前にクリーンな音声トラックが必要な場合に役立ちます。モデルカード: Kijai/MelBandRoFormer_comfy
- ショットを意識したプロンプト生成のためのMiniCPM-V。以前の映像を分析して、ストーリーの連続性のための次のショットを提案します。モデルハブ: OpenBMB/MiniCPM-V
Comfyui SkyReels V3 ComfyUIワークフローの使用方法#
グラフは4つのパイプラインに編成されています。どれか1つを独立して実行するか、シーケンスで実行して長い編集を構築することができます。
画像からビデオへのキャラクターアニメーション#
- モデル。
UNETLoader(#241)、CLIPLoader(#242)、VAELoader(#194)を使用してモデルグループにUNet、CLIP、VAEをロードします。モデルパッチノードPathchSageAttentionKJ(#240)とModelPatchTorchSettings(#239)は注意と数学の設定を最適化し、LoraLoaderModelOnly(#250)はオプションでSkyReelsモデルにスタイルまたはモーションLoRAをブレンドすることを可能にします。 - 参照画像をロードします。3つの「Load reference images」グループを使用して、1〜3枚のポートレートまたはポーズをインポートします。リサイズヘルパー
ImageResizeKJv2(#291, #298, #299, #304)がアスペクト比を揃え、バッチ処理します。クリーンなアイデンティティ写真はより安定した結果をもたらします。 - プロンプト。シーンとアクションのテキストを
CLIPTextEncode(#6)を使用してプロンプトグループに入力し、CLIPTextEncode(#7)を使用してオプションのネガティブテキストエンコーダで望ましくない特性を排除します。言語は動きとフレーミングに特化して簡潔に保ちます。 - サンプリングとデコード。
WanPhantomSubjectToVideo(#249)は、参照とプロンプトをアイデンティティを意識した潜在に融合し、KSampler(#149)をModelSamplingSD3(#48)を通じて供給します。VAEDecode(#264)からデコードされたフレームは、VHS_VideoCombine(#280)で映画にパッケージされます。そこで目標フレームレートとファイル形式を設定します。
ビデオからビデオへの拡張ループ#
- 入力ビデオと設定。
VHS_LoadVideo(#329)を使用してソースクリップを持ち込みます。生成する追加セグメントの数とセグメント間のオーバーラップを整数ヘルパー「Number of Extend」 (#342)と「Overlapping Frames」 (#341)を使用して設定します。ImageResizeKJv2(#327)はサンプラーのために解像度を標準化します。 - ループサンプリング拡張ビデオ。ループペア
easy forLoopStart(#331)とeasy forLoopEnd(#332)は、クリップをウィンドウで歩いてトランジションを安定化します。各ウィンドウはWanVideoEncode(#326)でエンコードされ、WanVideoEmptyEmbeds(#328)を介してニュートラルまたはコントロール埋め込みを受け取り、WanVideoModelLoader(#319)からWanVideoSampler(#320)でノイズを除去されます。フレームはWanVideoDecode(#321)でデコードされ、VHS_VideoCombine(#322, #335)でプレビューまたは保存されます。 - パフォーマンスヘルパー。
WanVideoTorchCompileSettings(#323)とWanVideoBlockSwap(#325)は、長時間または高解像度の実行のためのコンパイルとメモリトリックを有効にします。
音声からビデオへの話すアバター#
- 1 – 音声を作成します。
FB_Qwen3TTSVoiceClonePrompt(#416)とFB_Qwen3TTSVoiceClone(#412)を使用して音声クローンされた音声トラックを生成するか、LoadAudio(#417)を使用して任意の事前録音された音声をロードします。Qwen3ASRLoader(#414)とQwen3ASRTranscribe(#413)は、参照クリップからテキストを抽出してTTSプロンプトのシードとして使用するのに役立ちます。 - 2 – 音声機能。
DownloadAndLoadWav2VecModel(#348)はMultiTalkWav2VecEmbeds(#350)にフィードして、音声からリップモーション埋め込みを作成します。長さは音声に合わせて調整され、PreviewAudio(#422)でプレビュー可能です。Any Switch (rgthree)(#435)を使用して、TTS出力またはインポートしたファイルを駆動トラックとして選択します。 - 3 – 入力画像。「3 - Input image」グループで話す顔をロードし、
ImageResizeKJv2(#370)でサイズを調整します。クリーンで正面を向いた一貫した照明のポートレートが最適です。 - 参照ビデオ生成。まず、
WanVideoImageToVideoEncode(#392)を使用して静止画から短いビジュアルアンカーを作成します。CLIPVisionLoader(#352)とWanVideoClipVisionEncode(#351)からのCLIP-Vision機能は、次のステージ全体でアイデンティティを安定化します。サンプリング設定グループでスケジューラWanVideoSchedulerv2(#385)が準備されます。 - 音声リップシンクを生成します。
WanVideoImageToVideoSkyreelsv3_audio(#383)は開始画像、オプションの参照フレーム、およびCLIP-Vision埋め込みを画像条件付けに組み合わせます。WanVideoSamplerv2(#384)はSkyReels A2Vモデルでノイズを除去し、WanVideoSamplerExtraArgs(#386)は正確な口の形状のためにMultiTalkリップシンク埋め込みを注入します。WanVideoPassImagesFromSamples(#381)はデコードされたフレームをVHS_VideoCombine(#346)にストリーミングし、最終ビデオが音声とマルチプレックスされます。
ビデオからビデオへの次のショット生成#
- ビデオフレームの前処理。
VHS_LoadVideo(#443)を使用して前のショットをインポートし、ImageResizeKJv2(#441)でサイズを調整します。GetImageRangeFromBatch(#445)がコンテキストスライスを選択し、WanVideoEncode(#440)が潜在に変換します。WanVideoEmptyEmbeds(#442)が条件付けウィンドウを準備します。 - 自動ビデオプロンプト。
CreateVideo(#450)がコンテキストフレームからコンパクトなプロキシクリップを組み立て、AILab_MiniCPM_V_Advanced(#449)がこれを分析して次のショットプロンプトを作成します。ShowText|pysssss(#447)で下書きを検査または修正し、WanVideoTextEncodeCached(#444)で埋め込みを行った後にサンプリングします。 - モデルとサンプリング。
WanVideoModelLoader(#436)とWanVideoVAELoader(#438)を使用してV2Vショットモデルをロードします。オプションのWanVideoBlockSwap(#439)がVRAMを処理します。WanVideoSampler(#451)が継続を生成し、WanVideoDecode(#437)がフレームをレンダリングし、VHS_VideoCombine(#446)が最終ショットを出力します。このSkyReels V3 ComfyUIパスは、各新しいカットが最後のものを尊重する必要があるストーリーボードやプリビズに理想的です。
Comfyui SkyReels V3 ComfyUIワークフローの主要ノード#
WanPhantomSubjectToVideo(#249)。バッチ処理された参照画像とテキストキューからアイデンティティを意識した潜在を構築し、サンプラーを駆動します。類似性のロックとクリエイティブな動きのバランスを取るために、参照の数と多様性を調整します。それを供給するリサイズノードを一貫して保ち、ドリフトを避けます。参照: GitHubのWanVideoラッパーには実装ノートと期待される入力が含まれています。ComfyUI-WanVideoWrapperWanVideoImageToVideoEncode(#392)。静止画を安定したショットシードにエンコードし、オプションでポーズとフレーミングのためのCLIP-Visionガイダンスをブレンドします。オーディオ駆動ステージの前にアンカーフレームを作成するために使用し、アイデンティティとカメラ設定がパイプライン全体で一貫しているようにします。ラッパードキュメント: ComfyUI-WanVideoWrapperWanVideoImageToVideoSkyreelsv3_audio(#383)。A2Vサンプラー用に画像埋め込みを準備し、オプションの参照ビデオフレームをマージします。サンプラーパスと幅と高さが一致していることを確認し、正確なリップシンクのためにWanVideoSamplerv2とMultiTalkWav2VecEmbedsとペアにします。WanVideoSamplerv2(#384, #387)。画像とテキスト埋め込みに加え、スケジューラ設定を受け入れるSkyReels V3のメインデノイザーです。WanVideoSamplerExtraArgsノード (#386, #409)は、リップシンク、ループ、またはコンテキスト機能が注入される場所です。A2VとI2Vモデルを切り替える際にこれらを接続しておいてください。実装の詳細: ComfyUI-WanVideoWrapperMultiTalkWav2VecEmbeds(#350)。音声を時間的に整列された埋め込みに変換し、口の動きを駆動します。意図したフレーム予算に一致させ、クリーンなボーカルを確保することで、音素の精度が大幅に向上します。Wav2Vec参照モデル: [TencentGameMate/chinese-wav2vec2-base](https://huggingface.co/TencentGameMate/chinese-wjson
wav2vec2-base)
AILab_MiniCPM_V_Advanced(#449)。前のショットを分析し、キャラクター、背景、アクション、ムード、照明のための構造化プロンプトを作成します。V2V次のショットパスを使用する際に物語の連続性を維持するために使用します。結果のテキストはWanVideoTextEncodeCachedに流れ込みます。モデルファミリー: OpenBMB/MiniCPM-V
オプションの追加機能#
- 接続されたノード間で画像、ビデオ、およびサンプラーの解像度を一貫させて、アスペクトのゆがみやアイデンティティのちらつきを避けます。
- より長い拡張のためには、V2V拡張ループでウィンドウの重なりを増やしてセグメント間のトランジションをスムーズにします。
- GPUメモリが厳しい場合は、予約済みVRAMノード (
ReservedVRAMSetter(#312, #448))を有効にしたままにし、サンプリング前にコンパイル設定ブロックを使用します。 - 話すアバターがビートを外れる場合は、クリーンスピーチを優先するか、
MultiTalk埋め込みを作成する前にMelBandRoFormerでボーカルを分離します。 - 最終配信設定はフレームレート、ピクセルフォーマット、CRFなどが
VHS_VideoCombine出力ノードで制御されます。シームレスな編集のためにソースにフレームレートを合わせます。
このREADMEは、SkyReels V3 ComfyUIグラフ全体をカバーしているため、プロジェクトに合ったパスを選択し、必要に応じてそれらを組み合わせ、試行錯誤を最小限に抑えて一貫したストーリー対応のビデオをレンダリングすることができます。
謝辞#
このワークフローは、以下の作品とリソースを実装および基にしています。私たちは、SkyReels V3 ComfyUIワークフローの貢献と維持に感謝しています。権威ある詳細については、以下にリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- SkyReels/V3 ComfyUI Source
- ドキュメント / リリースノート: SkyReels V3 ComfyUI Source from @Benji’s AI Playground
注意: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者およびメンテナによって提供されるライセンスおよび条件に従います。
