
Qwen Image 2512 LoRA 推論: パイプライン整合、トレーニング一致のAI Toolkit生成 in ComfyUI#
このプロダクションレディのRunComfyワークフローは、AI ToolkitでトレーニングされたLoRAをQwen Image 2512にComfyUIで適用し、トレーニング一致の動作に焦点を当てています。中心となるのはRC Qwen Image 2512 (RCQwenImage2512)であり、これはRunComfyによって構築されたオープンソースのカスタムノード(source)で、Qwenネイティブの推論パイプラインを実行し(一般的なサンプラーグラフではなく)、アダプターをlora_pathとlora_scaleを通じてロードします。
なぜQwen Image 2512 LoRA 推論はComfyUIで異なって見えることがあるのか#
Qwen Image 2512のAI Toolkitプレビューは、Qwenの「真のCFG」ガイダンス動作と条件付けおよびサンプリングに使用されるデフォルトを含むモデル固有のパイプラインによって生成されます。同じジョブを標準のComfyUIサンプラーグラフとして再構築すると、ガイダンスのセマンティクスとLoRAのパッチポイントがシフトする可能性があるため、「同じプロンプト + 同じシード + 同じステップ」でも異なる見た目の結果になることがあります。実際には、「私のLoRAがトレーニングに一致しない」という報告の多くは、単一のパラメータが欠けているのではなく、パイプラインの不一致です。
RCQwenImage2512は、ノード内にQwen Image 2512パイプラインをラップし、そのパイプライン内でLoRAを適用することによって推論を整合させます。パイプラインソース: `src/pipelines/qwen_image.py`。
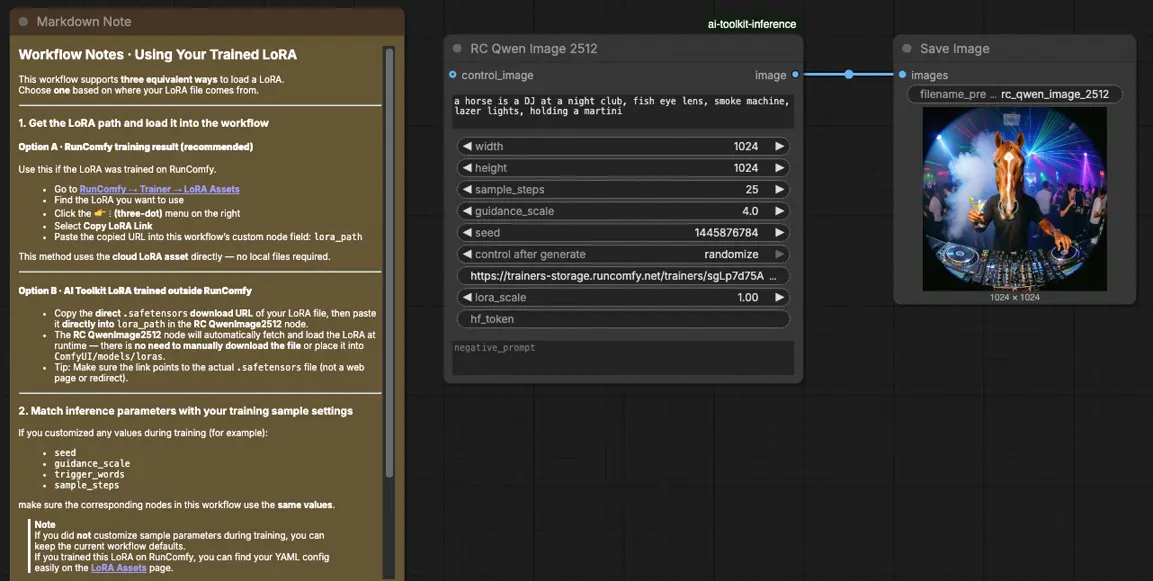
Qwen Image 2512 LoRA 推論ワークフローの使用方法#
ステップ1: ワークフローを開く#
ComfyUIでクラウドワークフローを起動します。
ステップ2: LoRAをインポートする(2つのオプション)#
- オプションA (RunComfyトレーニング結果): RunComfy → Trainer → LoRA Assets → あなたのLoRAを見つける → ⋮ → LoRAリンクをコピー

- オプションB (AI Toolkit LoRAがRunComfyの外でトレーニングされた場合): あなたのLoRAの直接的な
.safetensorsダウンロードリンクをコピーし、そのURLをlora_pathに貼り付けます(ComfyUI/models/lorasにダウンロードする必要はありません)
ステップ3: Qwen Image 2512 LoRA 推論のためのRCQwenImage2512カスタムノードの設定#
あなたのLoRAリンクをRC Qwen Image 2512 (RCQwenImage2512)のlora_pathに貼り付けます。

その後、ノードの残りのパラメータを設定します(トレーニング中のプレビュー/サンプル生成に使用した値にまず一致させて開始します):
prompt: あなたのポジティブプロンプト(LoRAが期待するトリガートークンを含める)negative_prompt: オプション; プレビューでネガティブを使用しなかった場合は空にしておくwidth/height: 出力解像度(このパイプラインファミリーには32の倍数が推奨されます)sample_steps: 推論ステップ; チューニング前にプレビューステップ数を反映(25は一般的なベースラインです)guidance_scale: ガイダンスの強さ(Qwenは「真のCFG」スケールを使用するため、まずプレビュー値を再利用してください)seed: アライメントを検証する間、control_after_generateを'fixed'に設定してシードをロックし、その後新しいサンプルのために変化させますlora_scale: LoRAの強さ; プレビュー値の近くから始めて、小刻みに調整します
これはテキストから画像へのワークフローであるため、入力画像を提供する必要はありません。
トレーニングアライメントの注意: トレーニング中にサンプリングをカスタマイズした場合、AI ToolkitトレーニングYAMLを開いてwidth, height, sample_steps, guidance_scale, seed, lora_scaleを反映させます。RunComfyでトレーニングした場合は、Trainer → LoRA Assets → Configを開き、プレビュー/サンプル値をRCQwenImage2512にコピーしてから繰り返してください。

ステップ4: Qwen Image 2512 LoRA 推論を実行#
Queue/Runをクリックします。SaveImageノードは生成された画像を標準のComfyUI出力フォルダーに保存します。
Qwen Image 2512 LoRA 推論のトラブルシューティング#
RunComfyのRC Qwen Image 2512 (RCQwenImage2512)カスタムノードは、Qwen Image 2512プレビュー風のサンプリングによる推論をパイプライン整合に保つように設計されています:
- ノード内でQwenネイティブ推論パイプラインを実行し(一般的なサンプラーグラフではなく)、
- そのパイプライン内で
lora_path+lora_scaleを介してLoRAを注入する(整合したパッチポイント)。
(1) ComfyUIでQwen-Image Lorasが機能しない#
なぜこれが起こるのか
ユーザーは、AI ToolkitでトレーニングされたQwen-Image LoRAsがComfyUIで適用されないことがあると報告しています。これは、LoRAのstate-dictキーのプレフィックスがComfyUI側のローダー/推論パスが期待するものと一致しないためです(アダプターが「サイレント」にロードされるが、実際にはQwenトランスフォーマーモジュールをパッチしません)。
修正方法(ユーザーが検証済みのオプション)
- RCQwenImage2512を使用してパイプラインレベルでLoRAを注入する: アダプターを
lora_path+lora_scaleでRCQwenImage2512でのみロードし、デバッグ中に追加のLoRAローダーノードをスタックしないようにします。これにより、プレビュー風のサンプリングで使用されるQwenパイプラインとLoRAパッチポイントが整合します。 - 非RC推論プロバイダー/ローダーパスを使用しなければならない場合: ユーザーが報告した修正は、LoRAキーのプレフィックスの最初のセグメントを
diffusion_modelからtransformerに置き換えて、重みを期待されるQwenトランスフォーマーモジュールにマッピングする方法です(問題の正確なコンテキストとその必要性を参照してください)。
(2) 推論_lora_pathを使用するとqwen imageでクラッシュするパッチ(ターボloraでサンプルを生成することを可能にする)#
なぜこれが起こるのか
AI Toolkitのinference_lora_pathフローを通じてQwen(Qwen-Image-2512を含む)の推論LoRAをロードしようとすると、クラッシュが発生するユーザーがいます。これは「プロンプト/CFG/シード」の問題ではなく、推論のロードパスの問題です。
修正方法(ユーザーが検証済み)
- 問題に記載されたパッチを適用/パッチを含むバージョンにアップデートする。 問題の著者は、パッチがQwenの推論LoRAをロードする際のクラッシュを修正することを報告しています(問題の正確な変更とコンフィグのコンテキストを参照してください)。
- 特にComfyUI推論用: RCQwenImage2512を優先し、RCノード内で
lora_path/lora_scaleを介してアダプターをロードします。これにより、外部推論LoRAロードルートに依存せず、プレビュー風のサンプリングと整合したパイプラインを維持します。
(3) ComfyUIでsageattention 2 qwen-imageを使用するとNaN(つまり黒画像)により黒画像が表示される#
なぜこれが起こるのか
ユーザーは、ComfyUIでSageAttentionを使用してQwen Imageを実行すると、NaNが発生し、黒画像に変わることがあると報告しています。これは「私のLoRAが壊れている」ように見えることがありますが、実際には注意バックエンドが無効な値を生成しているため、パイプラインの実行が失敗し、LoRAの動作を意味のある方法で評価する前に失敗します。
修正方法(ユーザーが検証済み)
- NaN/黒出力を引き起こす場合、Qwen Imageで
--use-sage-attentionを使用しない。 クリーンなベースライン(非黒出力)を最初に検証し、次にLoRAの影響を評価します。 - SageAttentionのスピードアップが必要な場合: Qwenの黒出力を修正するためにCUDAバックエンドパスを強制します。実際には、これには多くの場合、ワークフローレベルでパッチを適用する(例:「Patch Sage Attention」ノード)と、影響を受けるGPU/アーキテクチャに対して壊れたTritonパスを回避するCUDAバックエンドのバリアントを選択することが含まれます。
- 安定した(非黒)ベースライン出力を得た後、RCQwenImage2512を通じてQwen Image 2512推論を実行し、パイプライン + LoRAの注入ポイントをプレビューに整合させながら
width/height/sample_steps/guidance_scale/seed/lora_scaleを一致させます。
今すぐQwen Image 2512 LoRA 推論を実行#
共有ワークフローを開き、LoRA URLをlora_pathに貼り付け、プレビューサンプリング値を一致させ、RCQwenImage2512を実行してComfyUIでトレーニングに一致したQwen Image 2512生成を行います。


