
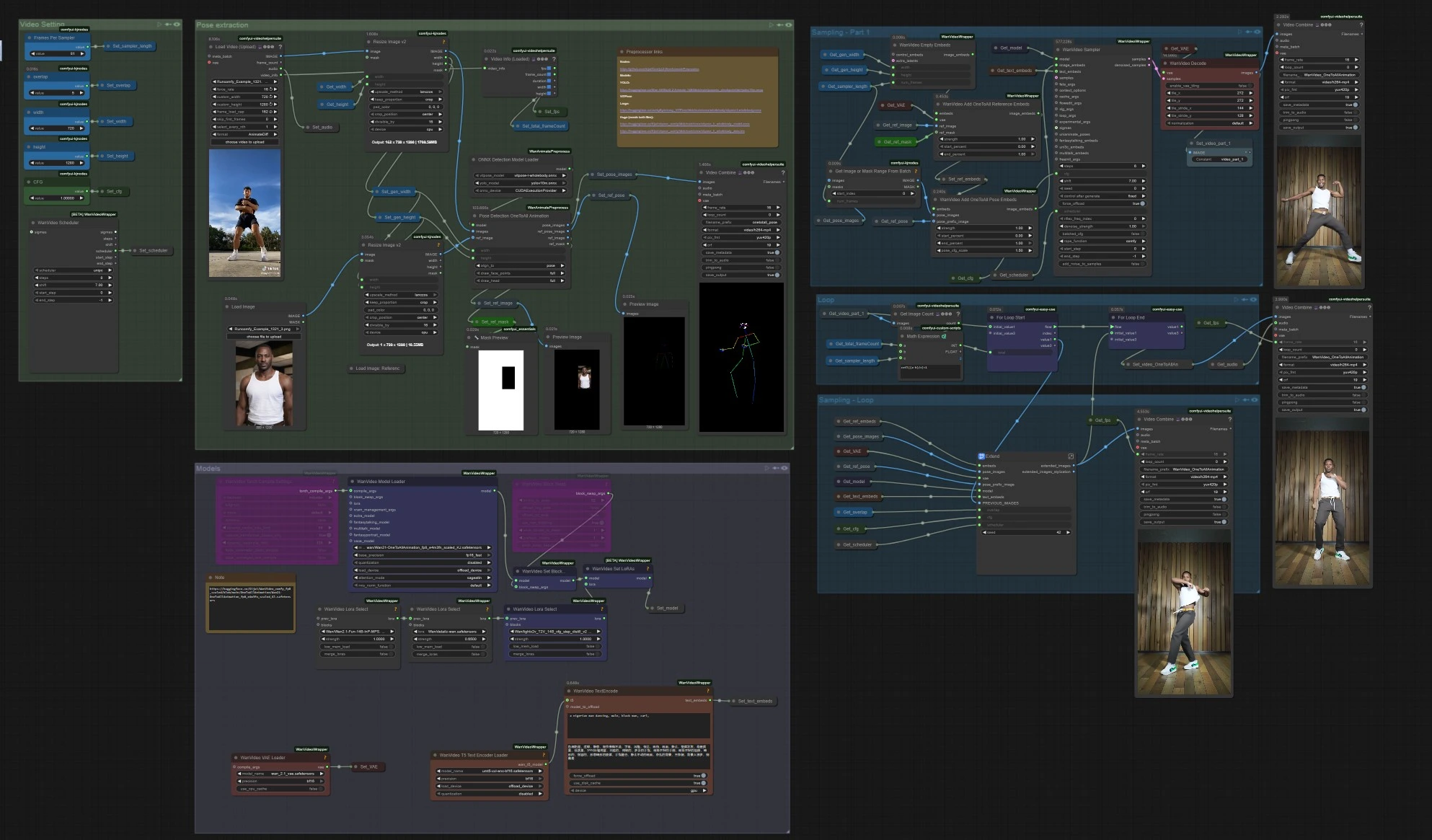
One to All Animation: 長編、ポーズに合わせたキャラクタービデオ in ComfyUI#
このOne to All Animationワークフローは、短い参照クリップを拡張し、高精度なビデオに変換します。モーション、ポーズアライメント、キャラクターのアイデンティティをシーケンス全体で一貫して保ちながら実行されます。Wan 2.1ビデオ生成と全身ポーズガイダンス、スライディングウィンドウ拡張機能を中心に構築されており、ダンス、パフォーマンスキャプチャ、複雑な動きを追うナラティブショットに理想的です。
安定したポーズ駆動の出力が必要なクリエイターのために、One to All Animationは明確な道筋を提供します: ソースビデオからポーズを抽出し、参照画像とマスクで融合し、最初のチャンクを生成し、その後、そのチャンクを繰り返し拡張して全長をカバーします。
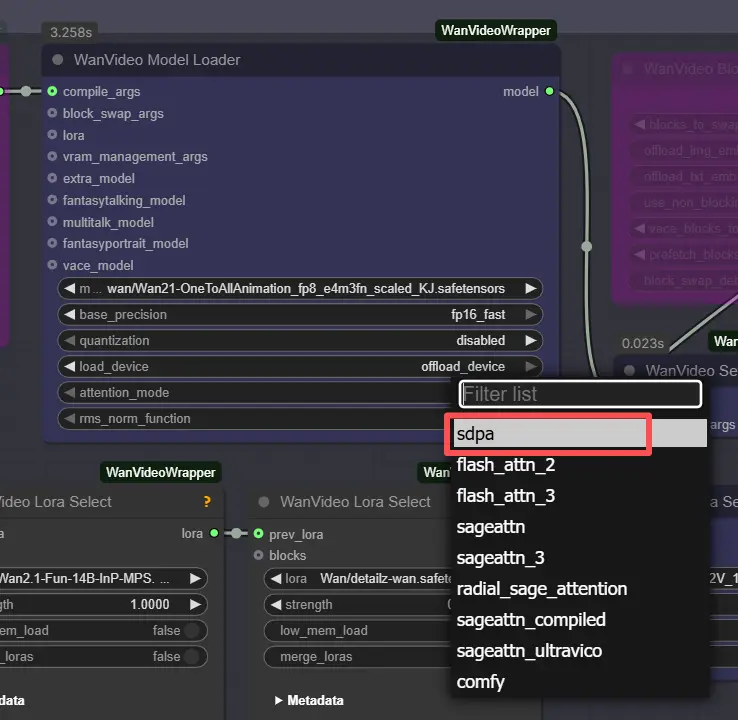
注意: 2XLまたは3XLマシンでは、WanVideo Model Loaderノードでattention_modeを"sdpa"に設定してください。デフォルトのsegeattnバックエンドは高性能なGPUで互換性の問題を引き起こす可能性があります。
Comfyui One to All Animationワークフローの主要モデル#
- Wan 2.1 OneToAllAnimation (ビデオ生成)。高品質なモーションとアイデンティティ保持のために使用される主要な拡散モデルです。例: Wan21‑OneToAllAnimation fp8 scaled by Kijai。 Model card
- UMT5‑XXLテキストエンコーダー。Wanビデオ生成のためのプロンプトをエンコードします。 Model card
- ViTPose Whole‑Body (ポーズ推定)。ポーズの忠実性を駆動する密な骨格キーポイントを生成します。ViTPose論文と全身ONNXウェイトを参照してください。 Paper • Weights
- YOLOv10m検出器 (人物/領域検出)。推定器を被写体に集中させることで、堅牢なポーズ抽出を加速します。 Paper • Weights
- ViTPose‑Hの代替オプション。難しい動きに対処するための高容量の全身モデル。 Weights および data file
- スタイル/コントロール用のオプションLoRAパック。このグラフで使用された例として、Wan2.1‑Fun‑InP‑MPS、detailz‑wan、lightx2v T2Vがあります。それらはテクスチャ、ディテール、またはインプレースコントロールを再トレーニングなしで洗練します。
Comfyui One to All Animationワークフローの使用方法#
全体の流れ
- ワークフローは参照モーションビデオを読み込み、全身ポーズを抽出し、ポーズとキャラクター参照を融合するOne to All Animation埋め込みを準備し、初期クリップを生成し、そのクリップを重複させて繰り返し拡張し、全体の長さをカバーします。最終的に音声をマージし、完全なビデオをエクスポートします。
ポーズ抽出
VHS_LoadVideo(#454)でモーションソースを読み込みます。フレームはImageResizeKJv2(#131)で生成アスペクト比に合わせてリサイズされ、安定したサンプリングが可能になります。OnnxDetectionModelLoader(#128)はYOLOv10mと全身のViTPoseをロードし、PoseDetectionOneToAllAnimation(#141)はフレームごとのポーズマップ、参照ポーズ画像、クリーンな参照マスクを出力します。PreviewImage(#145)を使用して、ポーズが被写体を追跡しているかを素早く確認します。明確で高コントラストの映像で、モーションブラーが最小限のものがOne to All Animationに最適です。
モデル
WanVideoModelLoader(#22)はWan 2.1 OneToAllAnimationのウェイトをロードし、WanVideoVAELoader(#38)はペアのVAEを提供します。望む場合は、WanVideoLoraSelect(#452, #451, #56)を介してスタイル/コントロールLoRAをスタックし、WanVideoSetLoRAs(#80)で適用します。- テキストプロンプトは
WanVideoTextEncode(#16)によってエンコードされます。簡潔でアイデンティティに焦点を合わせたポジティブプロンプトと、キャラクターをモデルに保つための強力なクリーンアップネガティブを書きます。
ビデオ設定
- 幅と高さは「ビデオ設定」グループで設定され、ポーズ抽出と生成に伝播されるため、すべてが一致した状態を維持します。
注意: ⚠️ 解像度制限 : このワークフローは720×1280 (720p)に固定されています。他の解像度を使用すると、ワークフローが手動で再構成されない限り、寸法不一致エラーを引き起こします。
WanVideoScheduler(#231)とCFGコントロールはノイズスケジュールとプロンプトの強度を選択します。高いCFGはプロンプトにより忠実で、低い値はポーズを少し緩やかに追跡しますが、アーティファクトを減少させることができます。VHS_VideoInfoLoaded(#440)はソースクリップのfpsとフレーム数を読み取り、ループは必要なOne to All Animationウィンドウの数を決定します。
サンプリング – パート1
WanVideoEmptyEmbeds(#99)はターゲットサイズでコンディショニング用のコンテナを作成します。WanVideoAddOneToAllReferenceEmbeds(#105)は参照画像とそのref_maskを注入してアイデンティティを固定し、背景や衣服のような領域を保持または無視します。WanVideoAddOneToAllPoseEmbeds(#98)は抽出されたpose_imagesとpose_prefix_imageを添付し、最初に生成されたチャンクがフレーム1からソースモーションに従います。WanVideoSampler(#27)は初期の潜在クリップを生成し、WanVideoDecode(#28)でデコードされ、オプションでプレビューまたはVHS_VideoCombine(#139)で保存されます。これは拡張されるシードセグメントです。
ループ
VHS_GetImageCount(#327)とMathExpression|pysssss(#332)は、総フレーム数とパスごとの長さに基づいて拡張パスの数を計算します。easy forLoopStart(#329)は初期クリップを開始コンテキストとして使用して拡張パスを開始します。
サンプリング – ループ
Extend(#263)は長尺のOne to All Animationの中心です。WanVideoAddOneToAllExtendEmbeds(サブグラフ内)で前の潜在を再利用し、シーンとキャラクターをウィンドウ間で一貫して維持しながら、次のウィンドウをサンプリングしてデコードします。ImageBatchExtendWithOverlap(Extend内)は、overlap領域を使用して新しいウィンドウを蓄積されたビデオにブレンドし、境界を滑らかにし、時間的な継ぎ目を減少させます。easy forLoopEnd(#334)は各拡張ブロックを追加します。結果はSet_video_OneToAllAnimation(#386)を介してエクスポート用に保存されます。
エクスポート
VHS_VideoCombine(#344)は最終ビデオを書き込み、ソースfpsとVHS_LoadVideoからのオプションのオーディオを使用します。サイレントな結果を好む場合は、ここでオーディオ入力を省略またはミュートします。
Comfyui One to All Animationワークフローの主要ノード#
PoseDetectionOneToAllAnimation (#141)
- 被写体を検出し、ポーズガイダンスを駆動する全身キーポイントを推定します。YOLOv10とViTPoseにより、速い動きや部分的な遮蔽に対しても堅牢です。被写体がドリフトしたり、複数の人物が検出器を混乱させる場合は、入力をトリミングするか、上記の高容量ViTPose‑Hウェイトに切り替えてください。
WanVideoAddOneToAllReferenceEmbeds (#105)
- 参照画像と
ref_maskをコンディショニングに融合し、アイデンティティ、衣装、または保護された領域をフレーム間で安定させます。タイトなマスクは顔や髪を保護し、広いマスクは背景を固定できます。ルックを変更する際は、参照を交換し、同じ動きを維持します。
WanVideoAddOneToAllPoseEmbeds (#98)
- ポーズマップとプレフィックスポーズをOne to All Animation埋め込みに結び付けます。より厳密な振り付けにはポーズの影響を増やし、自由な解釈には少し減らします。LoRAsと組み合わせることで、一貫したテクスチャを維持しつつ動きに合わせることができます。
WanVideoSampler (#27)
- 埋め込みとテキストを初期の潜在クリップに変える主要なビデオサンプラーです。
cfgはプロンプトの遵守を制御し、schedulerは品質、速度、安定性をトレードオフします。同じサンプラーファミリーをここで使用し、ループ内で使用してちらつきを避けます。
Extend (#263)
- オーバーラップを使用したスライディングウィンドウ拡張を実行するコンパクトなサブグラフです。
overlap設定は重要なダイヤルです: より多くのオーバーラップは境界をより滑らかにブレンドしますが、追加の計算が必要です。オーバーラップが少ないと速くなりますが、継ぎ目が現れることがあります。このノードはまた、シーンとキャラクターをウィンドウ間に一貫して保つために以前の潜在を再利用します。
VHS_VideoCombine (#344)
- 最終的なマルチプレックスと保存。検出されたfpsから
frame_rateを設定して、モーションのタイミングをソースに忠実に保ちます。ポストでトリミングまたはループできますが、元のテンポでエクスポートすることでパフォーマンスの感触を保持します。
オプションのエクストラ#
- プリプロセッサのインストールノート。ポーズ抽出ノードはコミュニティのアドオンから来ています。セットアップとONNXの配置についてはリポジトリを参照してください。 ComfyUI‑WanAnimatePreprocess
- 難しい動きにはViTPose‑Hを好む。手や足が速いまたは部分的に遮蔽されている場合はViTPose‑Hに切り替えてください。モデルとそのデータファイルを上記のリンクからダウンロードしてください。
- 長時間のランのチューニング。VRAM制限に達した場合は、パスごとのウィンドウ長を減らすか、LoRAスタックを簡略化してください。その後、オーバーラップを少し上げてトランジションをクリーンに保つことができます。
- 強力なアイデンティティ保持。高品質で正面を向いた参照を使用し、顔、髪、または衣装を保護する正確な
ref_maskを描きます。これは長いOne to All Animationシーケンスにとって重要です。 - クリーンな映像が役立ちます。高いシャッタースピード、一貫した照明、明確な前景の被写体は、ポーズトラッキングを劇的に改善し、One to All Animation出力のジッターを減少させます。
- ビデオユーティリティ。エクスポーターとヘルパーノードはVideo Helper Suiteから来ています。コーデックやプレビューを追加で制御したい場合は、プロジェクトのドキュメントを確認してください。 Video Helper Suite
謝辞#
このワークフローは、以下の作品とリソースを実装および基にしています。One to All Animationワークフローのチュートリアルを提供してくれたInnovate Futures @ Benjiと、One‑to‑All Animationプロジェクトをサポートしてくれたssj9596に感謝します。詳細については、以下のオリジナルドキュメントとリポジトリを参照してください。
リソース#
- Innovate Futures @ Benji/One to All Animation Source
- GitHub: ssj9596/One-to-All-Animation
- Hugging Face: MochunniaN1/One-to-All-1.3b_1
- arXiv: 2511.22940 json
- Docs / Release Notes: Patreon post
注意: 参照されているモデル、データセット、およびコードの使用は、それぞれの著者および管理者によって提供されるライセンスおよび条件に従います。


