
LTX-2 ComfyUI: リアルタイムテキスト、画像、深度およびポーズからビデオへ同期音声付き#
このオールインワン LTX-2 ComfyUI ワークフローは、短時間で音声付きの短いビデオを生成し、反復することを可能にします。テキストからビデオ (T2V)、画像からビデオ (I2V)、深度からビデオ、ポーズからビデオ、キャニーからビデオへのルートが含まれており、プロンプト、スチル、または構造化ガイダンスから開始し、同じクリエイティブループを維持できます。
LTX-2 の低遅延 AV パイプラインとマルチ GPU シーケンス並列処理を中心に構築されたグラフは、迅速なフィードバックを重視しています。動き、カメラ、外観、音を一度に記述し、幅、高さ、フレーム数、または制御 LoRA を調整して、再配線せずに結果を洗練します。
注: LTX-2 ワークフローの互換性についての注意 — LTX-2 には 5 つのワークフローが含まれています。Text-to-Video と Image-to-Video はすべてのマシンタイプで動作しますが、Depth to Video、Canny to Video、および Pose to Video は 2X-Large マシン以上が必要です。これらの ControlNet ワークフローを小型マシンで実行すると、エラーが発生する可能性があります。
LTX-2 ComfyUI ワークフローの主要モデル#
- LTX-2 19B (dev FP8) チェックポイント。マルチモーダル条件付けからビデオフレームと同期音声を生成するコアオーディオビジュアル生成モデル。Lightricks/LTX-2
- LTX-2 19B Distilled チェックポイント。クイックドラフトまたはキャニー制御のランに役立つ軽量で高速なバリアント。Lightricks/LTX-2
- Gemma 3 12B IT テキストエンコーダー。ワークフローのプロンプトエンコーダーで使用される主要なテキスト理解バックボーン。Comfy-Org/ltx-2 split files
- LTX-2 Spatial Upscaler x2。中間グラフで空間の詳細を2倍にする潜在的なアップサンプラー。Lightricks/LTX-2
- LTX-2 Audio VAE。音声を生成し、ビデオと一緒に多重化できるように音声潜在をエンコードおよびデコードします。上記の LTX-2 リリースに含まれています。
- Lotus Depth D v1‑1。深度マップを生成するために画像から堅牢な深度マップを導き出すために使用される深度 UNet。Comfy‑Org/lotus
- SD VAE (MSE, EMA pruned)。深度プリプロセッサーブランチで使用される VAE。stabilityai/sd-vae-ft-mse-original
- LTX‑2 用 Control LoRAs。動きと構造を誘導するためのオプションのプラグアンドプレイ LoRAs:
LTX-2 ComfyUI ワークフローの使用方法#
グラフには、独立して実行できる 5 つのルートが含まれています。すべてのルートは同じエクスポートパスを共有し、同じプロンプトから条件付けへのロジックを使用するため、一度学習すると、他のルートも馴染み深く感じられます。
T2V: プロンプトからビデオとオーディオを生成#
T2V パスは CLIP Text Encode (Prompt) (#3) から始まり、オプションで CLIP Text Encode (Prompt) (#4) に否定を追加できます。LTXVConditioning (#22) は、テキストと選択したフレームレートをモデルに結び付けます。EmptyLTXVLatentVideo (#43) と LTX LTXV Empty Latent Audio (#26) は、LTX LTXV Concat AV Latent (#28) によって融合されるビデオとオーディオの潜在を作成します。デノイズループは LTXVScheduler (#9) と SamplerCustomAdvanced (#41) を通過し、その後 VAE Decode (#12) と LTX LTXV Audio VAE Decode (#14) がフレームとオーディオを生成します。Video Combine 🎥🅥🅗🅢 (#15) は、同期音声付き H.264 MP4 を保存します。
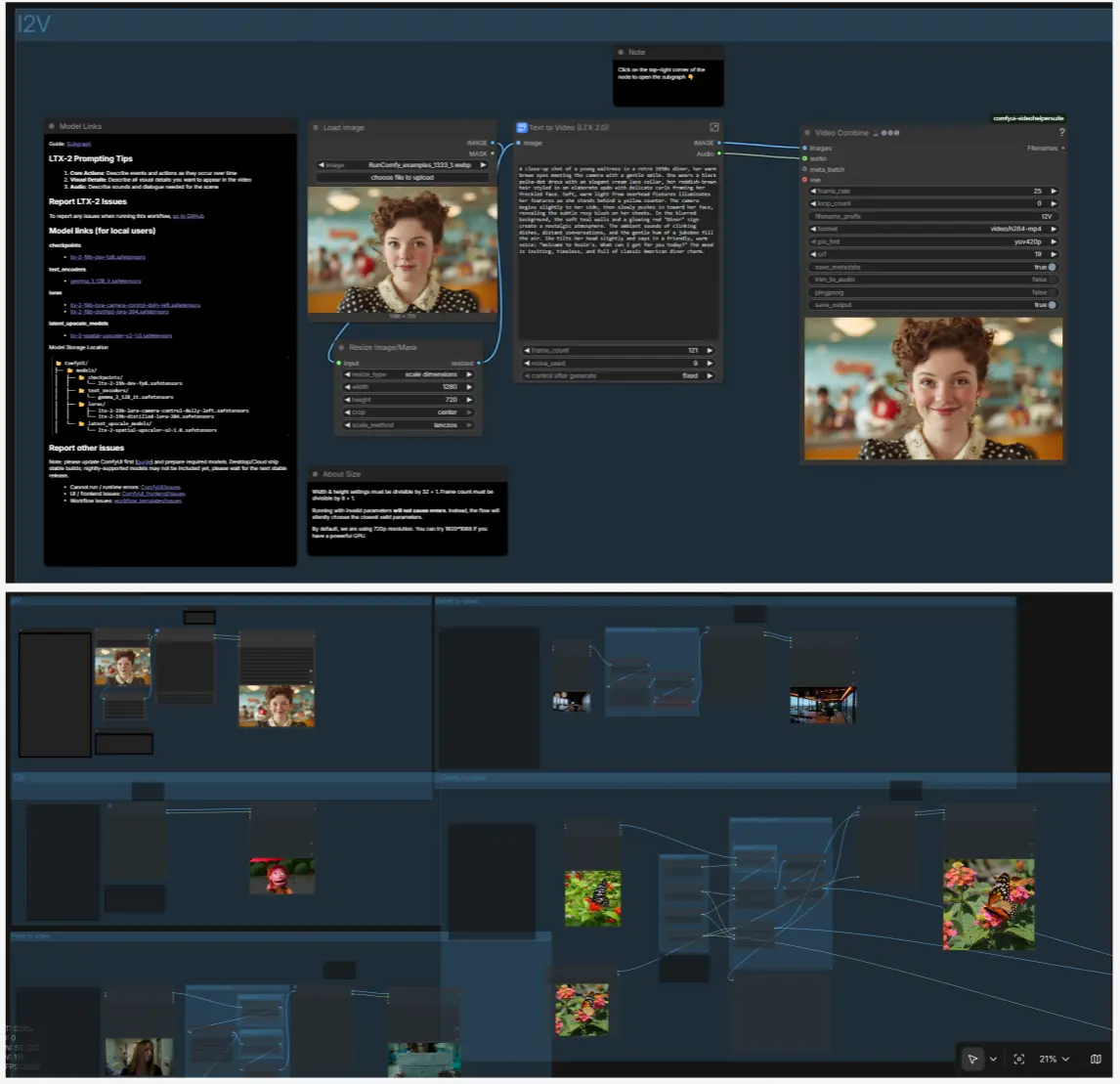
I2V: スチルをアニメーション化#
スチル画像を LoadImage (#98) で読み込み、ResizeImageMaskNode (#99) でリサイズします。T2V サブグラフ内で LTX LTXV Img To Video Inplace は、最初のフレームを潜在シーケンスに挿入し、動きがノイズからではなくスチルから構築されるようにします。テキストプロンプトは動き、カメラ、雰囲気に焦点を当ててください。コンテンツは画像から来ます。
深度からビデオへ: 深度マップから構造を意識した動き#
“Image to Depth Map (Lotus)” プリプロセッサを使用して入力を深度画像に変換し、VAEDecode によってデコードし、必要に応じて極性を逆転させます。その後、“Depth to Video (LTX 2.0)” ルートは深度ガイダンスを LTX LTXV Add Guide を通じてフィードし、モデルがアニメーション化する際にグローバルシーン構造を尊重します。このパスは同じスケジューラー、サンプラー、アップスケーラーステージを再利用し、タイルデコードで画像と多重化オーディオをエクスポートすることで終了します。
ポーズからビデオへ: 人間のポーズから動きを駆動#
クリップを VHS_LoadVideo (#198) でインポートし、DWPreprocessor (#158) がフレーム間で人間のポーズを確実に推定します。“Pose to Video (LTX 2.0)” サブグラフは、プロンプト、ポーズ条件付け、オプションの Pose Control LoRA を組み合わせて、手足、向き、ビートを一貫させながら、スタイルと背景をテキストから流れるようにします。ダンス、簡単なスタント、または体のタイミングが重要なトークカメラショットに使用してください。
キャニーからビデオへ: エッジ忠実なアニメーションと蒸留速度モード#
フレームを Canny (#169) にフィードして安定したエッジマップを取得します。“Canny to Video (LTX 2.0)” ブランチは、エッジとオプションの Canny Control LoRA を受け入れ、シルエットへの忠実度を高めます。"Canny to Video (LTX 2.0 Distilled)” は、より高速な蒸留チェックポイントを提供し、迅速な反復を可能にします。両方のバリアントは、オプションで最初のフレームを挿入し、画像強度を選択して、CreateVideo または VHS_VideoCombine 経由でエクスポートできます。
ビデオ設定とエクスポート#
Width (#175) と height (#173) で幅と高さを設定し、Frame Count (#176) で総フレーム数を設定し、最初の参照を固定したい場合は Enable First Frame (#177) を切り替えます。各ルートの最後に VHS_VideoCombine ノードを使用して、crf、frame_rate、pix_fmt、およびメタデータの保存を制御します。蒸留キャニールートのための直接 VIDEO 出力を好む場合は、専用の SaveVideo (#180) が提供されています。
パフォーマンスとマルチ GPU#
グラフは LTXVSequenceParallelMultiGPUPatcher (#44) を適用し、torch_compile が有効になっているため、シーケンスを GPU に分割して遅延を低減します。KSamplerSelect (#8) でサンプラーを選択でき、オイラーや勾配推定スタイルを含めます。フレーム数を小さくし、ステップを減らすことで、迅速に反復でき、満足したときにスケールアップできます。
LTX-2 ComfyUI ワークフローの主要ノード#
LTX Multimodal Guider(#17)。テキストの条件付けがビデオとオーディオの両方のブランチをどのように誘導するかを調整します。cfgとmodalityをリンクされたLTX Guider Parameters(#18 for VIDEO, #19 for AUDIO) で調整し、忠実さと創造性のバランスを取ります。プロンプトの従順性を高めるためにcfgを上げ、特定のブランチを強調するためにmodality_scaleを増やします。LTXVScheduler(#9)。LTX-2 の潜在空間に合わせたシグマスケジュールを構築します。プロトタイピング時には、ステップを少なくすることで遅延を短縮し、最終レンダリング時にはステップを増やします。SamplerCustomAdvanced(#41)。RandomNoise、KSamplerSelect(#8) から選択したサンプラー、スケジューラーのシグマ、および AV 潜在を結びつけるデノイザー。異なる動きのテクスチャと収束動作のためにサンプラーを切り替えます。LTX LTXV Img To Video Inplace(I2V ブランチ参照、例: #107)。画像をビデオ潜在に注入し、最初のフレームがコンテンツをアンカーしている間にモデルが動きを合成します。最初のフレームがどの程度厳密に保持されるかを調整するためにstrengthをチューニングします。LTX LTXV Add Guide(ガイド付きルート内、例: 深度/ポーズ/キャニー)。潜在空間に直接構造ガイド(画像、ポーズ、またはエッジ)を追加します。ガイドの忠実度と生成の自由をバランスするためにstrengthを使用し、最初のフレームを時間的アンカリングが必要な場合のみ有効にします。Video Combine 🎥🅥🅗🅢(#15 および姉妹ノード)。デコードされたフレームと生成されたオーディオを MP4 にパッケージします。プレビューのためにcrfを上げ(圧縮を増やす)、ファイナルのためにcrfを下げ、条件付けで設定したframe_rateが一致することを確認します。LTXVSequenceParallelMultiGPUPatcher(#44)。シーケンス並列推論をコンパイル最適化とともに有効にします。最高のスループットを得るためにオンのままにしておきます。デバイス配置をデバッグするときのみ無効にします。
オプションの追加要素#
- LTX-2 ComfyUI のプロンプトのヒント
- 静的な外観だけでなく、時間の経過とともにコアアクションを記述します。
- ビデオで見たい重要な視覚的詳細を指定します。
- サウンドトラックを書きます: 雰囲気、フォーリー、音楽、および任意の対話。
- サイズルールとフレームレート
- 幅と高さは 32 の倍数を使用します(例: 1280×720)。
- フレーム数は 8 の倍数を使用します(このテンプレートでは 121 が良い長さです)。
- フレームレートが現れる場所で一貫性を保ちます。グラフには浮動小数点数と整数のボックスが含まれており、それらは一致する必要があります。
- LoRA ガイダンス
- カメラ、深度、ポーズ、およびキャニーの LoRA が統合されています。カメラの動きに強度 1 から開始し、必要な場合のみ 2 番目の LoRA を追加します。公式コレクションを Lightricks/LTX‑2 で参照してください。
- より高速な反復
- フレーム数を下げ、json
