
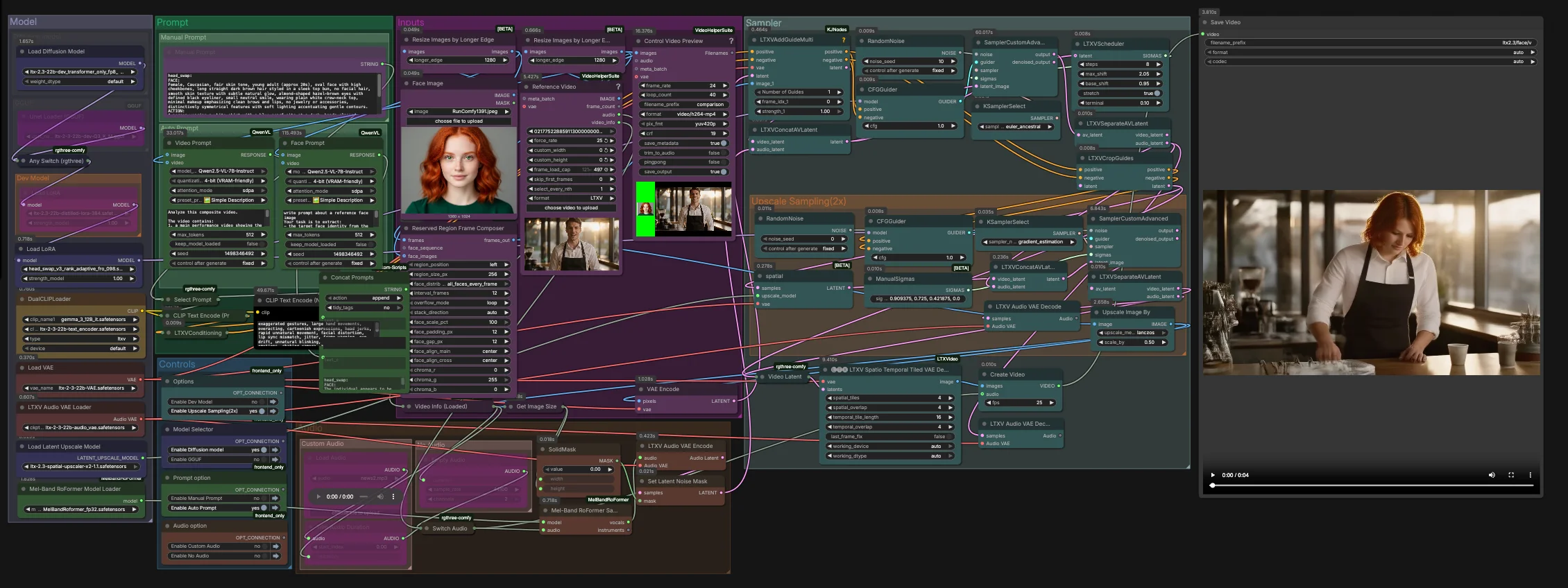
ComfyUI用LTX-2.3-Video-Face-Swap#
このワークフローは、LTX 2.3ファミリーを使用して高忠実度で時間的に安定したビデオ顔置換を提供します。RunComfyとComfyUI用に構築され、アイデンティティガイド画像をターゲットビデオとオプションのオーディオガイダンスと融合させ、フレーム全体で表情、照明、動きを維持します。結果は、リアルでフリッカーに強い交換で、クローズアップや中距離ショットでもしっかりと保持されます。
クリエイター、VFXアーティスト、AI映画制作者は、LTX-2.3-Video-Face-Swapを使用して完全なクリエイティブコントロールを維持できます: 手動でプロンプトを設定したり、入力から構造化プロンプトを生成したり、開発版、蒸留版、FP8、またはGGUFのバリアントを選択したりし、鮮明なディテールのために空間時間デコードとオプションの2倍潜在アップスケーリングで仕上げます。
Comfyui LTX-2.3-Video-Face-Swapワークフローの主要モデル#
- LTX 2.3 22B Video Diffusion Transformer。アイデンティティ保持と時間的コヒーレンスを駆動するコアビデオ生成および編集モデル。Lightricks/LTX-2.3で公式モデルファミリーを参照してください。
- LTX 2.3 Text Encoders。グラフは、LTX 2.3テキストエンコーダをGemma 3 12Bインストラクトエンコーダとペアリングし、ビデオ編集のプロンプトアライメントを改善します。例のアーティファクト: ltx-2-3-22b-text_encoder.safetensors および gemma_3_12B_it.safetensors。
- LTX 2.3 VAEとAudio VAE。詳細と同期を維持しながら、ビジュアルフレームとオーディオトラックを圧縮および再構築するために使用されるエンコーダ/デコーダ。Lightricks/LTX-2.3 VAE filesおよび分割リポジトリvantagewithai/LTX-2.3-Split内のオーディオVAEバリアントを参照してください。
- LTX 2.3 Spatial Upscaler x2。最終デコード前に空間的忠実度を高める潜在空間2倍アップスケーラーで、顔の詳細に最適です。ltx-2.3-spatial-upscaler-x2-1.1.safetensors。
- Head‑swap LoRA。編集を駆動する際に類似性と安定性を向上させるアイデンティティ転送に特化したランク適応型LoRA。例: head_swap_v3_rank_adaptive_fro_098.safetensors。
- MelBandRoFormer。ここではボーカルを分離して口の動きのガイダンスを強化するために使用されるオプションの音楽ソース分離モデル。Kijai/MelBandRoFormer_comfy。
- オプションのデプロイメントバリアント。対応GPUでの速度向上のためのFP8トランスフォーマ専用ウェイトKijai/LTX2.3_comfyおよびCPUまたは低VRAMシナリオ用の軽量UNet GGUFビルドvantagewithai/LTX-2.3-GGUF。
Comfyui LTX-2.3-Video-Face-Swapワークフローの使用方法#
このグラフは2つの段階で動作します。ステージ1では、ネイティブな潜在解像度でのコア交換をオーディオ対応ガイダンスで実行します。ステージ2では潜在空間でアップサンプリングし、顔領域を洗練してから空間時間デコードと最終的なビデオへのマックスを行います。
入力#
Face Image(LoadImage(#255))にアイデンティティ画像をロードします。最も信頼性の高いアイデンティティ抽出のために、よく照らされた正面または3/4ショットを使用します。Reference Video(VHS_LoadVideo(#393))にターゲット映像をロードします。フレームはResizeImagesByLongerEdgeおよびControl Video Preview(VHS_VideoCombine(#396))を介して正規化およびプレビューされ、サンプリング前のクイックチェックが可能です。ReservedRegionFrameComposer(#395)は、シーンレイアウトに顔画像を合わせるガイドフレームを準備し、モデルが条件付け中に交換領域に集中できるようにします。
プロンプト#
Manual Promptで望ましいルックとアクションを手動で説明するか、グラフに自動で構造化プロンプトを作成させることができます。Video Prompt(AILab_QwenVL(#400))はビデオから体の動きとシーンを抽出し、Face Prompt(AILab_QwenVL(#401))は顔画像からアイデンティティの詳細を抽出します。Concat Promptsはアイデンティティとアクションを1つの簡潔な指示にマージし、Select Promptが手動テキストまたは自動プロンプトをCLIP Text Encodeにルーティングします。ネガティブプロンプトテキストは、一般的なビデオアーティファクトを抑えるために別々にエンコードされます。
モデル#
ModelグループはLTX 2.3 UNetまたはそのGGUFバリアントをロードし、蒸留LoRAとヘッドスワップLoRAを適用し、LTX VAEとデュアルテキストエンコーダを起動します。2エンコーダ設定は、話されたコンテンツとカメラブロッキングのアライメントを改善し、アイデンティティを過度に制約することなく行います。- 速度やメモリを最適化する場合、提供されたモデルセレクタで開発版、蒸留版、FP8トランスフォーマ専用、またはGGUFを切り替えます。RunComfyでの追加設定は不要です。
サンプラー#
- ステージ1は、
LTXVConcatAVLatent(#321)でビデオとオーディオの潜在を組み合わせ、CFGGuider(#326)、LTXVScheduler(#324)、およびSamplerCustomAdvanced(#257)でノイズを除去します。LTXVAddGuideMulti(#392)はアイデンティティガイドを挿入し、顔が早期に確立され、時間を通じて安定を維持します。 - 初回パスの後、
LTXVSeparateAVLatent(#323)はストリームを分割し、LTXVCropGuides(#282)が顔周りに編集を集中させます。これにより、重要な部分での計算が集中し、時間的な一貫性が向上します。
アップスケールサンプリング(2倍)#
LTXVLatentUpsampler(#279)は、LTX 2.3 x2空間アップスケーラーを潜在空間で適用します。アップサンプリングされたビデオ潜在はオーディオ潜在と再結合され、LTXVConcatAVLatent(#287)で洗練され、CFGGuider(#284)によってガイドされた2回目のSamplerCustomAdvanced(#288)パスにより洗練されます。- この2段階戦略により、鋭い肌、目、髪が得られ、意図したアイデンティティに固定された交換が維持されます。
オーディオ#
Audioグループでは、Switch Audioを介してオリジナルのオーディオ、無音、またはトリミングされたセグメントをルーティングできます。口の動きの手がかりを強化するために、選択されたトラックはMelBandRoFormerSampler(#355)を通じてボーカルを分離し、LTXVAudioVAEEncode(#364)でエンコードされます。- 固体ノイズマスク(
SetLatentNoiseMask(#365))は、口領域外での意図しないオーディオ駆動の変更を防ぎつつ、音声タイミングを活用して表情をガイドします。
デコードとエクスポート#
- 最終フレームは
LTXVSpatioTemporalTiledVAEDecode(#377)で再構築され、時間認識タイル処理でシームを回避し、動きの連続性を維持します。CreateVideo(#292)は画像を選択したオーディオとマックスし、SaveVideoは完成したクリップを書き込みます。
Comfyui LTX-2.3-Video-Face-Swapワークフローの主要ノード#
LTXVAddGuideMulti(#392)。アライメントされた顔ガイドを条件付けストリームにフィードし、モデルが最初のステップからターゲットアイデンティティをロックするようにします。動きが速い場面で類似性がずれる場合は、ガイドフレームの数や頻度を増やすことで対応し、ガイダンスを全体的に増やすことを避けてください。LTXVCropGuides(#282)。ステージ1の潜在とプロンプトに基づいて自動的に顔領域に第2パスを集中させます。背景や手が注意を引くときに編集領域を絞るために使用します。SamplerCustomAdvanced(#257)。アイデンティティ、照明、粗い動きを確立する主要なノイズ除去パス。LTXVSchedulerとペアにしてステップシェーピングを行い、実験間でサンプラー選択を安定させて比較を意味のあるものにします。LTXVLatentUpsampler(#279)。LTX空間アップスケーラーを使用して2倍の潜在アップスケールを実行し、洗練前に使用します。フリッカーを引き起こすポストデコードピクセルアップスケーラーを使用せずに、より鮮明な毛穴、まつげ、帽子の縫い目を必要とする場合に使用します。SamplerCustomAdvanced(#288)。アップスケーリング後の洗練パス。第1パスで設定されたアイデンティティを保持しながら、特徴をシャープにするためにガイダンスを適度に調整します。LTXVSpatioTemporalTiledVAEDecode(#377)。フレーム間のタイルシームを削減する時間認識デコーダ。長いクリップでVRAMの制限に達した場合は、解像度を下げるのではなく、そのタイルレイアウトを調整することをお勧めします。MelBandRoFormerSampler(#355)。ガイダンスのためにのみ使用されるボーカル分離。音源オーディオがノイズの多い場合は、オリジナルまたは無音のオーディオに切り替えて、口の動きにアーティファクトが伝播しないようにします。
オプションの追加機能#
- 顔画像の質は重要です。中立的でよく照らされた正面またはわずかに3/4の写真を使用し、パフォーマンスと似た年齢と表情を持ちます。
- リファレンスビデオを安定させてください。静止または三脚ショットは、特に中距離およびクローズアップショットで最も安定したLTX-2.3-Video-Face-Swapの結果を生み出します。
- プロンプトは簡潔にするべきです。シーンとアクションを1つの段落で述べ、アイデンティティ形容詞はアクションプロンプトではなく顔プロンプトに予約してください。
- オーディオガイダンスはオプションです。明確なスピーチは口の形を改善し、音楽のみのトラックはほとんど効果がないため、視覚に計算を集中させるために無音を選択してください。
- 低VRAMまたはCPUのみの実行のために、GGUF UNetビルドを優先し、最新のGPUでの高スループットのために、FP8トランスフォーマ専用ウェイトは良いデフォルトです。
- 責任を持って使用してください。交換する類似性の同意を得て、適用される法律やプラットフォームのポリシーに従ってください。
謝辞#
このワークフローは、以下の作品およびリソースを実装および構築しています。LTX-2.3モデルに感謝し、EyeForAILabsのYouTubeチュートリアルに感謝します。詳細については、以下のリンクされたオリジナルのドキュメントおよびリポジトリを参照してください。
リソース#
- LTX-2.3/LTX-2.3 Model
- Hugging Face: Hugging Face Model
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: EyeForAILabs YouTube Tutorial
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者および管理者によってjson
提供されるライセンスおよび条件に従う必要があります。