
LTX 2.3 Sulphur T2V ワークフロー: プロンプトからシネマへ、マイクロエクスプレッション、ムード、ガイドカメラ#
LTX 2.3 Sulphur T2V ワークフローは、よく書かれたプロンプトを、信じられるマイクロエクスプレッション、雰囲気のあるシーン詳細、ストーリー主導の動きを強調するシネマティックなクリップに変換します。蒸留された LTX 2.3 ジェネレーションパスと Sulphur スタイルガイダンス、オプションのカメラ制御ガイダンス、および信頼性のあるテキスト-トゥ-ビデオ結果のための安定したタイル化デコードパスを組み合わせています。
ComfyUI セットアップは、基礎的な演技ビートと制御可能なカメラの動きを望むクリエイター向けに設計されており、物語の忠実性と時間的安定性をバランスよく保ちます。純粋なテキスト-トゥ-ビデオを実行するか、静止画像から開始し、安定したファーストパスの潜在をクリーンな編集者フレンドリーなシーケンスにデコードし、簡単に編集できるプレースホルダーオーディオトラックを追加できます。
Comfyui LTX 2.3 Sulphur T2V ワークフローの主要モデル#
- Lightricks LTX‑2.3 22B FP8 チェックポイント。生成とデコードを駆動するベースのテキスト-トゥ-ビデオモデル。 Model repository
- LTX‑2.3 蒸留 LoRA。品質を維持しながら、より高速で低ステップのサンプリングと安定した動きを可能にする蒸留アダプター。 Model family
- LTX‑2.3 空間アップスケーラー x2。実験用にグラフに含まれており、デフォルトのエクスポートパスはこのセットアップでクリーンな結果を得るために安定したファーストパスデコードを使用します。 Upscaler
- LTX‑2 19B LoRA カメラ制御ドリー左。シーンがそれを必要とする場合の安定したドリーイン動作と穏やかな視差のためのオプションのガイダンス。 LoRA
- LTX テキストエンコーダー (Gemma 3 12B バリアント)。プロンプトとビートノートを解釈するトークナイザーと埋め込みモデル。 Text encoders
- LTX オーディオ VAE。結果のビデオが NLEs にクリーンにロードされるように、サイレントオーディオストリームをパックします。 Model repository
- Sulphur LoRA (バンドル)。表現力豊かでありながら抑制されたマイクロエクスプレッションとシネマティックなカラーハーモニーのためにキュレーションされたスタイルと演技ビートアダプター。
Comfyui LTX 2.3 Sulphur T2V ワークフローの使用方法#
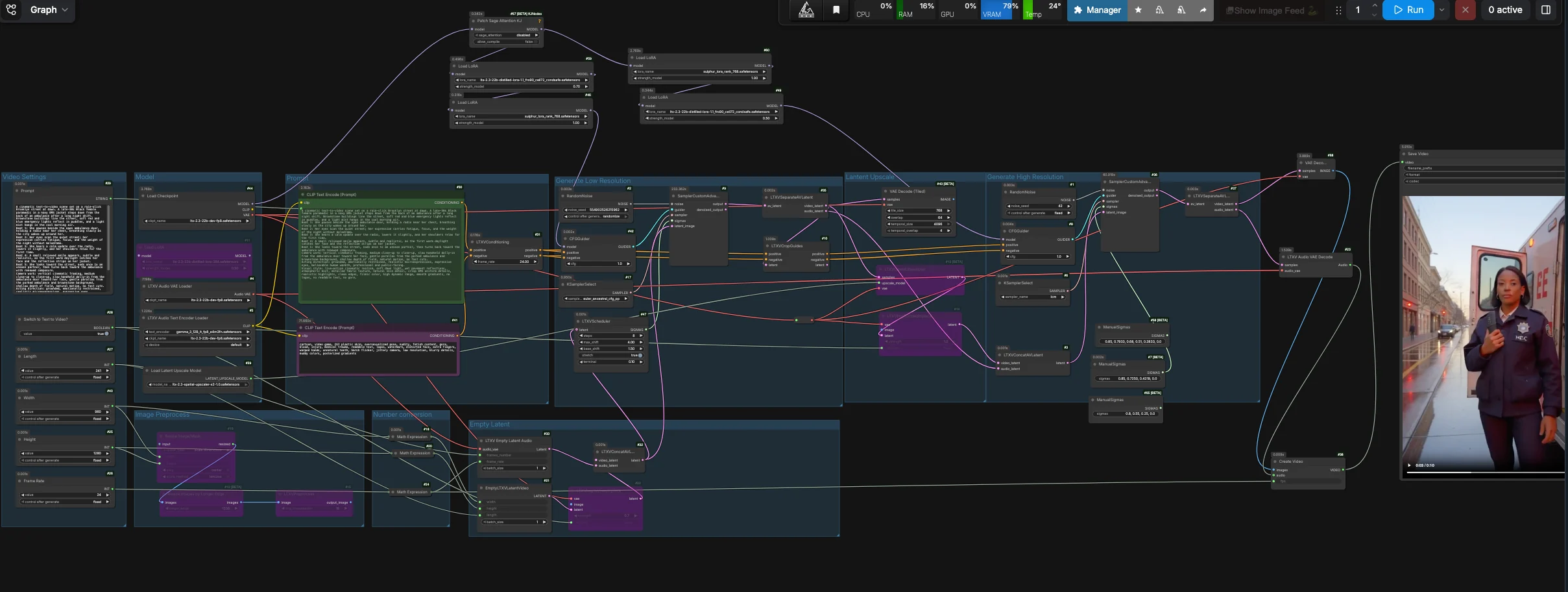
このワークフローは、安定したファーストパスのテキスト-トゥ-ビデオパスをデフォルトで使用します。コヒーレントなビデオ潜在を生成し、ビデオとオーディオのレーンを分離し、タイル化された VAE デコードでファーストパスのビデオ潜在をデコードし、フレームとサイレントオーディオを編集可能なビデオファイルにパッケージ化します。潜在のアップスケールとリファインメントノードは高度な実験のためにグラフ内に残されていますが、デフォルトの出力は信頼性のためにそのブランチをバイパスします。
モデル#
モデルグループは、LTX‑2.3 FP8 チェックポイント、LTX テキストエンコーダー、オーディオ VAE、および使用されるアダプターをロードします。蒸留および Sulphur LoRAs はベースモデルに適用され、シーンがビートと顔の意図に密接に従うようにします。ドリーモーションを希望する場合は、提供された LoraLoader ノードでカメラ制御 LoRA を有効にします。デフォルトのパスは、プライマリーサンプラーを CFGGuider (#42) に通し、リファインメントブランチは手動実験のために利用可能にされています。
プロンプト#
シーンを Prompt フィールド (#29) に短いビートラインと簡単なカメラノートとして書きます。ポジティブテキストは CLIPTextEncode (#30) によってエンコードされ、CLIPTextEncode (#41) のキュレーションされたネガティブリストは CGI の輝き、アーティファクト、ジッター、およびハードフリッカーを抑制します。演技の方向を目、肩、呼吸に特化して簡潔に保ち、このワークフローに調整されたマイクロエクスプレッションを解放します。「ゆっくりとしたハンドヘルドドリーイン」や「穏やかな視差」などのカメラ言語は、スケジューラーおよびオプションのカメラ LoRA によくマッピングされます。
ビデオ設定#
ビデオ設定グループ (#40, #25, #26, #27) で出力の Width、Height、Frame Rate、および Length を選択します。内部的には、ワークフローは生成パスのために半解像度の潜在を導出し、時間的コヒーレンスを向上させ、次にその安定した潜在を直接デコードします。Switch to Text to Video? (#28) を使用して純粋な T2V を実行するか、それをオフにしてイメージプリプロセスパスを通して開始静止画像を供給し、制御された I2V にします。寸法は高速でタイルフレンドリーなデコードのために一般的な倍数に保つべきです。
空潜在#
EmptyLTXVLatentVideo (#21) は設定に応じて空のビデオ潜在を作成し、LTXVEmptyLatentAudio (#33) はエディターフレンドリーなコンテナマックスのために一致するオーディオ潜在を作成します。画像から始めたい場合は、LTXVImgToVideoInplace (#22) が潜在タイムラインに制御可能な strength で注入できます。bypass がオンの場合、ノードは純粋なテキストドリブンの初期化を生成します。
低解像度の生成#
オーディオとビデオの潜在は LTXVConcatAVLatent (#32) によってマージされ、LTXVScheduler (#47) によってタイミングが設定され、スムーズな動きとカメラの移動のためのビデオ対応のシグマスケジュールが設定されます。CFGGuider (#42) は、ポジティブとネガティブの条件付けをモデルスタックと組み合わせ、SamplerCustomAdvanced (#9) がプライマリー生成パスを実行します。次に、LTXVSeparateAVLatent (#35) がクリップをビデオとオーディオの潜在に戻して分割します。デフォルトの出力はこの安定したビデオ潜在をタイル化デコードに使用します。
オプションの潜在アップスケール#
LTXVLatentUpsampler (#13) は、時間的構造を維持しながら LatentUpscaleModelLoader (#39) から LTX x2 空間アップスケーラーを適用します。LTXVImgToVideoInplace (#14) は、既存のオーディオレーンとともにアップスケールされたビデオ潜在を再ラップします。このブランチは高解像度のリファインメント実験を行いたい場合に利用可能ですが、デフォルトの最終出力には接続されていません。
オプションのリファインメント#
リファインメントブランチは、CFGGuider (#8) と SamplerCustomAdvanced (#36) を使用して短い手動のシグマスケジュールを実行します。高解像度パスをテストしたい高度なユーザーにとって有用ですが、デフォルトのワークフロー出力は、このブランチをバイパスします。なぜなら、安定したファーストパスのタイル化デコードが提供された RunComfy セットアップでクリーンな結果をもたらすからです。
出力#
VAEDecodeTiled (#43) は LTXVSeparateAVLatent (#35) から安定したビデオ潜在をデコードし、LTXVAudioVAEDecode (#23) はエディターを満足させるサイレントトラックを生成します。CreateVideo (#38) は選択した fps でシーケンスを組み立て、SaveVideo (#45) はディスクに書き込みます。安定した動き、クリーングラデーション、および制御されたカメラフローを備えた共有可能なビデオを取得します。
Comfyui LTX 2.3 Sulphur T2V ワークフローの主要ノード#
LTXVScheduler (#47)#
ファーストパスのビデオ対応シグマシーケンスを編成します。そのシフトコントロールは、フレーム間でどれだけ強く動きが蓄積されるかに影響します。シフトが高いほどカメラ移動と速い被写体の動きを強調し、低い値はより安定したフレーミングを好みます。カメラ制御 LoRA を有効にすると、控えめなシフトが最適です。
LTXVCropGuides (#10)#
テキストから重要な領域、特に顔が高い忠実度で解決されるようにするクロップ対応の条件付けチャネルを生成します。グローバルサンプラーを過度にクランクアップせずにマイクロエクスプレッションと目の詳細をステアリングするために使用します。クローズアップがソフトに見える場合は、演技ビートを締めて、Crop Guides が微調整を行うようにします。
LTXVImgToVideoInplace (#22, #14)#
静止画像を時間的一貫性のある潜在に変換するか、アップスケールされた潜在を再ラップしてオプションのリファインメントを行います。strength コントロールは、タイムライン全体でソース画像がどれだけ保持されるかを設定します。値が低いほど生成適応が許可され、値が高いほどフレーミングとアイデンティティが固定されます。bypass を切り替えて I2V と純粋な T2V の間をスムーズに切り替えます。
LTXVLatentUpsampler (#13)#
LTX x2 空間アップスケーラーを潜在で適用し、テクスチャとエッジを持ち上げてオプションのリファインメント実験を行います。デフォルトのエクスポートパスはこのノードに依存していないため、メインの出力チェーンを変更せずに安定したファーストパス出力をリファインメントブランチと比較できます。
CFGGuider (#42, #8) と KSamplerSelect (#17, #6)#
これらのペアリングは、モデルがテキストにどれだけ厳密に従うか、サンプリングをどれだけ積極的に行うかを定義します。ビデオのリアリズムのためにガイダンスを保守的に保ちます。上げるとプロンプトの適合性が向上する可能性がありますが、動きが硬直したり、ちらつきが増えたりすることがあります。デフォルトのエクスポートは、安定した動きのためにプライマリーサンプラーに依存し、セカンダリーサンプラーはオプションのリファインメントテスト用に予約されています。
オプションの追加#
- 意図とボディランゲージを説明する 3 から 6 のビートを書きます。プロットではなく、「目が柔らかくなる」や「肩が緩む」などの具体的なキューからマイクロエクスプレッションが生まれます。
- カメラの言語をコンパクトに保ちます: 1 つの動詞と主語、たとえば「彼女の顔にゆっくりとしたドリーイン」や「駐車中の車からの穏やかな視差」など。
- 静的なフレーミングを希望する場合は、カメラ制御 LoRA を無効にし、スケジューラーのシフトを少し減らします。より多くの移動を希望する場合は、LoRA を有効にしてシフトを少し増やします。
- 予測可能なタイル化とデコードのために、幅と高さを 32 のクリーンな倍数にします。
- 再現性のために、
RandomNoise(#2, #1) でシードをロックします。バリエーションを探索する際には、1 つのシードだけを変更します。 - ネガティブプロンプトはすでに CGI アーティファクトとちらつきを抑制しています。ポジティブテキストがスタイルと意図を伝えるように集中させてください。
謝辞#
このワークフローはjson 実装され、次の作品やリソースに基づいて構築されています。ワークフローレファレンスのために RunningHub に感謝し、Lightricks に LTX 2.3 モデル、蒸留 LoRA と空間アップスケーラー、カメラ制御 LoRA、Comfy-Org に LTX テキストエンコーダーの貢献とメンテナンスに感謝します。権威ある詳細については、以下にリンクされたオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- RunningHub/Workflow Reference
- ドキュメント / リリースノート: Post
- Lightricks/LTX-2.3-fp8
- Hugging Face: Lightricks/LTX-2.3-fp8
- Lightricks/LTX-2.3
- Hugging Face: Lightricks/LTX-2.3
- Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Hugging Face: Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Comfy-Org/ltx-2
- Hugging Face: Comfy-Org/ltx-2
注: 参照されているモデル、データセット、およびコードの使用は、それぞれの著者およびメンテナーによって提供されるライセンスおよび条件に従います。