
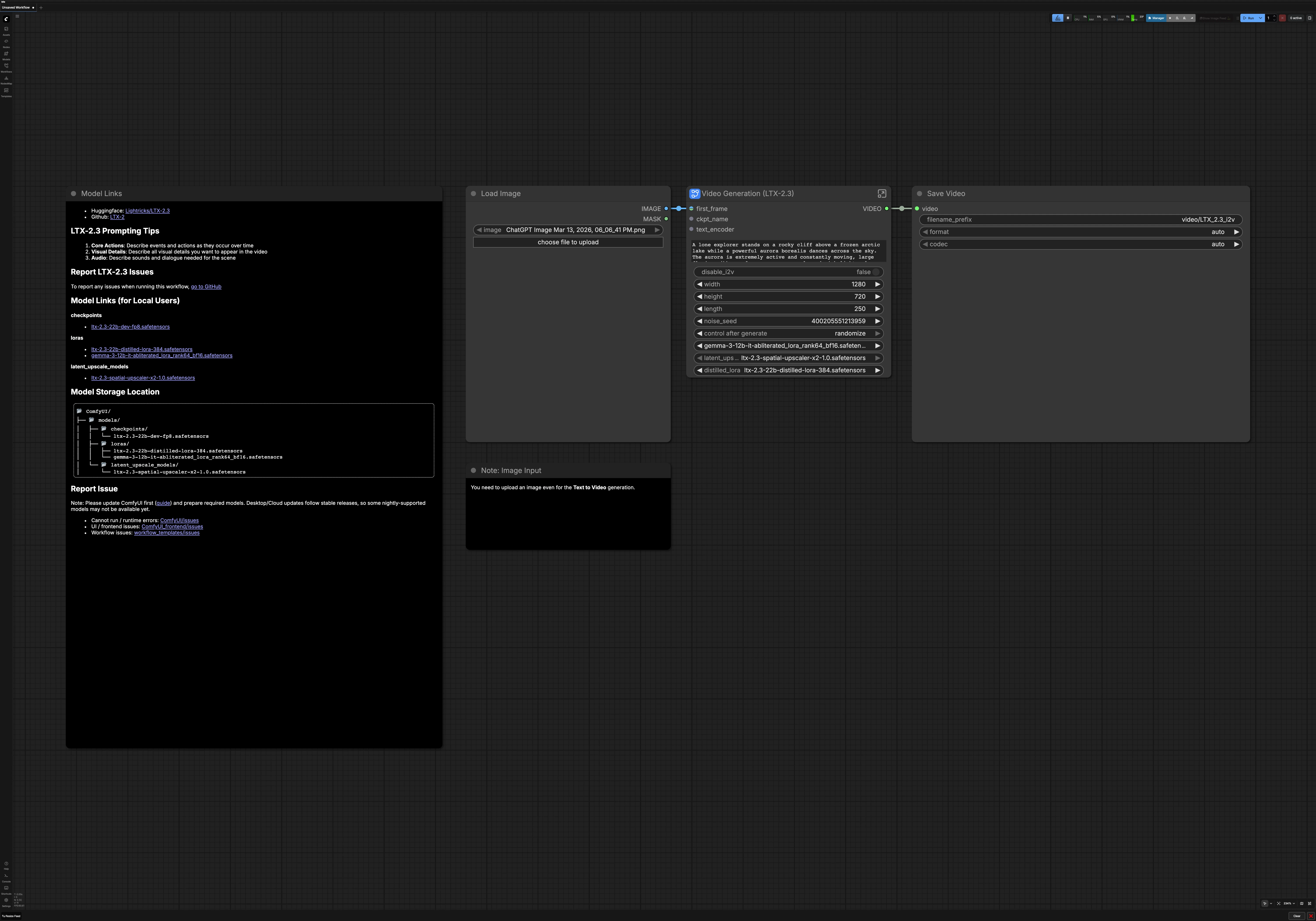
ComfyUI のための LTX 2.3 Image to Video#
このワークフローは、LTX 2.3 Image to Video を使用して、単一の画像または純粋なテキストプロンプトを滑らかで映画のような AI ビデオに変換します。手動の配線なしで高いビジュアルコヒーレンス、強力なシーンの一貫性、磨かれたモーションを求めるクリエイター向けに構築されています。RunComfy または任意の ComfyUI 環境で使用して、プロンプトに忠実なダイナミックでスタイライズされた結果を生成します。
グラフは 2 つのクリエイティブモードをサポートしています:最初のフレームをビジュアルアンカーとして使用する画像からビデオへの変換、または言語によって完全にガイドされるテキストからビデオへの変換。自動プロンプト強化、シャープなディテールのための潜在的アップスケーリング、および最終的な LTX 2.3 Image to Video レンダリングが公開準備が整うようにオプションのオーディオデコードも含まれています。
ComfyUI LTX 2.3 Image to Video ワークフローの主要モデル#
- Lightricks LTX 2.3 22B ビデオモデル。テキストとオプションの画像ガイダンスから時間的一貫性のあるモーションとビジュアルを合成するコアビデオディフュージョントランスフォーマー。モデルファイルとドキュメントは Hugging Face で、コードレベルのリファレンスは GitHub で入手可能です。
- LTX Audio VAE。モデルのオーディオ潜在をオーディオトラックにデコードするために使用されるオーディオ可変オートエンコーダ。LTX 2.3 リリースと共に Hugging Face で配布されています。
- LTX 2.3 Spatial Upscaler x2。最終的な高解像度のサンプリングパスの前にシャープネスと空間的忠実度を向上させる潜在空間スーパー解像度モデル。Hugging Face の LTX 2.3 リポジトリで利用可能です。
- Gemma 3 12B Instruct テキストエンコーダと LoRA。プロンプトの理解とフレージングを改善するためにここで使用されるコンパクトな命令調整テキストエンコーダと LoRA。このテンプレートで使用されるパッケージ化されたエンコーダと LoRA の重みは Hugging Face の Comfy-Org LTX-2 アセットで提供されています。
ComfyUI LTX 2.3 Image to Video ワークフローの使用方法#
高レベルでは、プロンプトとオプションの最初のフレームがエンコードされ、低解像度の潜在ビデオがサンプリングされ、その後潜在空間でアップスケールされ、高解像度で洗練されます。結果はフレームとオーディオにデコードされ、最終的な MP4 にコンポーズされます。実行前にいつでも画像からビデオ、またはテキストからビデオに切り替えることができます。
- モデル
- このグループは LTX 2.3 チェックポイント、オーディオ VAE、およびテキストエンコーダをロードします。また、LTX 2.3 LoRA をベースモデルに適用して命令の追従性を改善します。これらは一緒に LTX 2.3 Image to Video パイプラインの基盤を定義します。通常はここで何かを変更することはありませんが、モデルのバリアントや LoRA スタイルを交換する場合を除きます。
- プロンプト
- シーンの説明とオプションのネガティブを入力します。テキストはポジティブとネガティブの両方のコンディショニングのためにエンコードされ、選択したフレームレートとペアリングされるため、モーションプランニングがタイミングと一致します。動詞を使用して言語を時間に意識させ、たとえば「カメラが前進する」や「葉が風に舞う」のようにします。ネガティブプロンプトは、透かしや漫画風の単純化などの不要なアーティファクトを避けるのに役立ちます。
- プロンプト強化
- グラフには、画像とテキストを分析して、より強力で時間に意識したプロンプトドラフトを生成するヘルパーが含まれています。これにより、LTX 2.3 Image to Video を映画のようでアクション駆動な説明に向けるのが容易になります。特に、単一の静止画から始めて意図的に感じるモーションを望むときに役立ちます。プレビュー ノードを使用して、生成前に強化されたテキストを検査できます。
- ビデオ設定
- 画像からビデオへの変換を実行するか、シンプルなトグルでテキストからビデオへの変換に切り替えます。ターゲットプラットフォームに合わせて幅、高さ、持続時間、フレームレートを設定します。これらの設定は潜在的割り当てと下流のデコードを駆動するため、クリエイティブな意図と同期させてください。広く公開する予定がある場合は、コーデックに優しい寸法とタイミングを優先してください。
- 画像前処理
- 最初のフレームは、構図を保ちながらモデルに優しいアスペクトにリサイズおよび正規化されます。軽いプリフィルターがエッジを安定させ、モーション中に輝きが発生する可能性のある圧縮ノイズを軽減します。画像をレイアウトと色を提案するためだけに使用する場合でも、このステップは重要です。
- 空の潜在
- ワークフローは、寸法、持続時間、フレームレートに基づいて空のビデオおよびオーディオ潜在を割り当てます。これにより、サンプラーのためのクリーンなキャンバスが提供され、オーディオとビデオの長さが一致します。再現性が必要な場合は決定論的にノイズが生成され、ラン間のバリエーションのためにはランダム化されます。
- 低解像度生成
- 最初のサンプリングパスは、コンパクトな潜在ビデオにモーションと構造を切り取ります。画像からビデオへの変換を使用している場合は、
LTXVImgToVideoInplace(#249) が最初のフレームをビジュアルアンカーとして挿入し、モーションが一貫したスタートポイントから進化します。ポジティブおよびネガティブテキストからのコンディショニングがコンテンツとスタイルをガイドし、ManualSigmas(#252) とKSamplerSelectがノイズが時間とともにどれだけ積極的に除去されるかを定義します。LTXVCropGuides(#212) はプロンプトと一致するフレーミングを維持するのに役立ちます。生成されたオーディオビデオ潜在は、個別の処理のために分割されます。
- 最初のサンプリングパスは、コンパクトな潜在ビデオにモーションと構造を切り取ります。画像からビデオへの変換を使用している場合は、
- 潜在アップスケール
- 高解像度の改良にコミットする前に、
LTXVLatentUpsampler(#253) が低解像度の潜在に x2 空間的アップスケーラーを適用します。潜在空間でこれを行うことで、学習されたモーションを保持しつつディテール容量を向上させることができます。アーティファクトを導入せずにシャープさを追加する安全な方法です。
- 高解像度の改良にコミットする前に、
- 高解像度生成
- 2 番目のサンプラーがアップスケールされた潜在をより大きな空間サイズで洗練し、テクスチャ、照明、小さな動きをロックインします。テキストからビデオへの実行時には、以前の画像からビデオへのステップをバイパスでき、
LTXVImgToVideoInplace(#230) は単に潜在を通過させます。VAEDecodeTiled(#251) がビデオ潜在を効率的にフレームにデコードします。並行して、オーディオ潜在が LTX Audio VAE でデコードされ、両方のストリームがフレームに正確になります。
- 2 番目のサンプラーがアップスケールされた潜在をより大きな空間サイズで洗練し、テクスチャ、照明、小さな動きをロックインします。テキストからビデオへの実行時には、以前の画像からビデオへのステップをバイパスでき、
- エクスポート
CreateVideo(#242) が選択したフレームレートでフレームとオーディオを単一のビデオにマルチプレックスします。トップレベルのSaveVideoノードが最終ファイルを ComfyUI 出力に書き込み、すぐにダウンロードできるようにします。LTX 2.3 Image to Video レンダリングは、今すぐプレビューまたは公開する準備が整いました。
ComfyUI LTX 2.3 Image to Video ワークフローの主要ノード#
LTXVImgToVideoInplace(#249 および #230)- 静止画をビデオ潜在に変換するか、無効化された場合は潜在を通過させます。最初のフレームをレイアウト、パレット、キャラクター配置を定義するために使用する場合に使用します。プロンプトからのみモーションが出現することを好む場合は、テキストからビデオへのスイッチをトグルします。オペレーターファミリーのドキュメントは、GitHub の ComfyUI 統合で維持されています。
LTXVConditioning(#239)- エンコードされたポジティブおよびネガティブテキストをフレームレートと組み合わせて、コンテンツとモーションテンポの両方を操縦するコンディショニングを生成します。時間の経過に伴う変化を説明する短く明確な文を好み、アーティファクトを抑制したいネガティブにはネガティブを予約します。このノードは、サンプラーに触れずにスタイルとシーンの動作を調整するための最も効果的な場所です。
ManualSigmas(#252) とKSamplerSelect- ノイズスケジュールとサンプラーが一緒に動作し、大きなモーションと細部をトレードオフします。初期のノイズが大きな動きを促進し、後のステップでテクスチャを統合します。良いプロンプトと画像ガイドがある場合にのみ、これらを調整してください。基礎となるサンプリングコントロールは標準の ComfyUI セマンティクスに従い、LTX リポジトリのリファレンス実装を参照してください。GitHub で確認できます。
LTXVLatentUpsampler(#253)- 潜在空間で LTX 2.3 空間的アップスケーラーを適用し、次のステージで高解像度で洗練させることができます。余分なシャープネスが必要な場合や大きなフォーマットを配信する計画がある場合に使用します。x2 モデルは Hugging Face で LTX 2.3 と共に配布されています。
VAEDecodeTiled(#251) とCreateVideo(#242)- タイル化されたデコードにより、高解像度でのメモリスパイクを防ぎ、一貫したフレーム品質を保証します。その後、
CreateVideoがフレームとデコードされたオーディオトラックを選択した fps で最終的な MP4 に組み立てます。再生ドリフトを避けるために、コンディショニング時に使用した値と fps を一貫させてください。
- タイル化されたデコードにより、高解像度でのメモリスパイクを防ぎ、一貫したフレーム品質を保証します。その後、
オプションのエクストラ#
- テキストからビデオを使用する場合でも、最初のフレーム画像をアップロードする必要があります。トグルは生成中には無視しますが、UI はプレースホルダー画像を必要とします。
- LTX 2.3 Image to Video プロンプトでは、コアアクションを先行させ、次にビジュアルの詳細、最後に雰囲気を設定します。「ゆっくり」「突然」「続けて」などの時間に関連する言葉がモーションの計画に役立ちます。
- ネガティブプロンプトを使用して、「ウォーターマーク」や「字幕」や「静止フレーム」などのオーバーレイや UI アーティファクトを避けてください。
- スタイルが強すぎるまたは弱すぎる場合は、別の LoRA を試すか、LoRA ローダーでその重みを調整してください。ベースモデルのルックに頼るために LoRA を削除することもできます。
- テキストを反復する際には固定ノイズシードを再利用し、ショットをロックしたらバリエーションのためにランダム化してください。
謝辞#
このワークフローは、以下の作品やリソースを実装し、それに基づいて構築されています。Lightricks による LTX-2.3 と EyeForAILabs による EyeForAILabs YouTube Tutorial の貢献とメンテナンスに心より感謝します。権威ある詳細については、以下にリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: [EyeForAILabs YouTube Tutorial](http://www.youtube.com/@eyeforailabsjson
)
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.