
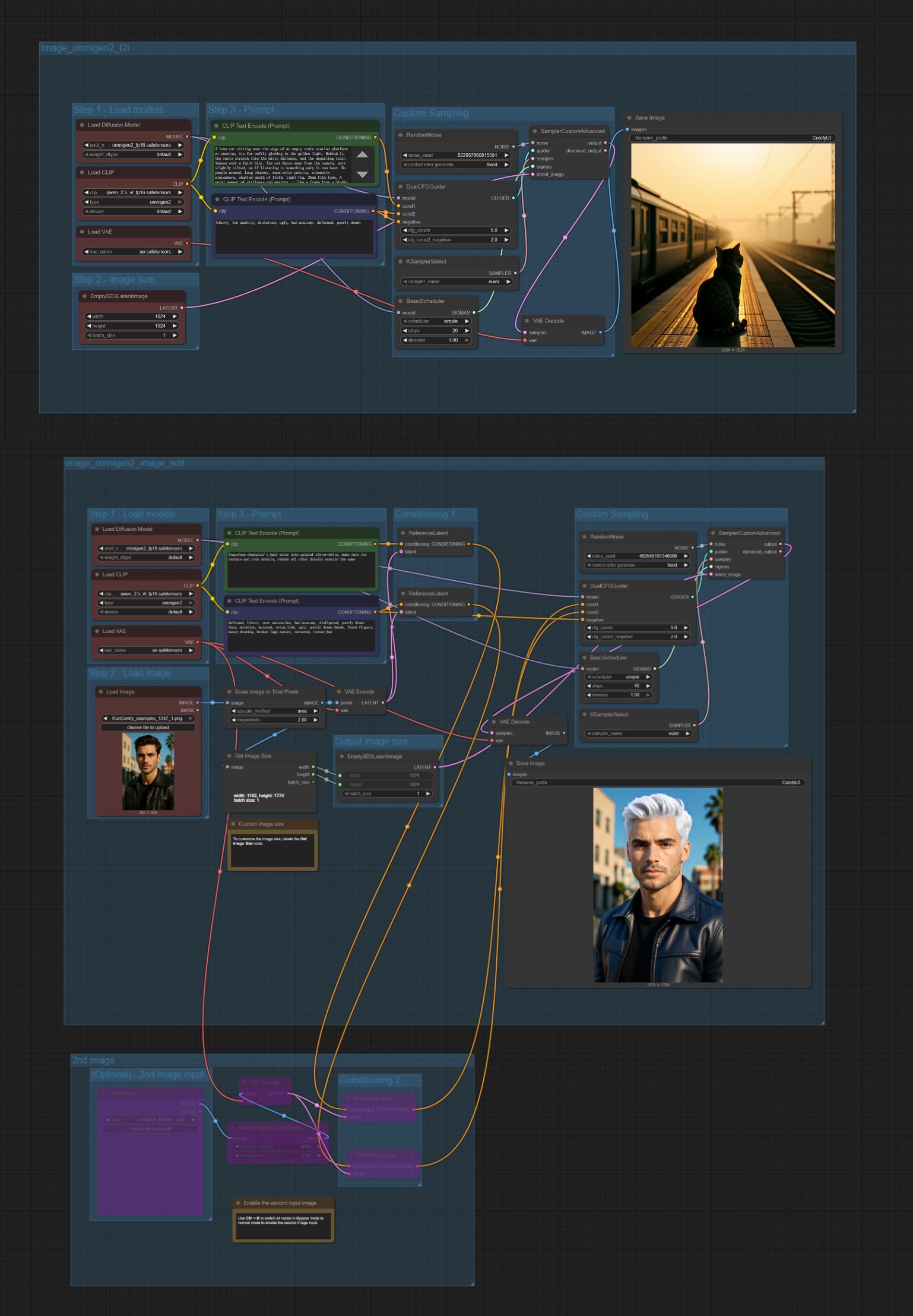




What is the OmniGen2 ComfyUI Workflow?#
The OmniGen2 ComfyUI workflow brings unified multimodal generation to your fingertips, combining text-to-image synthesis and instruction-based image editing in a single, powerful framework. Think of it as having a creative AI assistant that not only generates stunning images from your text descriptions but also understands and executes complex editing commands with remarkable precision.
This workflow leverages a sophisticated 7B parameter model built on the Qwen 2.5 VL foundation, featuring a unique dual-path Transformer architecture. What makes this model special is its decoupled design - using separate pathways for text and image generation, allowing it to maintain exceptional language understanding while delivering high-fidelity visual outputs that stay true to your creative vision.
Key Features and Benefits of OmniGen2#
Dual Generation Modes: OmniGen2 creates new images from text or edits existing ones with natural language commands through the intuitive interface.
Advanced Architecture: The OmniGen2 dual-path design separates text and image processing for optimal performance.
Compositional Understanding: OmniGen2 handles complex multi-element prompts with exceptional accuracy in every generation.
Precise Image Editing: Make targeted changes while preserving the rest of your image perfectly using OmniGen2 advanced algorithms.
Multimodal Reflection: OmniGen2 self-analyzes and refines outputs for improved results.
How to Use OmniGen2 in ComfyUI#
OmniGen2 Text-to-Image Workflow#
Set your image dimensions
- Use the EmptySD3LatentImage node to define output size for OmniGen2:
- Adjust width and height based on your OmniGen2 needs
- Keep batch_size at 1 for single image generation
Craft your text prompt
- In the CLIP Text Encode (Prompt) nodes for OmniGen2:
- Write detailed, descriptive prompts in the first encoder
- Leave the second encoder empty or add negative prompts
- OmniGen2 excels with complex compositional descriptions
Generate and save
- Hit
Runto create your OmniGen2 image - The VAE Decode converts latents to final image
- Save Image automatically saves your OmniGen2 creation to output folder
OmniGen2 Image Editing Workflow#
Upload your source image
- Use the Load Image node to import the image you want to edit with OmniGen2
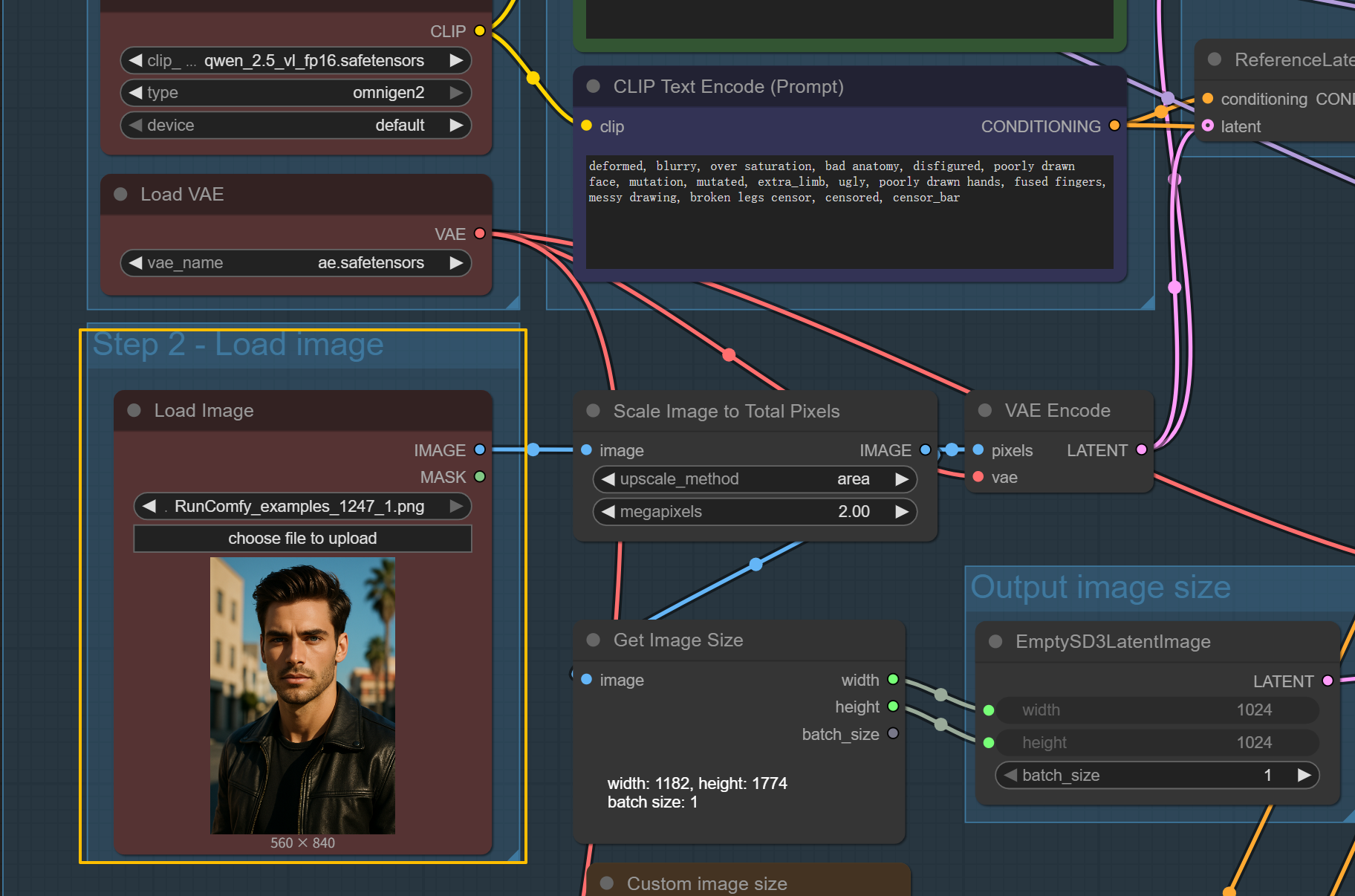
Write your editing instruction
- In the CLIP Text Encode (Prompt) node for OmniGen2:
- Describe what changes you want clearly and specifically
- Examples: "Transform character's hair color into natural silver-white", "Add aviator sunglasses"
- Natural language commands work perfectly with OmniGen2
Configure OmniGen2 editing parameters
- Scale Image to Total Pixels node:
- upscale_method: area (maintains quality during resizing)
- megapixels: 2.00 (controls total pixel count)
- This resizes your image to approximately 2 million pixels total
- For example: would scale a 1920x1080 image to maintain ~2MP
- Higher values = more detail but slower processing
- Lower values = faster generation but less detail
- 2.00 is optimal for editing capabilities <img src="https://cdn.runcomfy.net/workflow_assets/1247/readme01.webp" alt="OmniGen2" width="650"/>
- VAE Encode converts your scaled image to latent space
Optional: Enable second image input
- The purple (bypassed) nodes allow multi-image operations:
- Press Ctrl+B to toggle bypass mode
- Upload a second image for style transfer or object insertion
- Perfect for tasks like "combine elements from image 1 and image 2" <img src="https://cdn.runcomfy.net/workflow_assets/1247/readme02.webp" alt="OmniGen2" width="650"/>
Generate edited result
- Execute the OmniGen2 workflow to see your edits applied
- Results maintain high fidelity while following instructions precisely
Acknowledgments#
This ComfyUI workflow integrates the groundbreaking OmniGen2 model developed by researchers at Beijing Academy of Artificial Intelligence. Special recognition goes to the team for creating this unified multimodal generation system that pushes the boundaries of what's possible with a 7B parameter model. The architecture represents a significant advancement in balancing model efficiency with generation quality.
More Resources About OmniGen2#
OmniGen2 is released under open-source licensing, making it freely available for both research and commercial applications. For more information about OmniGen2:
- GitHub Repository - Official implementation and model architecture details: VectorSpaceLab/OmniGen2
- Project Page - Comprehensive overview with demos and technical insights: Official Page
- ComfyUI Examples - Step-by-step tutorials and additional workflows: ComfyUI Examples

