
Fish Audio S2 TTS for ComfyUI: 高品質のTTS、声のクローン作成、複数話者の対話#
Fish Audio S2 TTSは、テキストを自然な音声に変換し、短い参照クリップから声をクローンし、複数話者の会話を生成する、すぐに実行可能なComfyUIワークフローです。Fish Audio S2-Proファミリーによって駆動され、[興奮した]、[ささやき]、[笑う]などの感情と韻律タグを介して豊かなスタイルコントロールをサポートします。
このワークフローは、ComfyUI内で柔軟で表現豊かな音声合成を求めるクリエイター、プロダクトチーム、開発者に理想的です。クイックなトランスクリプトキャプチャのためのオプションの音声認識、言語自動検出、fp8およびsage_attentionを含む複数の精度選択を含みます。
注意: このワークフローは2X Large以上のマシンで実行してください。小さいインスタンスではメモリ不足(OOM)になる可能性があります。
Comfyui Fish Audio S2 TTSワークフローの主要モデル#
- Fish Audio S2-Pro — 単一話者のTTS、声のクローン作成、複数話者の対話に使用されるコア生成テキスト読み上げモデルです。広範なスタイルトークンと多言語合成をサポートしていますモデルカードで確認でき、Fish-Speechプロジェクトの一部ですリポジトリ。
- Fish Audio S2-Pro FP8 — メモリ効率の良いS2-Proのバリアントで、VRAMの必要量を最小限の品質トレードオフで削減し、制約されたGPUに推奨されますモデルカード。
- OpenAI Whisper large-v3 — 音声クローン作成プロンプトを準備する際に参照音声を自動トランスクリプトするために使用されるオプションの音声認識モデルですリポジトリ。
Comfyui Fish Audio S2 TTSワークフローの使い方#
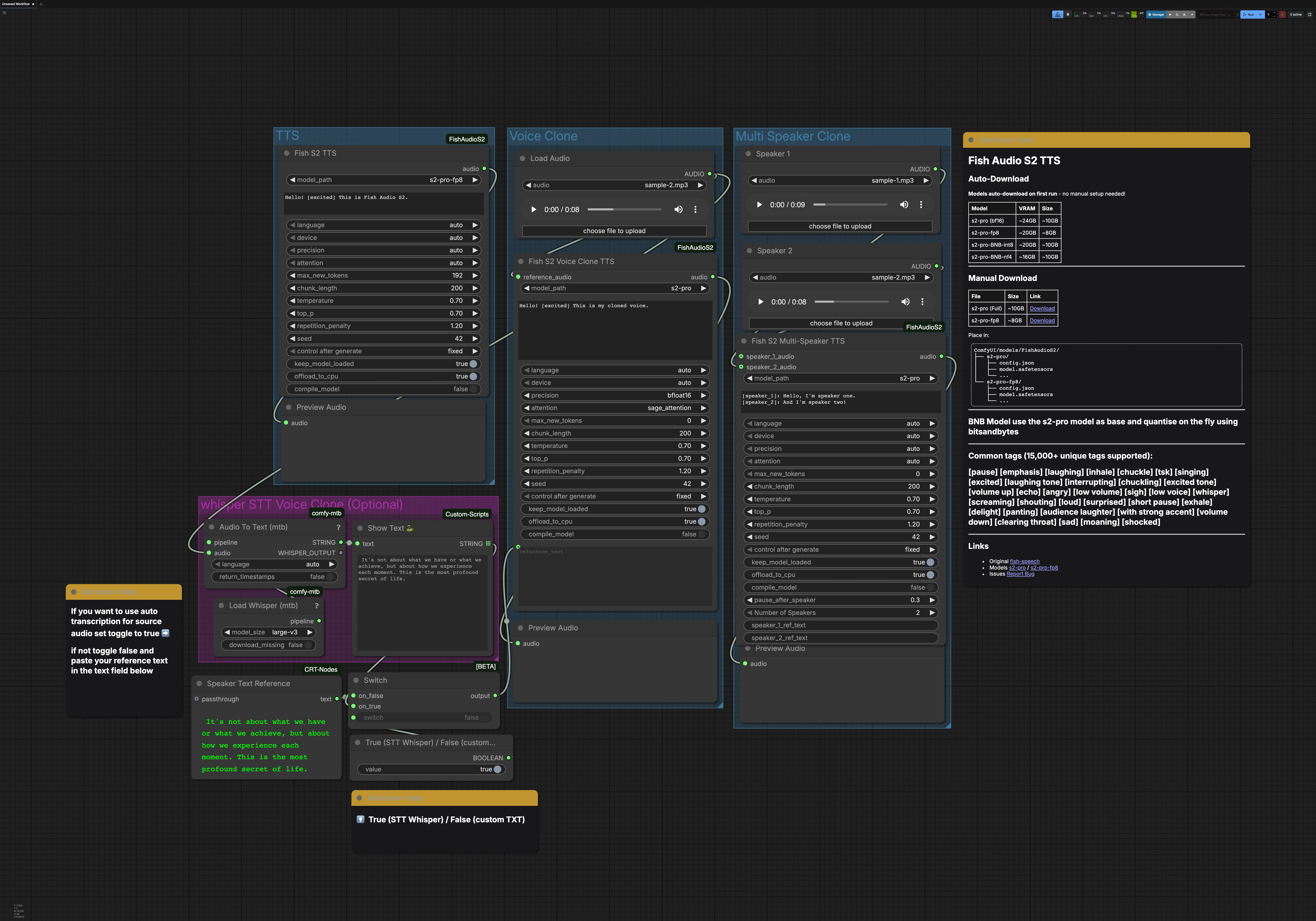
このワークフローには、TTS、Voice Clone、Multi Speaker Cloneの3つの主要パスが含まれ、独立して実行できます。オプションのWhisper STTグループは、声のクローン作成のためのトランスクリプトを生成できます。各パスはオーディオプレビューで終了し、結果を迅速に確認できます。
TTSグループ#
FishS2TTS (#42)ノードは、Fish Audio S2 TTSを使用して直接テキスト読み上げを行います。ノードのテキストボックスにスクリプトを入力し、[興奮した]、[ポーズ]、[ささやき]のようなスタイルタグを散りばめて感情とペースを形作ります。言語検出は自動で行われるため、ターゲット言語で書き込んでモデルが適応します。GPUメモリに適したS2-Proバリアントを選択し、軽量な負荷にはfp8を使用します。出力はPreviewAudioにルーティングされ、即座に聞くことができます。
Voice Cloneグループ#
LoadAudioを使用して、ターゲットの声の短くクリーンな参照クリップを提供し、それをFishS2VoiceCloneTTS (#14)にルートします。希望する話し方に合ったトランスクリプトを提供します。正確なテキストはモデルがリズムとアクセントを保持するのに役立ちます。STTグループから参照テキストを駆動するか、自分で入力し、スタイルタグを追加して感情とデリバリーを洗練させます。精度と注意のバックエンド選択は、長い行のために速度、メモリ、安定性をバランスします。合成されたクローンはPreviewAudioに送られ、迅速に反復することができます。
Multi Speaker Cloneグループ#
LoadAudioノードを使用して話者ごとに1つの参照クリップをロードし、それをFishS2MultiSpeakerTTS (#41)に接続します。[speaker_1]、[speaker_2]などで各ターンをラベル付けした対話スクリプトを提供します。このテンプレートにはデフォルトで2人の話者が含まれており、ノードは構成に応じて最大8つの異なる声をサポートします。物語の散文、タグ、対話を混ぜて各キャラクターの流れと感情をコントロールします。最終ミックスはプレビューされ、タイミングと明瞭さを確認できます。
Whisper STT for voice cloning (オプション)#
Load Whisper (mtb) (#6)は、large-v3がAudio To Text (mtb) (#7)を駆動し、参照クリップを自動的にトランスクリプトします。認識されたテキストはShowText|pysssss (#8)によって表示されます。小さなトグルはComfySwitchNode (#34)とブール制御で構築され、STT出力(true)またはText Box line spot (#31)からの自分で入力したテキスト(false)を選択できます。これはクイックなベースライントランスクリプトが必要な場合や、クローン作成のための正確なプロンプトを作成する際に便利です。
Comfyui Fish Audio S2 TTSワークフローの主要ノード#
FishS2TTS (#42)#
オプションのスタイルタグと自動言語検出を使用してテキストから単一話者の音声を生成します。ハードウェアに合わせてモデルバリアントを調整し、例えばVRAMが厳しい場合はfp8を選択します。シードコントロールを使用して再現可能なテイクを行い、代替のデリバリーを探索する際に小さな変更を加えます。長いスクリプトの場合、安定性のために最適化された注意のバックエンドを選択します。
FishS2VoiceCloneTTS (#14)#
reference_audioとreference_textに基づいてクローンされた声を作成します。安定した音調と意図したケイデンスを反映するトランスクリプトから、より良い結果が得られます。スタイルタグは最終テキストに混ぜ込んでムードを操縦し、アイデンティティを損なわずに調整します。精度と注意設定は、長い行のために品質とメモリをバランスします。
FishS2MultiSpeakerTTS (#41)#
各話者の参照音声と[speaker_n]ラベルでマークされた対話を組み合わせて複数話者の会話を合成します。必要に応じて話者の数を増やし、より強い分離のために異なるクリップを割り当てます。各話者の参照を音調で一貫させ、ブレンドを避けます。シードを使用して、マルチテイクシーンをレンダリングする際に決定的なミキシングを行います。
オプションの追加#
- スタイルタグを慎重に使用します。最初は[興奮した]、[ささやき]、[強調]、[ポーズ]などから始め、必要に応じて明瞭さを高めます。
- 声のクローン作成には、参照の開始と終了から沈黙をトリムし、背景ノイズを避けて音色を保持します。
- GPUメモリが限られている場合は、S2-Pro fp8またはランタイム量子化オプションを優先します。最大の忠実度を求める場合は高精度を使用します。
- 句読点は重要です。コンマとピリオドはフレージングを改善し、文節の境界に配置されたタグはより自然に聞こえます。
- 複数話者のスクリプトでは、1行に1つの発話を保持し、常に正しい[speaker_n]ラベルで接頭辞を付けて分離を維持します。
リソース:
- Fish Audio S2-Proモデルカード: Hugging Face
- S2-Pro fp8バリアント: Hugging Face
- Fish-Speechプロジェクト: GitHub
- ComfyUI Fish Audio S2ノード: GitHub
- Whisper large-v3: GitHub
謝辞#
このワークフローは、以下の作品やリソースを実装し、構築しています。ComfyUI-FishAudioS2 Custom NodesのSaganaki22氏、およびS2-Pro ModelのFish Audioに感謝の意を表します。権威ある詳細については、以下にリンクされたオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- Saganaki22/ComfyUI-FishAudioS2 Custom Nodes
- GitHub: Saganaki22/ComfyUI-FishAudioS2
- Fish Audio/S2-Pro Model
- Hugging Face: fishaudio/s2-pro
注意: 参照されているモデル、データセット、およびコードの使用は、それぞれの著者および管理者によって提供されたライセンスおよび条件に従います。

