
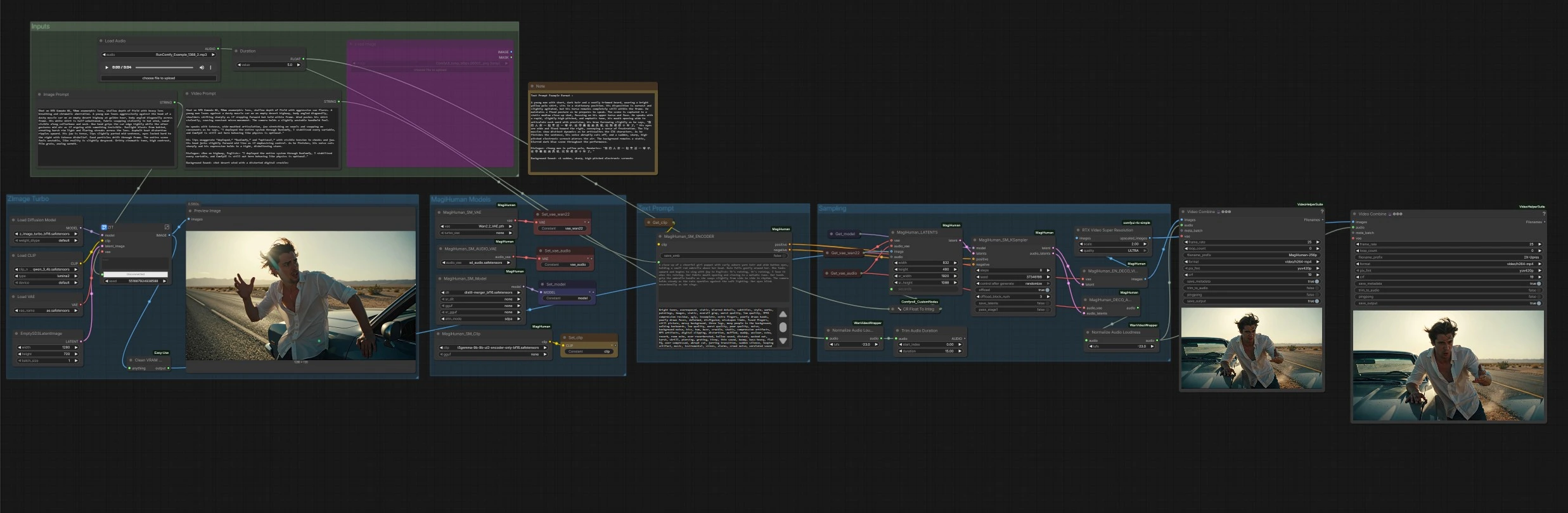
daVinci-MagiHuman トーキングデジタルヒューマンワークフロー for ComfyUI#
この ComfyUI ワークフローは、daVinci-MagiHuman を中心にフルテキストからビデオへのパイプラインを構築し、同期された音声、リップムーブメント、表情、体の微細な動きでリアルなトーキングデジタルヒューマンを生成します。これは、説明的なプロンプトからクリーンなオーディオの MP4 への迅速なワンクリックパスを望むクリエイター向けに設計されています。グラフは、新しく生成されたポートレートまたは提供された参照画像をアニメーション化し、ビデオと音声を一緒にレンダリングし、オプションでアップスケーリングと自動オーディオラウドネス正規化を行います。
daVinci-MagiHuman のコアは、単一ストリームの Transformer を使用して、一つのプロンプトからビデオとオーディオを共生成し、短いクリップでもタイミングとリップシンクの忠実性を維持します。この ComfyUI 実装は、コントロールをシンプルに保ちます: ルックを定義するための Image Prompt、パフォーマンスとダイアログを定義するための Video Prompt を書き、クリップの Duration を設定して実行します。
ComfyUI daVinci-MagiHuman ワークフローの主要モデル#
- daVinci-MagiHuman (15B single‑stream audio‑video generator). 役割: テキストからビデオフレームと音声を共同で生成し、時間的一貫性とリップシンクを維持します。参照: GitHub, arXiv, Hugging Face.
- T5Gemma 9B encoder (UL2‑adapted). 役割: daVinci‑MagiHuman の動き、デリバリー、スタイルを導くリッチな条件付けに Video Prompt をエンコードします。参照: Hugging Face.
- Z‑Image Turbo diffusion model. 役割: アニメーションのためのアイデンティティ/参照として使用するための高品質な静止ポートレートを Image Prompt から素早く生成します。参照: Hugging Face (z_image_turbo), Hugging Face (z_image).
- Qwen 3 4B text encoder for Z‑Image Turbo. 役割: ポートレート生成を導くために Image Prompt を解析します。参照: Hugging Face file.
- Wan 2.2 VAE. 役割: MagiHuman ビデオ潜在変数を RGB フレームにデコードし、強い時間的一貫性を持たせます。参照: GitHub, Hugging Face example model.
- Audio VAE (sd_audio). 役割: MagiHuman オーディオ潜在変数をスピーチ波形にデコードし、最終ビデオと混合します。参照: MagiHuman 用のカスタムノードバンドル GitHub.
- RTX Video Super Resolution (optional). 役割: 最終エンコード前にデコードされたフレームをポストアップスケールし、知覚されるシャープネスを向上させ、圧縮アーティファクトを削減します。参照: ComfyUI ラッパー GitHub.
ComfyUI daVinci-MagiHuman ワークフローの使用方法#
全体の流れ: Z‑Image Turbo グループは Image Prompt からアイデンティティポートレートを作成します。MagiHuman Models グループは daVinci‑MagiHuman チェックポイント、ビデオ VAE、オーディオ VAE をロードし、テキストエンコーダを準備します。Text Prompt グループは Video Prompt を条件付けに変換します。Sampling グループは参照画像とプロンプトを結合したビデオとオーディオの潜在変数を生成し、両方をデコードします。最後に、Outputs ステージはフレームをオーディオと混合して MP4 にし、オプションのアップスケール版を出力します。
入力#
Image Prompt と Video Prompt テキストボックスを使用してルックとパフォーマンスを説明します。Duration コントロールはクリップの長さを秒で設定します。オーディオ駆動のバリエーションを試す予定がある場合のためにオーディオローダーが用意されていますが、このテンプレートはデフォルトでテキスト駆動モードで動作します。
ZImage Turbo#
このステージは、Z‑Image Turbo UNet と Qwen 3 4B テキストエンコーダおよびそのバンドルされた VAE を使用して Image Prompt から単一の参照ポートレートをレンダリングします。迅速でクリーンなアイデンティティ生成を最適化し、映画的な見た目を提供します。結果はプレビューされ、アニメーションの参照画像として転送されます。すでにヘッドショットがある場合は、アニメーションステージに直接画像を接続してこのステップをスキップできます。
MagiHuman Models#
ここでグラフは daVinci-MagiHuman のベースまたは蒸留されたチェックポイントと Wan 2.2 ビデオ VAE、オーディオ VAE、T5Gemma エンコーダをロードします。これによりテキストエンコーディング、ビデオ潜在変数、オーディオ潜在変数が単一ストリームサンプリングのために整列されます。環境に代替がある場合は重みを交換できます。
Text Prompt#
Video Prompt は肯定的および否定的条件付けにエンコードされます。肯定的なテキストはカメラ距離、ポーズ、言語、デリバリースタイル、および正確なダイアログ内容を説明する必要があります。否定的なテキストは、避けたい視覚的またはオーディオの欠陥をリストすることができます。エンコーダはサンプラーに両方の条件付けセットを供給し、動作、リップダイナミクス、音色を形作ります。
Sampling#
サンプラーは参照画像と要求された Duration から初期潜在シーケンスを構築し、daVinci-MagiHuman でノイズを除去して同期されたビデオとオーディオの潜在変数を生成します。ユーティリティは Duration を安定したスケジューリングのために全秒に変換します。サンプリングが完了すると、ビデオ潜在変数はビデオデコーダに、オーディオ潜在変数はオーディオデコーダに送られます。
デコード、ラウドネスとエクスポート#
ビデオ潜在変数は Wan 2.2 VAE でイメージフレームにデコードされます。オーディオ潜在変数はスピーチにデコードされ、ブロードキャストフレンドリーなラウドネスに正規化されるので、最終的な MP4 はデバイス間で一貫して再生されます。2 つのエクスポートが生成されます: ベースレンダーと RTX Video Super Resolution を使用したオプションのアップスケールレンダー。両方ともオーディオと混合して MP4 にされ、明確なファイル名プレフィックスで保存されます。
ComfyUI daVinci-MagiHuman ワークフローの主要ノード#
MagiHuman_LATENTS(#13)
ビデオとオプションのオーディオのための共同潜在キャンバスを構築し、参照画像とクリップの長さを取得します。seconds を調整して Duration を設定し、参照画像が説明する動きに対してしっかりとフレーム内に収まるようにします。ベース解像度が高いほど顔の忠実性が向上しますが、VRAM とデコード時間も増加します。
MagiHuman_SM_ENCODER(#95)
サンプラーのために Video Prompt を肯定的および否定的条件付けにエンコードします。正確な発話行を引用符で囲み、言語を指定してリップクロージャーとタイミングを改善します。否定的なフィールドを使用して「字幕」「静電気」「室内エコー」などのアーティファクトを抑制します。
MagiHuman_SM_KSampler(#9)
daVinci‑MagiHuman を使用してノイズを除去し、ビデオと音声の潜在変数を共生成します。seed は再現性を制御し、steps と内部スケジュールはスピードと詳細、動きの安定性の間のトレードオフを行います。アイデンティティを損なうことなくバリエーションを加えるには、seed を変更するか、プロンプトのパフォーマンス部分を軽く言い換えます。
MagiHuman_EN_DECO_VIDEO(#5)
ビデオ潜在変数を Wan 2.2 VAE で RGB フレームにデコードし、エクスポートまたはアップスケーリングします。このパスを使用して、最速のエンドツーエンドレンダーを実現します。長いクリップや高解像度はデコード時間を直線的に増加させます。
MagiHuman_DECO_AUDIO(#6)
オーディオ潜在変数を波形にデコードし、ラウドネス正規化を通過させて均一な再生を行います。後でオーディオ駆動の生成に切り替える場合は、外部オーディオを潜在ビルダーに接続し、このデコードパスを最終的なミキシングに使用します。
RTXVideoSuperResolution(#93)
エッジをシャープにし、リンギングを減少させるオプションのポストアップスケーラーです。適度な強度を使用して、時間的なちらつきを引き起こすことなく明瞭さを向上させます。
オプションの追加要素#
- 信頼性の高いリップシンクのためのプロンプトパターン: スピーカータグと言語、引用符で囲まれた行を含めます。例えば Dialogue: <Presenter, English>: "Welcome to the show." 配信、ショットサイズ、カメラの安定性についての簡単なメモを追加します。
- 参照ポートレートは、フレーム内に頭が完全に収まる中間クローズアップとして保持します。タイトなクロップはあごと頬の動きの余地をほとんど残しません。
- より厳密なタイミングが必要な場合は、選択した Duration に合わせてスクリプトをトリムまたは拡張します。非常に短いクリップで非常に長い文章は不自然な発音を強いることがあります。
- このテンプレートはプロンプトのみモードで動作します。オーディオ駆動のテストの場合は、外部オーディオファイルを
MagiHuman_LATENTS(#13) のオーディオ入力に接続し、Video Prompt を表情を説明するように調整します。
謝辞#
このワークフローは、以下の作品とリソースを実装し構築しています。我々は daVinci-MagiHuman に、彼らの貢献とメンテナンスに感謝します。詳細については、以下にリンクされたオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- daVinci-MagiHuman/Workflow Source
- ドキュメント / リリースノート: daVinci-MagiHuman Workflow Source
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者およびメンテナーによって提供されたライセンスおよび条件に従います。