






Nunchaku Qwen Image multi‑image editing and compositing for ComfyUI#
Nunchaku Qwen Image is a prompt‑driven, multi‑image editing and compositing workflow for ComfyUI. It accepts up to three reference images, lets you specify how they should be blended or transformed, and produces a cohesive result guided by natural language. Typical use cases include merging subjects, replacing backgrounds, or transferring styles and details from one image to another.
Built around the Qwen image family, this workflow gives artists, designers, and creators precise control while staying fast and predictable. It also includes a single‑image edit route and a pure text‑to‑image route, so you can generate, refine, and composite within one Nunchaku Qwen Image pipeline.
Note: Please select machine types within the range of Medium to 2XLarge. Using 2XLarge Plus or 3XLarge machine types is not supported and will result in a run failure.
Key models in Comfyui Nunchaku Qwen Image workflow#
- Nunchaku Qwen Image Edit 2509. Edit‑tuned diffusion/DiT weights optimized for prompt‑guided image editing and attribute transfer. Strong at localized edits, object swaps, and background changes. Model card
- Nunchaku Qwen Image (base). Base generator used by the text‑to‑image branch for creative synthesis without a source photo. Model card
- Qwen2.5‑VL 7B text encoder. Multimodal language model that interprets prompts and aligns them with visual features for editing and generation. Model page
- Qwen Image VAE. Variational autoencoder used to encode source images into latents and decode final results with faithful color and detail. Assets
How to use Comfyui Nunchaku Qwen Image workflow#
This graph contains three independent routes that share the same visual language and sampling logic. Use one branch at a time depending on whether you are editing multiple images, refining a single image, or generating from text.
Nunchaku‑qwen‑image‑edit‑2509 (multi‑image edit and composite)#
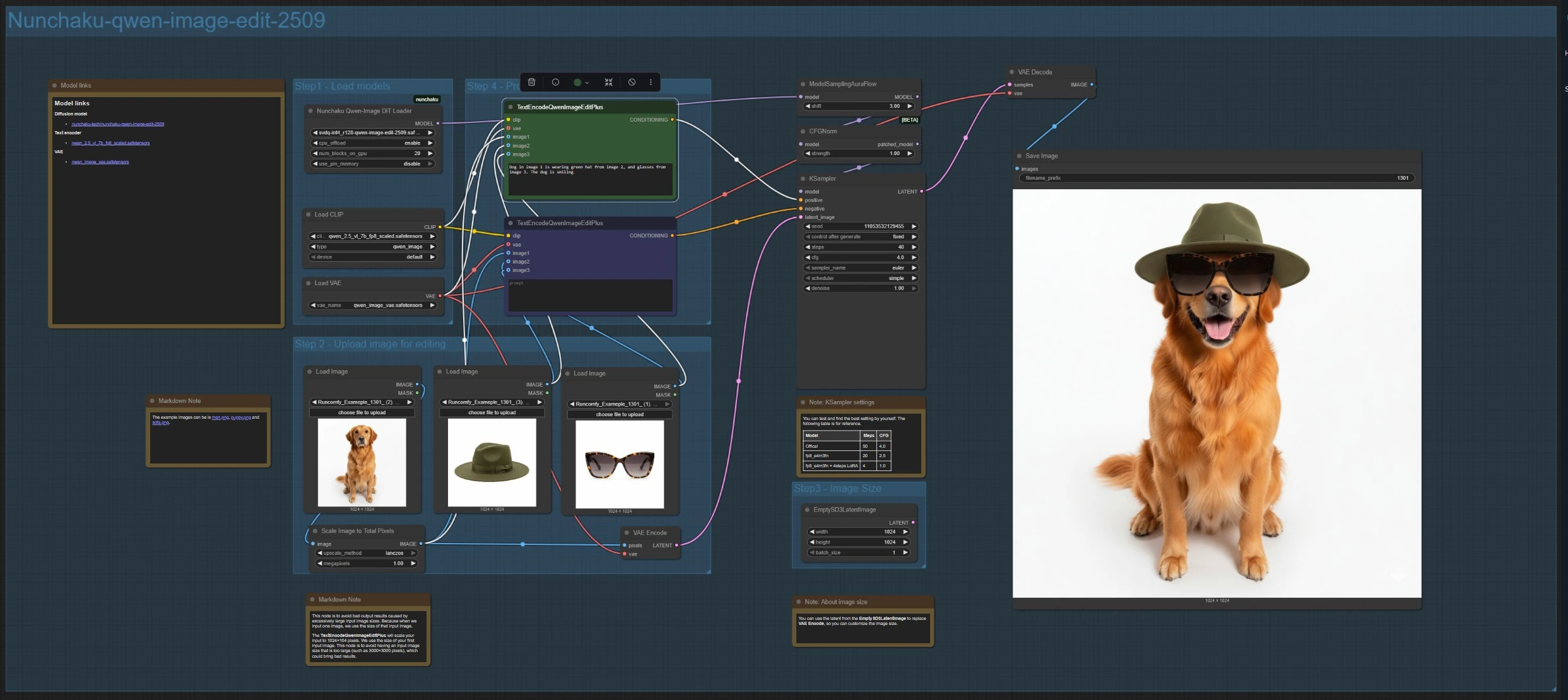
This branch loads the edit model with NunchakuQwenImageDiTLoader (#115), routes it through ModelSamplingAuraFlow (#66) and CFGNorm (#75), then synthesizes with KSampler (#3). Upload up to three images using LoadImage (#78, #106, #108). The main reference is encoded by VAEEncode (#88) to set the canvas, and ImageScaleToTotalPixels (#93) keeps inputs within a stable size range.
Write your instruction in TextEncodeQwenImageEditPlus (#111) and, if needed, place removals or constraints in the paired TextEncodeQwenImageEditPlus (#110). Refer to sources explicitly, for example: “Dog in image 1 wears the green hat from image 2 and the glasses from image 3.” For custom output size, you can replace the encoded latent with EmptySD3LatentImage (#112). Results are decoded by VAEDecode (#8) and saved with SaveImage (#60).
Nunchaku‑qwen‑image‑edit (single‑image refine)#
Choose this when you want targeted clean‑ups, background changes, or style adjustments to one image. The model is loaded by NunchakuQwenImageDiTLoader (#120), adapted by ModelSamplingAuraFlow (#125) and CFGNorm (#123), and sampled by KSampler (#127). Import your photo with LoadImage (#129); it is normalized by ImageScaleToTotalPixels (#130) and encoded by VAEEncode (#131).
Provide your instruction in TextEncodeQwenImageEdit (#121) and optional counter‑guidance in TextEncodeQwenImageEdit (#122) to keep or remove elements. The branch decodes with VAEDecode (#124) and writes files via SaveImage (#128).
Nunchaku‑qwen‑image (text‑to‑image)#
Use this branch to create new images from scratch with the base model. NunchakuQwenImageDiTLoader (#146) feeds ModelSamplingAuraFlow (#138). Enter your positive and negative prompts in CLIPTextEncode (#143) and CLIPTextEncode (#137). Set your canvas with EmptySD3LatentImage (#136), then generate with KSampler (#141), decode using VAEDecode (#142), and save with SaveImage (#147).
Key nodes in Comfyui Nunchaku Qwen Image workflow#
NunchakuQwenImageDiTLoader (#115) Loads the Qwen image weights and variant used by the branch. Select the edit model for photo‑guided edits or the base model for text‑to‑image. When VRAM allows, higher‑precision or higher‑resolution variants can yield more detail; lighter variants prioritize speed.
TextEncodeQwenImageEditPlus (#111) Drives multi‑image edits by parsing your instruction and binding it to up to three references. Keep directives explicit about which image contributes which attribute. Use concise phrasing and avoid conflicting goals to keep edits focused.
TextEncodeQwenImageEditPlus (#110) Acts as the paired negative or constraint encoder for the multi‑image branch. Use it to exclude objects, styles, or artifacts you do not want to appear. This often helps preserve composition while removing UI overlays or unwanted props.
TextEncodeQwenImageEdit (#121) Positive instruction for the single‑image edit branch. Describe the desired outcome, surface qualities, and composition in clear terms. Aim for one to three sentences that specify the scene and changes.
TextEncodeQwenImageEdit (#122) Negative or constraint prompt for the single‑image edit branch. List items or traits to avoid, or describe elements to remove from the source image. This is useful for cleaning stray text, logos, or interface elements.
ImageScaleToTotalPixels (#93) Prevents oversized inputs from destabilizing results by scaling to a target total pixel count. Use it to harmonize disparate source resolutions before compositing. If you notice inconsistent sharpness between sources, bring them closer in effective size here.
ModelSamplingAuraFlow (#66) Applies a DiT/flow‑matching sampling schedule tuned for the Qwen image models. If outputs look dark, mushy, or lack structure, increase the schedule’s shift to stabilize global tone; if they look flat, reduce the shift to chase extra detail.
KSampler (#3) The main sampler where you balance speed, fidelity, and stochastic variety. Adjust steps and the guidance scale for consistency versus creativity, pick a sampler method, and lock a seed when you want exact reproducibility across runs.
CFGNorm (#75) Normalizes classifier‑free guidance to reduce over‑saturation or contrast blow‑outs at higher guidance scales. Leave it in the path as provided; it helps maintain steady color and exposure while you iterate on prompts.
Optional extras#
- For best multi‑image results, choose sources with similar perspective and lighting; the Nunchaku Qwen Image edit model then focuses on content rather than fixing geometry.
- Refer to sources by order (“image 1”, “image 2”, “image 3”) and be explicit about which attributes transfer where.
- When outputs skew dark or blurry, nudge the
ModelSamplingAuraFlowshift upward; when you want extra texture, try a slightly lower shift. - To set a specific resolution, swap the encoded latent for
EmptySD3LatentImagein the branch you are using. - Use negative prompts to remove UI text, watermarks, or unwanted objects before you invest in detailed styling; this keeps the Nunchaku Qwen Image edits clean from the start.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge Nunchaku for the Qwen-Image workflow (ComfyUI-nunchaku) for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- Nunchaku/Qwen-Image
- GitHub: nunchaku-tech/ComfyUI-nunchaku
- Hugging Face: nunchaku-tech/nunchaku-qwen-image
- arXiv: SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
- Docs / Release Notes: Nunchaku Qwen Image Source
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.



