
ChatterBox TTS ComfyUI: マルチモードTTS、音声変換、多言語、ダイアログ合成を1つのグラフで#
ChatterBox TTS ComfyUIは、クリエイターに優しいコンパクトなオーディオワークフローで、単一のキャンバスから複数のモードでスピーチを生成できます: 標準TTS、迅速なドラフトのためのTurbo TTS、多言語ナレーション、リファレンスガイド付き音声クローン、音声変換、スクリプト化された二人のスピーカーダイアログ。このワークフローは、オープンソースのResemble AI Chatterboxプロジェクトを統合した、ComfyUI_Fill-ChatterBoxのFL ChatterBoxノードスイートによって動力を供給されています。
このワークフローを使用してAI音声をプロトタイプ化したり、他の言語にセリフをローカライズしたり、あるパフォーマンスを別の声に変換したり、キャラクターのやり取りをブロックアウトしたりできます。レイアウトは各パスを別々に保持し、結果を並べてオーディションし、どのChatterBox TTS ComfyUIモードがタスクに最適かを迅速に決定できます。
Comfyui ChatterBox TTS ComfyUIワークフローの主要モデル#
- Resemble AI Chatterbox TTSモデル。スクリプトを自然なスピーチに変換するコアニューラルTTSで、音声とスタイルを誘導するためのオプションのリファレンスオーディオを使用できます。Resemble AI Chatterbox
- Resemble AI Chatterbox Turbo TTS。迅速なテイクと反復プロンプトが必要な場合に最適化された低遅延TTSバリアント。Resemble AI Chatterbox
- Resemble AI Chatterbox Multilingual TTS。選択されたスタイルやリファレンス音声を保持しながら複数の言語でテキストをレンダリングするモデル。Resemble AI Chatterbox
- Resemble AI Chatterbox Voice Conversion。タイミングとコンテンツを保持しつつ、ある録音の声色をターゲット音声に変換します。Resemble AI Chatterbox
Comfyui ChatterBox TTS ComfyUIワークフローの使用方法#
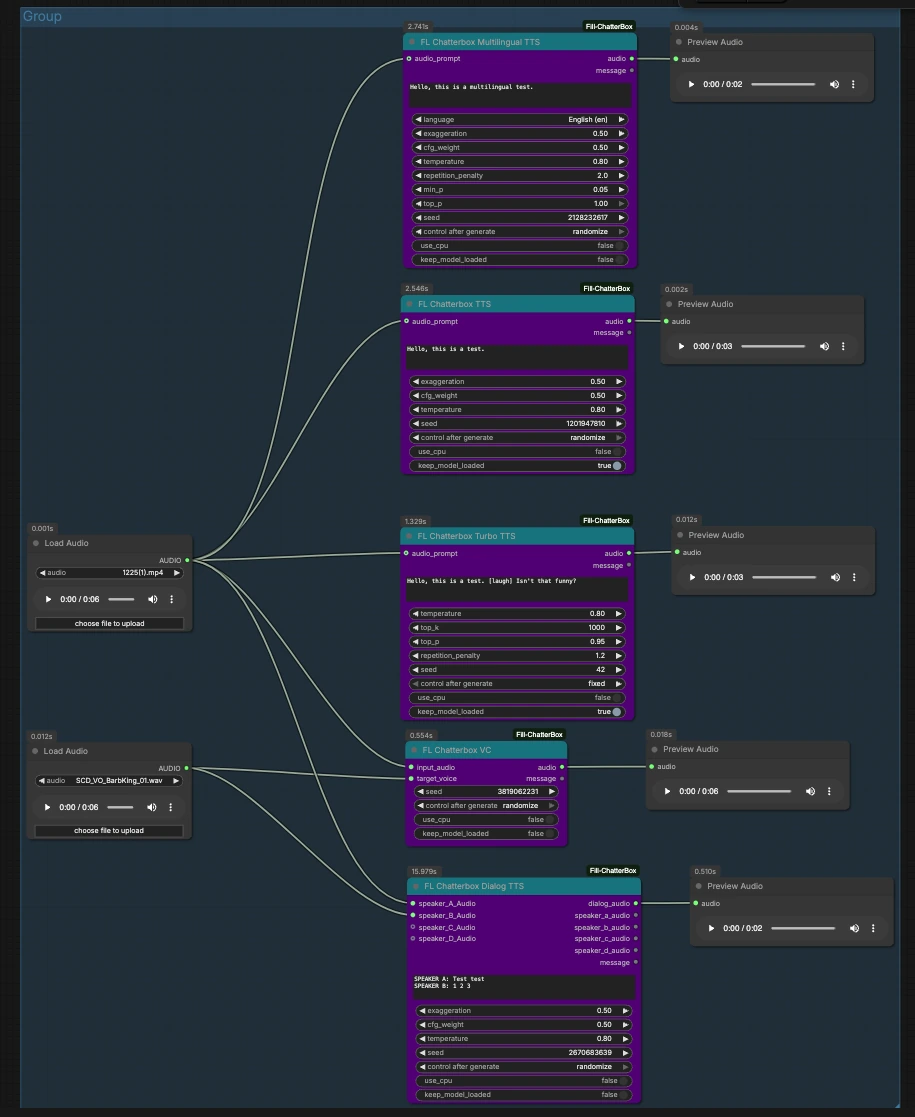
このグラフは、共有オーディオ入力から始まり、各ChatterBoxノードに流れ込み、それぞれの結果をプレビューします。2つの入力クリップをロードまたは置き換え、使用したいパスをトリガーします。
入力: リファレンスとソースオーディオ#
2つのLoadAudioノードが再利用可能な入力を提供します。LoadAudio (#12) はスタイルまたはソースリファレンスとしていくつかのパスにフィードします。LoadAudio (#20) は代替リファレンスまたはターゲット音声として機能します。これらを、話し方のスタイルや模倣したいアイデンティティを表す短くてクリーンなクリップに指すことができます。どちらも一般的なオーディオファイルを受け入れ、ビデオからオーディオを抽出することもできます。
スタイルリファレンス付きの標準TTS#
FL_ChatterboxTTS (#16) はスクリプトからスピーチを生成し、オプションでLoadAudio (#12) からaudio_promptを取って声とデリバリーをキャプチャできます。テキストを入力し、声の類似性を望む場合は適切なリファレンスを接続し、ノードをキューに入れます。付属のPreviewAudioを使用してオーディションします。再現可能なテイクが必要な場合はシードを固定し、バリエーションを探索するためにランダム化します。
迅速な反復のためのTurbo TTS#
FL_ChatterboxTurboTTS (#15) は、迅速なドラフトとインタラクティブ編集のための高速合成に焦点を当てています。トーンやアイデンティティを促したい場合、LoadAudio (#20) からaudio_promptを受け入れます。迅速に動く際はスクリプトを簡潔に保ち、非言語的なキューをテストするために例の"[laugh]"のようなマークアップを試してみてください。出力をプレビューし、より豊かなデリバリーが必要な場合は標準または多言語TTSに切り替えます。
多言語ナレーション#
FL_ChatterboxMultilingualTTS (#25) は選択された言語でスクリプトをレンダリングし、LoadAudio (#12) のaudio_promptからスタイルを借用できます。グラフに示されているように言語ラベル(例えば、English (en))を選び、その言語でテキストを提供します。短いリファレンスクリップは、言語間で一貫したアクセントやペルソナの維持に役立ちます。PreviewAudioで聞いて、明確さのためにフレージングを繰り返します。
音声変換#
FL_ChatterboxVC (#19) は、LoadAudio (#12) からのinput_audioラインの声色をLoadAudio (#20) からのtarget_voiceに変換します。すでにタイミングが完璧な読みがあり、別の声で話されるだけでいい場合に最適です。無音をトリミングし、アーティファクトを減らすためにターゲット音声をクリーンに保ちます。プレビューを使用して、コンテンツが保持されていることを確認しながらアイデンティティを変更します。
二人のスピーカーダイアログ合成#
FL_ChatterboxDialogTTS (#23) は複数行のスクリプトを単一のdialog_audioトラックに変換します。各キャラクターの声を固定するために2つのLoadAudioノードからオプションのspeaker_A_Audioとspeaker_B_Audioを提供します。スクリプトボックスでは、グラフで示されているように、「SPEAKER A:」や「SPEAKER B:」のようなスピーカータグで行の前に接頭辞を付けてターンを割り当てます。入力にリファレンスクリップを追加することで、スピーカーCとDに拡張できます。
プレビューと比較#
各パスは独自のPreviewAudioに広がり、すぐに聞いてモードを比較できます。1つのパスを一度に実行するか、標準、Turbo、多言語、変換、およびダイアログ出力間の違いをオーディションするためにいくつかをキューに入れて実行します。
Comfyui ChatterBox TTS ComfyUIワークフローの主要ノード#
FL_ChatterboxTTS (#16)#
スクリプトとオプションのaudio_promptリファレンスを受け入れる汎用TTS。品質とコントロール性が最も重要な場合に使用します。一貫したアイデンティティのために、テイクごとに同じリファレンスクリップを保持し、正確な再現性が必要な場合はシードを固定します。
FL_ChatterboxTurboTTS (#15)#
行をドラフトし、プロンプトを繰り返し、マークアップのアイデアをプレビューするための高速TTS。音声の誘導のためにaudio_promptも受け入れます。標準パスと比較してプロソディーが薄いと感じた場合は、同じスクリプトとリファレンスを使用してFL_ChatterboxTTSで仕上げます。
FL_ChatterboxMultilingualTTS (#25)#
言語を切り替えながら選択されたペルソナを保持する言語対応TTS。言語ラベルを選び、その言語でテキストを提供します。一致するaudio_promptは、リファレンス音声とアクセントとエネルギーを一致させ続けます。
FL_ChatterboxVC (#19)#
input_audioパフォーマンスをtarget_voiceにマッピングする音声変換。クリーンで代表的なターゲットクリップと、ペースの良いソースリードを使用します。最良の結果を得るには、長い無音をトリミングし、どちらのクリップにも重い背景ノイズを避けてください。
FL_ChatterboxDialogTTS (#23)#
タグ付きの行を単一の会話に解析するマルチスピーカーTTS。使用する予定の各キャラクター入力にリファレンスを割り当て、スクリプトを明確な「SPEAKER X:」タグで構成します。自然なペーシングと後のタイミング編集の容易さのためにターンを適度に短く保ちます。
オプションの追加要素#
- リファレンスクリップを短く、クリーンで表現力豊かに保つ; ルームトーンとノイズは音声の忠実度を低下させます。
- タイミングとデリバリーをリビジョン間で一致させる必要がある場合は固定シードを使用し、代替案を探索するためにランダム化します。
- パスが大きすぎるまたはクリップされているように聞こえる場合は、リファレンスを正規化し、合成前に入力ゲインを減少させます。
- プロンプトの探索にはTurboが最適です; 有望な行を標準または多言語TTSで再実行して最終的な仕上げを行います。
- ダイアログスクリプトは、1行に1つの発話を配置し、スピーカーを一貫してタグ付けすることで保守が容易です。
- キャンバスから直接ファイルをエクスポートしたい場合は、任意のプレビュー後に
SaveAudioノードを追加します。
ChatterBox TTS ComfyUIは、ComfyUI_Fill-ChatterBoxおよびResemble AI Chatterboxに支えられた、コンテキストの切り替えなしで声、言語、ダイアログを試すための柔軟な単一グラフのプレイグラウンドを提供します。
謝辞#
このワークフローは、以下の作品とリソースを実装し、それに基づいて構築されています。ComfyUI_Fill-ChatterBoxのfilliptmと、ChatterboxのResemble AIの貢献とメンテナンスに感謝します。権威のある詳細については、以下のリンクされたオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- filliptm/ComfyUI_Fill-ChatterBox
- GitHub: filliptm/ComfyUI_Fill-ChatterBox
- resemble-ai/chatterbox
- GitHub: resemble-ai/chatterbox
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者とメンテナによって提供されるライセンスと条件に従います。

