
ACE-Step 1.5XL Base text to music: Prompt‑to‑song workflow for ComfyUI#
このワークフローは、ACE-Step 1.5XL Base拡散ファミリーを使用して、自然言語の説明を完成したオーディオに変換します。ベースモデルをACE Step VAEとデュアルQwenテキストエンコーダーと組み合わせて、結果をTTSやスピーチではなく、音楽の領域にしっかりと保ちます。予測可能な構造、テンポ、楽器編成を持つプロンプト駆動のAI音楽を求めるなら、このACE-Step 1.5XL Base text to musicパイプラインは、アイデアからMP3まで迅速に到達するための焦点を絞ったミニマルなセットアップです。
プロデューサー、サウンドデザイナー、クリエーター向けに設計されており、グラフは明確さを強調しています: モデルを選択し、期間を設定し、音楽プロンプトを書いてから生成して保存します。ACE-Step 1.5XL Base text to musicワークフローは、迅速な反復に十分なコンパクトさを保ちながら、詳細なアレンジメント、キー、テンポのために表現力を維持しています。
Key models in Comfyui ACE-Step 1.5XL Base text to music workflow#
- ACE-Step 1.5 XL Base (bf16)拡散モデル。オーディオの潜在をノイズから一貫した音楽フレーズとテクスチャに変換する生成のバックボーン。Model file
- ACE Step 1.5 VAE。潜在空間と波形ドメイン間でエンコード/デコードし、音色とミックスバランスを保持するペアの変分オートエンコーダ。Model file
- Qwen 4B ACE15テキストエンコーダ。プロンプトから豊かな音楽の意味、構造、およびアレンジメントの手がかりをキャプチャするためにACEに適応された大規模なテキストエンコーダ。Model file
- Qwen 0.6B ACE15テキストエンコーダ。プロンプトの理解をしっかりと保ちながら、速度とリソースの効率を優先する軽量のACE適応エンコーダ。Model file
How to use Comfyui ACE-Step 1.5XL Base text to music workflow#
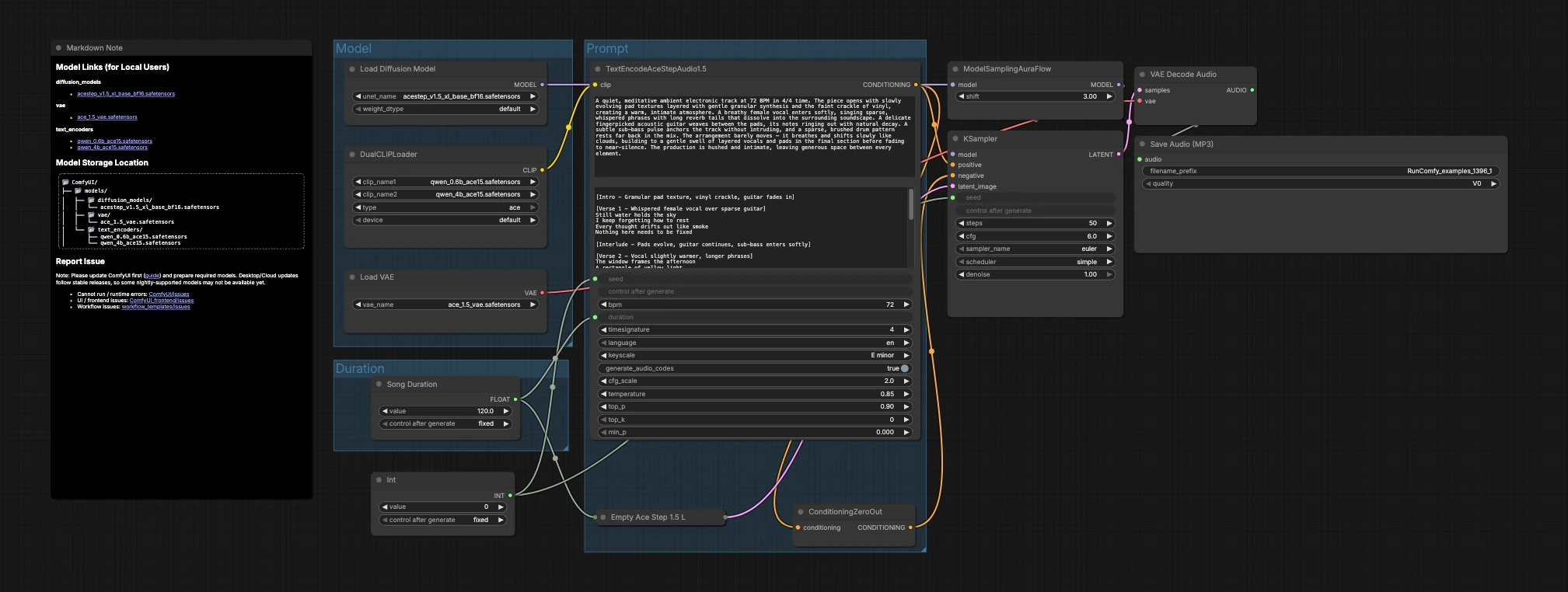
グラフは、生成とエクスポートに流れる3つのグループに整理されています: モデル、期間、およびプロンプト。モデルをロードし、ターゲットの長さを選び、音楽を説明し、その後サンプラーがVAEがオーディオにデコードする潜在を作成します。
Model#
このグループは、コア資産をロードします。UNETLoader (#104)はACE-Step 1.5 XL Base拡散チェックポイントを選択し、VAELoader (#106)は一致するACE Step 1.5 VAEをロードしてデコード品質をトレーニングと一致させます。DualCLIPLoader (#105)は両方のQwen ACE15エンコーダーを導入します; ワークフローはこれらを共同で使用し、豊かなテキストプロンプトが強力な音楽的条件に変換されるようにします。
Duration#
ここでは、作品の長さを決定します。Song Duration (#99)は秒単位でターゲットの長さを設定し、潜在キャンバスとテキストの条件が一致するように前方に供給します。PrimitiveInt (#109)はシードを提供し、再現性のために正確な結果をロックしたり、代替テイクを探索するためにそれを変えることができます。
Prompt#
ここで言語が音楽になります。TextEncodeAceStepAudio1.5 (#94)に説明を書き、テンポ(BPM)、メーター、キー、楽器編成、アレンジメント、ボーカルの存在、ミックスノートなどの有用な音楽メタデータを含めます。ノードはポジティブな条件を発します; ConditioningZeroOut (#47)は中立のネガティブパスを提供し、生成が説明に集中するようにします。EmptyAceStep1.5LatentAudio (#98)は選択した期間の潜在オーディオタイムラインを初期化します。ModelSamplingAuraFlow (#78)はACE-Stepオーディオに適したスケジューラにベースモデルを適応させます。KSampler (#3)はモデル、条件、潜在、シードを組み合わせて音楽の潜在を生成します。VAEDecodeAudio (#18)は潜在を波形に戻し、SaveAudioMP3 (#107)は結果をMP3ファイルに書き込み、共有する準備を整えます。
Key nodes in Comfyui ACE-Step 1.5XL Base text to music workflow#
TextEncodeAceStepAudio1.5 (#94)#
プロンプトを拡散モデルが従うことができる条件に変換します。テンポ、拍子、キー、アレンジメントノート、楽器編成、言語、オプションのボーカル意図などの音楽的詳細を受け入れます。最良の結果を得るには、ジャンル、感触、ミックスの配置について具体的に述べ、構造的な手がかりを簡潔に保ち、モデルが要求された期間を通じて一貫性を保つことができるようにします。
EmptyAceStep1.5LatentAudio (#98)#
作品のための潜在オーディオ「キャンバス」を作成します。その秒数をSong Duration (#99)で設定したものと一致させ、テキストエンコーダで参照して意図しない切り捨てやパディングを避けます。長いキャンバスはより緩やかな発展を招き、短いものはループ、キュー、スティンガーに適しています。
ModelSamplingAuraFlow (#78)#
ACE-Stepオーディオに特化したサンプリング戦略を構成します。安定した結果を得るために提供されたものを使用し、特定のスケジューラの好みがある場合にのみ調整してください。これはKSampler (#3)でのステップ数やガイダンスと相互作用します。
KSampler (#3)#
条件を音楽の潜在に変換するためのノイズ除去を行います。ここでの重要なレバーはサンプラーの種類、ステップ数、シードです。詳細を精緻化するためにステップを増やすと時間がかかる代わりに、シードを固定してプロンプトを比較する際にテキストの変化によるものとランダム性によるものを区別できるようにします。
DualCLIPLoader (#105)#
両方のQwen ACE15テキストエンコーダーをロードします。両方にアクセスできる場合は、4Bエンコーダをアクティブにしてより豊かな言語理解を得ることから始め、より高速な反復やメモリ使用量を抑えたい場合は0.6Bバリアントに切り替えます。プロンプトの微妙な編集を評価する際には、テイク間でエンコーダの選択を一貫させてください。
ConditioningZeroOut (#47)#
中立のネガティブパスを提供します。特定のアーティファクトを抑制したり、スピーチコンテンツから離れたい場合は、これを実際のネガティブプロンプトノードに置き換えることができます。それ以外の場合、ゼロにされたネガティブはACE-Step 1.5XL Base text to musicの生成がポジティブな説明に集中するように保ちます。
Optional extras#
- コンパクトなレシピからプロンプトを開始します: ジャンル + ムード + テンポ + メーター + キー + 楽器編成 + アレンジメント + ミックスノート。
- 明示的な音楽動詞と役割(リード、パッド、ベース、パーカッション)を使用して、モデルがミックス内でスペースを割り当て、スピーチのようなコンテンツを避けます。
- プロンプトのA/Bテストを行うときにシードを固定し、優れたアイデアの代替パフォーマンスを探るためにシードを変更します。
Song Duration(#99)、TextEncodeAceStepAudio1.5(#94)、EmptyAceStep1.5LatentAudio(#98)の間で期間を一致させて予測可能なフレージングを維持します。- 豊かさを求める場合はQwen 4Bを選び、速度を求める場合は0.6Bを選びます; 比較を公正にするために反復中に選択を一定に保ちます。
Acknowledgements#
このワークフローは、以下の作品とリソースを実装し、それに基づいて構築されています。Comfy.orgのaudio_ace_step1_5_xl_baseワークフロー、Comfy-OrgのACE Step 1.5 XL Base拡散モデルとACE Step 1.5 VAE、Qwenチームの0.6Bおよび4B ACE15テキストエンコーダーに感謝します。詳細については、以下のリンクされたオリジナルのドキュメントとリポジトリをご参照ください。
Resources#
- Comfy.org/Workflow source page
- Docs / Release Notes: audio_ace_step1_5_xl_base workflow page
- Comfy-Org/ACE Step 1.5 XL Base diffusion model
- Hugging Face: acestep_v1.5_xl_base_bf16.safetensors
- Comfy-Org/ACE Step 1.5 VAE
- Hugging Face: ace_1.5_vae.safetensors
- Comfy-Org/Qwen 0.6B ACE15 text encoder
- Hugging Face: qwen_0.6b_ace15.safetensors
- Comfy-Org/Qwen 4B ACE15 text encoder
- Hugging Face: qwen_4b_ace15.safetensors
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.
