
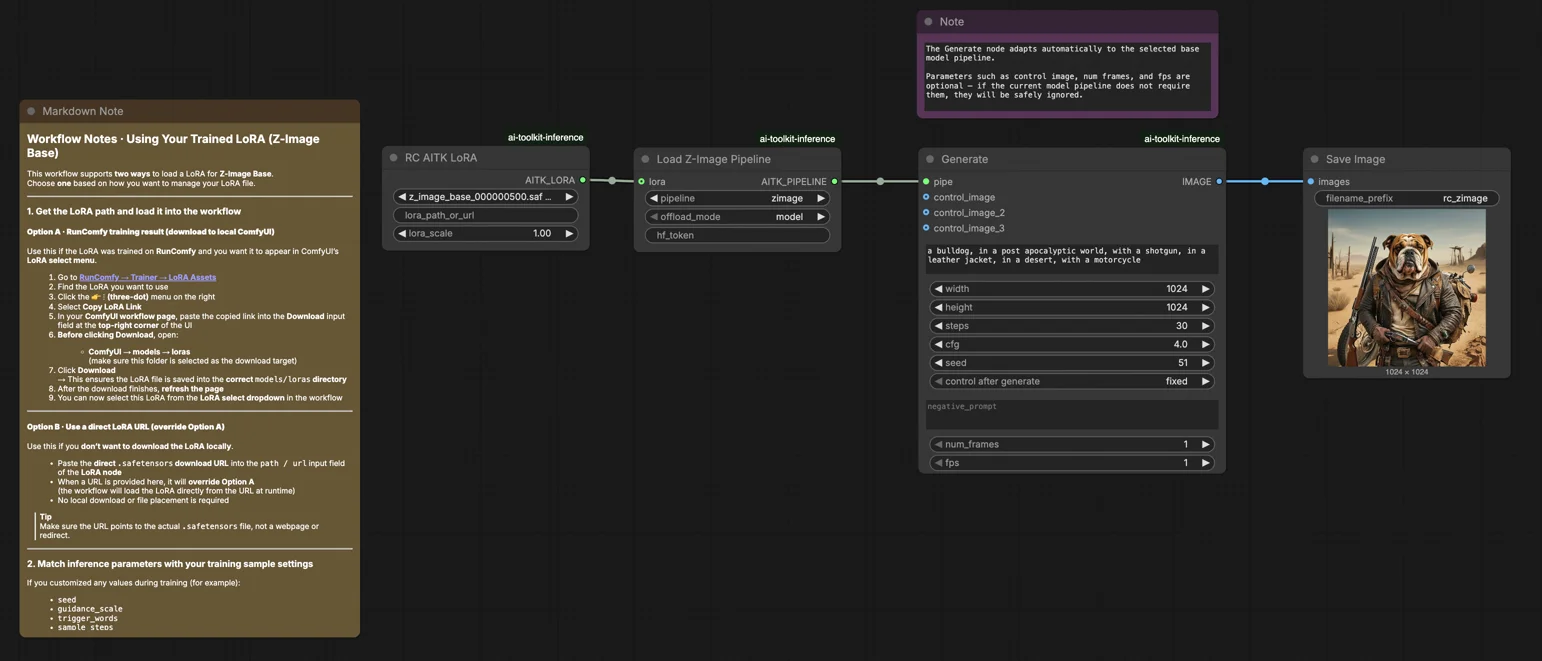
Inferenza Z-Image Base LoRA ComfyUI: generazione allineata al training con LoRA di AI Toolkit#
Questo workflow pronto per la produzione ti consente di eseguire adattatori Z-Image LoRA addestrati con AI Toolkit in ComfyUI con risultati corrispondenti al training. Costruito attorno a RC Z-Image (RCZimage)—un nodo personalizzato a livello di pipeline open-source da RunComfy (source)—il workflow avvolge il pipeline di inferenza Tongyi-MAI/Z-Image piuttosto che fare affidamento su un grafo di campionamento generico. Il tuo adattatore viene iniettato tramite lora_path e lora_scale all'interno di quel pipeline, mantenendo l'applicazione LoRA coerente con il modo in cui AI Toolkit produce le anteprime di training.
Perché l'inferenza Z-Image Base LoRA ComfyUI sembra spesso diversa in ComfyUI#
Le anteprime di training di AI Toolkit sono renderizzate da un pipeline di inferenza specifico del modello—la configurazione del scheduler, il flusso di condizionamento e l'iniezione di LoRA avvengono tutti all'interno di quel pipeline. Un grafo di campionamento standard di ComfyUI assembla questi pezzi in modo diverso, quindi anche prompt identici, seed e conteggi di passaggi possono produrre output visibilmente diversi. La discrepanza non è causata da un singolo parametro errato; è una dissonanza a livello di pipeline. RCZimage recupera il comportamento allineato al training avvolgendo direttamente il pipeline Z-Image e applicando la tua LoRA all'interno di esso. Riferimento di implementazione: `src/pipelines/z_image.py`.
Come usare il workflow di inferenza Z-Image Base LoRA ComfyUI#
Passo 1: Ottieni il percorso LoRA e caricalo nel workflow (2 opzioni)#
Opzione A — Risultato del training RunComfy → scarica su ComfyUI locale:
- Vai a Trainer → LoRA Assets
- Trova il LoRA che vuoi usare
- Clicca sul menu ⋮ (tre puntini) a destra → seleziona Copia link LoRA
- Nella pagina workflow di ComfyUI, incolla il link copiato nel campo di input Download nell'angolo in alto a destra dell'interfaccia
- Prima di cliccare su Download, assicurati che la cartella di destinazione sia impostata su ComfyUI → models → loras (questa cartella deve essere selezionata come destinazione del download)
- Clicca su Download — questo salva il file LoRA nella directory
models/lorascorretta - Dopo il completamento del download, aggiorna la pagina
- Il LoRA ora appare nel menu a discesa di selezione LoRA nel workflow — selezionalo

Opzione B — URL diretto LoRA (sostituisce Opzione A):
- Incolla l'URL diretto di download
.safetensorsnel campo di inputpath / urldel nodo LoRA - Quando un URL viene fornito qui, sostituisce l'Opzione A — il workflow carica il LoRA direttamente dall'URL durante l'esecuzione
- Non è richiesto alcun download o posizionamento del file locale
Suggerimento: l'URL deve puntare al file .safetensors effettivo, non a una pagina web o reindirizzamento.

Passo 2: Abbina i parametri di inferenza alle impostazioni del tuo campione di training#
Imposta lora_scale sul nodo LoRA — inizia alla stessa forza che hai usato durante le anteprime di training, quindi regola se necessario.
I restanti parametri si trovano sul nodo Generate:
prompt— il tuo prompt di testo; includi qualsiasi parola chiave che hai usato durante il trainingnegative_prompt— lascia vuoto a meno che il tuo YAML di training non includa negativiwidth/height— risoluzione dell'output; abbina la dimensione della tua anteprima per un confronto diretto (multipli di 32)sample_steps— numero di passaggi di inferenza; Z-Image base predefinito è 30 (usa lo stesso conteggio dalla tua configurazione di anteprima)guidance_scale— forza CFG; il predefinito è 4.0 (inizia con il valore della tua anteprima di training)seed— fissa un seed per riprodurre output specifici; cambia per esplorare variazioniseed_mode— sceglifixedorandomizehf_token— token Hugging Face; richiesto solo se il modello di base o il repo di LoRA è protetto/privato
Suggerimento per l'allineamento del training: se hai personalizzato qualsiasi valore di campionamento durante il training, copia quegli stessi valori nei campi corrispondenti. Se hai addestrato su RunComfy, apri Trainer → LoRA Assets → Config per vedere il YAML risolto e copia le impostazioni di anteprima/campione nel nodo.

Passo 3: Esegui l'inferenza Z-Image Base LoRA ComfyUI#
Clicca Queue/Run — il nodo SaveImage scrive automaticamente i risultati nella tua cartella di output ComfyUI.
Checklist rapida:
- ✅ LoRA è stato: scaricato in
ComfyUI/models/loras(Opzione A), o caricato tramite un URL diretto.safetensors(Opzione B) - ✅ Pagina aggiornata dopo il download locale (solo Opzione A)
- ✅ I parametri di inferenza corrispondono alla configurazione del
sampledi training (se personalizzati)
Se tutto quanto sopra è corretto, i risultati dell'inferenza qui dovrebbero corrispondere strettamente alle tue anteprime di training.
Risoluzione dei problemi di inferenza Z-Image Base LoRA ComfyUI#
La maggior parte delle discrepanze “anteprima di training vs inferenza ComfyUI” per Z-Image Base (Tongyi-MAI/Z-Image) deriva da differenze a livello di pipeline (come il modello viene caricato, quali predefiniti/scheduler vengono utilizzati, e dove/come viene iniettato il LoRA). Per LoRA Z-Image Base addestrati con AI Toolkit, il modo più affidabile per tornare a un comportamento allineato al training in ComfyUI è eseguire la generazione tramite RCZimage (il wrapper di pipeline di RunComfy) e iniettare il LoRA tramite lora_path / lora_scale all'interno di quel pipeline.
(1) Quando si utilizza Z-Image LoRA con ComfyUI, appare il messaggio "lora key not loaded".#
Perché succede Questo di solito significa che il tuo LoRA è stato addestrato con un layout di moduli/chiavi diverso da quello che il tuo attuale loader Z-Image di ComfyUI si aspetta. Con Z-Image, lo “stesso nome di modello” può ancora coinvolgere convenzioni di chiavi diverse (ad esempio, stile originale/diffusers vs denominazione specifica di Comfy), e questo è sufficiente per innescare “chiave non caricata”.
Come risolvere (consigliato)
- Esegui l'inferenza tramite RCZimage (il wrapper di pipeline del workflow) e carica il tuo adattatore tramite
lora_pathsul percorso RCAITKLoRA / RCZimage, invece di iniettarlo tramite un loader LoRA Z-Image generico separato. - Mantieni il workflow coerente nel formato: Z-Image Base LoRA addestrato con AI Toolkit → inferisci con il pipeline RCZimage allineato ad AI Toolkit, così non dipendi dal rimappamento delle chiavi/converter lato ComfyUI.
(2) Si sono verificati errori durante la fase VAE quando si utilizza il loader ZIMAGE LORA (solo modello).#
Perché succede Alcuni utenti riportano che l'aggiunta del loader ZIMAGE LoRA (solo modello) può causare rallentamenti significativi e successivi fallimenti nella fase finale di decodifica VAE, anche quando il workflow Z-Image di default funziona bene senza il loader.
Come risolvere (confermato dall'utente)
- Rimuovi il loader ZIMAGE LORA (solo modello) e riesegui il percorso del workflow Z-Image di default.
- In questo workflow RunComfy, l'equivalente “baseline sicuro” è: usa RCZimage +
lora_path/lora_scalecosì l'applicazione LoRA rimane all'interno del pipeline, evitando il percorso problematico “loader LoRA solo modello”.
(3) Il formato Comfy Z-Image non corrisponde al codice originale#
Perché succede Z-Image in ComfyUI può coinvolgere un formato specifico di Comfy (comprese differenze di denominazione delle chiavi rispetto alle convenzioni “originali”). Se il tuo LoRA è stato addestrato con AI Toolkit su una convenzione di denominazione/layout, e provi ad applicarlo in ComfyUI aspettandoti un'altra, vedrai un'applicazione parziale/fallita e un comportamento “funziona ma sembra sbagliato”.
Come risolvere (consigliato)
- Non mescolare formati quando stai cercando di abbinare le anteprime di training. Usa RCZimage così l'inferenza esegue il pipeline Z-Image nella stessa “famiglia” che usano le anteprime di AI Toolkit, e inietta il LoRA all'interno tramite
lora_path/lora_scale. - Se devi usare uno stack Z-Image in formato Comfy, assicurati che il tuo LoRA sia nel formato atteso da quello stack (altrimenti le chiavi non si allineeranno).
(4) Z-Image oom usando lora#
Perché succede Z-Image + LoRA può spingere la VRAM oltre il limite a seconda della precisione/quantizzazione, risoluzione, e percorso del loader. Alcuni report menzionano OOM su configurazioni VRAM da 12GB quando si combina LoRA con modalità a precisione inferiore.
Come risolvere (baseline sicuro)
- Valida prima il tuo baseline: esegui Z-Image Base senza LoRA alla tua risoluzione target.
- Quindi aggiungi il LoRA tramite RCZimage (
lora_path/lora_scale) e mantieni i confronti controllati (stessiwidth/height,sample_steps,guidance_scale,seed). - Se ancora incontri OOM, riduci prima la risoluzione (Z-Image è sensibile al numero di pixel), quindi considera di ridurre
sample_steps, e solo allora reintroduci impostazioni più elevate dopo aver confermato la stabilità. In RunComfy, puoi anche passare a una macchina più grande.
Esegui ora l'inferenza Z-Image Base LoRA ComfyUI#
Apri il workflow Z-Image Base LoRA ComfyUI Inference di RunComfy, imposta il tuo lora_path, e lascia che RCZimage mantenga l'output di ComfyUI allineato con le tue anteprime di training di AI Toolkit.
