
Gemma 4 Text Generation ComfyUI workflow : texte multimodal avec contexte image, vidéo et audio#
Ce workflow Gemma 4 Text Generation ComfyUI est un modèle compact, prêt pour RunComfy, qui génère du texte de haute qualité tout en comprenant les images et l'audio, avec un exemple vidéo inclus. Il est conçu pour des itérations rapides sur des invites multimodales, des résumés de produits, des analyses de contenu et des prototypes d'assistants légers dans ComfyUI.
Le graphique utilise les nœuds natifs TextGenerate et CLIPLoader de ComfyUI pour exécuter Gemma 4 E4B avec des entrées d'image, audio et vidéo optionnelles. Vous pouvez le garder simple pour la génération de texte pur ou ajouter des médias pour guider le raisonnement du modèle et produire des sorties plus riches.
Modèles clés dans le workflow Gemma 4 Text Generation ComfyUI#
- Modèle multimodal instructif Gemma 4 E4B. Fournit une génération de texte avec compréhension visuelle et audio pour des réponses, résumés et analyses concis. Les ressources du modèle pour ComfyUI sont organisées sous le pack communautaire Comfy-Org/gemma-4.
- Encodeur de texte Gemma 4 E4B (échelle FP8). Le workflow charge les poids d'encodeur empaquetés
gemma4_e4b_it_fp8_scaled.safetensorsqui soutiennent les entrées linguistiques et multimodales du nœudTextGenerate. Lien direct de fichier pour les utilisateurs locaux : `text_encoders/gemma4_e4b_it_fp8_scaled.safetensors`.
Comment utiliser le workflow Gemma 4 Text Generation ComfyUI#
Logique générale : le workflow charge l'encodeur Gemma 4, accepte les médias optionnels, puis utilise TextGenerate pour produire une réponse qui est rendue dans un aperçu. Vous pouvez l'exécuter en mode texte seulement, ajouter une image et de l'audio, ou l'étendre à la vidéo en connectant le groupe d'exemple.
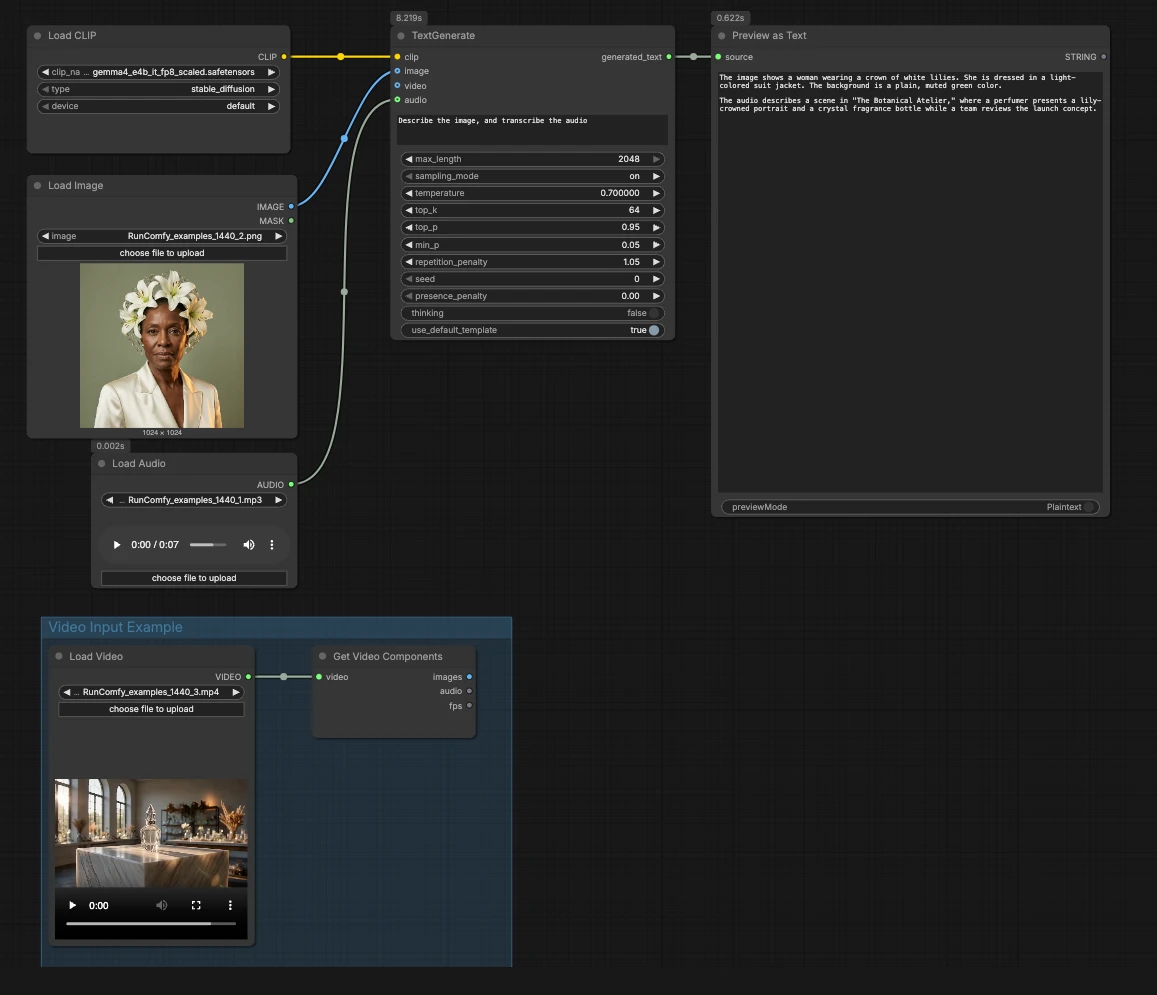
CLIPLoader(#3) Charge l'encodeur de texte Gemma 4 E4B requis par le générateur. Lors de l'exécution locale, sélectionnezgemma4_e4b_it_fp8_scaled.safetensorsafin que le modèle linguistique ait le bon tokenizer et encodeur multimodal. Dans les environnements gérés, le fichier correct est généralement présélectionné. Vous n'avez pas besoin d'ajuster quoi que ce soit ici une fois que les poids choisis sont visibles.- Entrée d'image avec
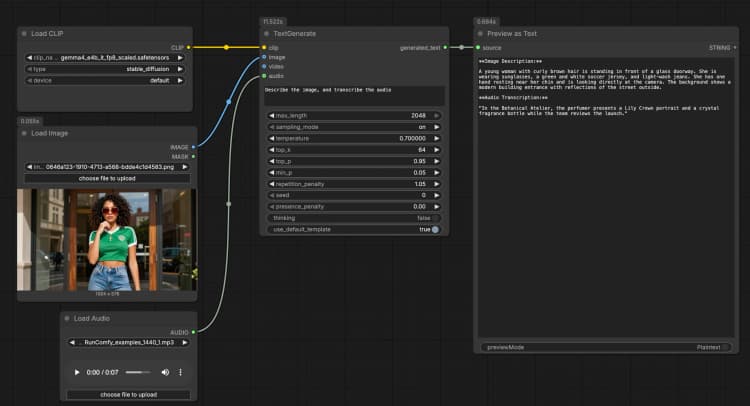
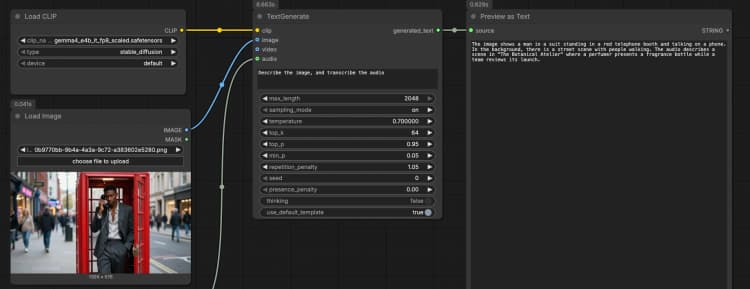
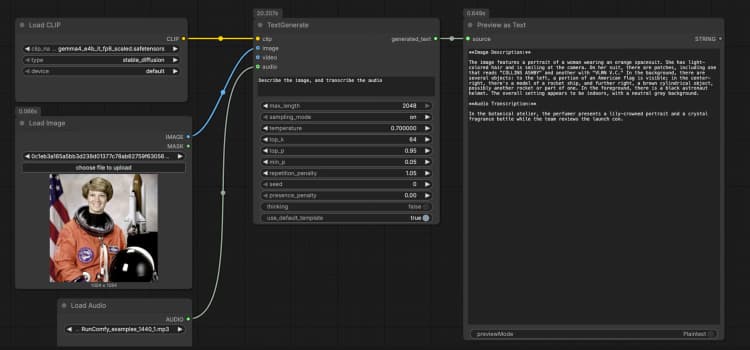
LoadImage(#2) Fournit une image de référence unique que le modèle peut décrire, OCR ou analyser dans le cadre de l'invite. Remplacez le fichier exemple par votre propre capture d'écran, graphique, document ou photo de produit. L'image est directement passée àTextGenerate, qui conditionne la réponse sur le contenu visuel. Si vous souhaitez un comportement uniquement textuel, laissez ce nœud déconnecté. - Entrée audio avec
LoadAudio(#5) Ajoute un extrait audio pour la transcription ou le raisonnement conscient de l'audio. Remplacez le fichier d'exemple par une note vocale, un extrait de réunion ou un enregistrement d'avis. Le flux audio est alimenté àTextGenerateafin que vous puissiez demander au modèle de le transcrire ou de le résumer en même temps que l'image. Pour les tâches uniquement textuelles, gardez cette entrée vide. - Exemple de groupe d'entrée vidéo Le groupe "Exemple d'entrée vidéo" montre comment intégrer la vidéo dans le même flux en utilisant
LoadVideo(#6) etGetVideoComponents(#7).GetVideoComponentsexpose des images représentatives et la bande sonore pour que vous puissiez analyser les scènes, diapositives ou texte à l'écran. Pour activer la compréhension vidéo, connectez la sortieimagesà l'entréeimagedeTextGenerateet la sortieaudioà son entréeaudio. Cela permet au workflow Gemma 4 Text Generation ComfyUI de raisonner sur les images et le discours d'un clip. - Génération de texte avec
TextGenerate(#1) C'est le nœud central qui accepte votre instruction plus tout média attaché et renvoie le texte généré. Fournissez une invite claire comme "Décrivez l'image et transcrivez l'audio, puis écrivez un résumé en 2 phrases." Le nœud fusionne automatiquement le contexte visuel et audio, vous permettant d'écrire des instructions naturelles sans espaces réservés. Vous pouvez garder les invites conversationnelles ou orientées tâche selon votre cas d'utilisation. - Visualisation du résultat avec
PreviewAny(#4) Affiche le texte généré pour que vous puissiez le copier dans vos notes ou outils en aval. Relancez après avoir modifié l'invite ou échangé des médias pour comparer rapidement les sorties. Utilisez cet aperçu pour valider combien chaque modalité influence la réponse.
Nœuds clés dans le workflow Gemma 4 Text Generation ComfyUI#
TextGenerate(#1) Pilote la sortie finale et est l'endroit où la plupart des réglages résident. Ajustez la longueur de la réponse et la sensation exploratoire en modifiant le nombre maximum de tokens et la température d'échantillonnage. Activez le mode de raisonnement optionnel si vous souhaitez une réflexion plus étape par étape avant la réponse. Pour les détails de mise en œuvre, consultez le code source du nœud de génération de texte ComfyUI ici.CLIPLoader(#3) Sélectionne et charge le package d'encodeur Gemma 4 E4B nécessaire pour la compréhension textuelle et multimodale. Si vous maintenez les modèles localement, placez le fichier sous : ComfyUI/models/text_encoders/gemma4_e4b_it_fp8_scaled.safetensors Après la sélection, vous n'avez généralement pas besoin de revisiter ce nœud sauf si vous changez de variantes de modèle.GetVideoComponents(#7) Utile lorsque vous voulez que le modèle prenne en compte la vidéo. Il expose les images et l'audio pour que vous puissiez conditionnerTextGeneratesur les deux. Si votre clip est long, choisissez un ensemble plus petit d'images pour un délai plus rapide ; si vous avez besoin de détails plus fins, augmentez l'échantillonnage des images au détriment de la vitesse.
Extras optionnels#
- Commencez par des instructions explicites comme "Considérez l'image et l'audio attachés" pour rendre l'ancrage multimodal évident.
- Pour les avis sur les produits, demandez des avantages, inconvénients et un verdict en une phrase pour garder les sorties structurées.
- Si votre tâche est purement textuelle, déconnectez l'image et l'audio pour des exécutions plus rapides.
- Pour expérimenter en lot, dupliquez le nœud
TextGenerateavec différentes invites et comparez les aperçus côte à côte. - Les fichiers de modèle et variantes pour Gemma 4 sont organisés dans le pack communautaire ; explorez les ressources disponibles ici : Comfy-Org/gemma-4.
Remerciements#
Ce workflow implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Comfy-Org pour le package de modèle Gemma 4 ComfyUI et l'encodeur de texte E4B, Comfy-Org (mainteneurs de ComfyUI) pour le nœud TextGenerate intégré, et Comfy.org pour le tutoriel officiel Gemma 4 et le blog de sortie pour leurs contributions et maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation et aux dépôts originaux liés ci-dessous.
Ressources#
- ComfyUI Docs/Gemma 4 ComfyUI workflow example
- GitHub: Comfy-Org/ComfyUI
- Hugging Face: Comfy-Org/gemma-4
- Docs / Notes de version: Gemma 4 ComfyUI workflow example
- Blog ComfyUI/Nouveaux modèles open-source maintenant dans ComfyUI : VOID, BiRefNet & Gemma 4
- GitHub: Comfy-Org/workflow_templates
- Hugging Face: Comfy-Org/gemma-4
- Docs / Notes de version: Nouveaux modèles open-source maintenant dans ComfyUI : VOID, BiRefNet & Gemma 4
- Comfy-Org/gemma-4
- Hugging Face: Comfy-Org/gemma-4
- Encodeur de texte Comfy-Org/gemma-4 E4B
- Hugging Face: Comfy-Org/gemma-4: gemma4_e4b_it_fp8_scaled.safetensors
- Nœud TextGenerate Comfy-Org/ComfyUI
Note : L'utilisation des modèles, jeux de données et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.