
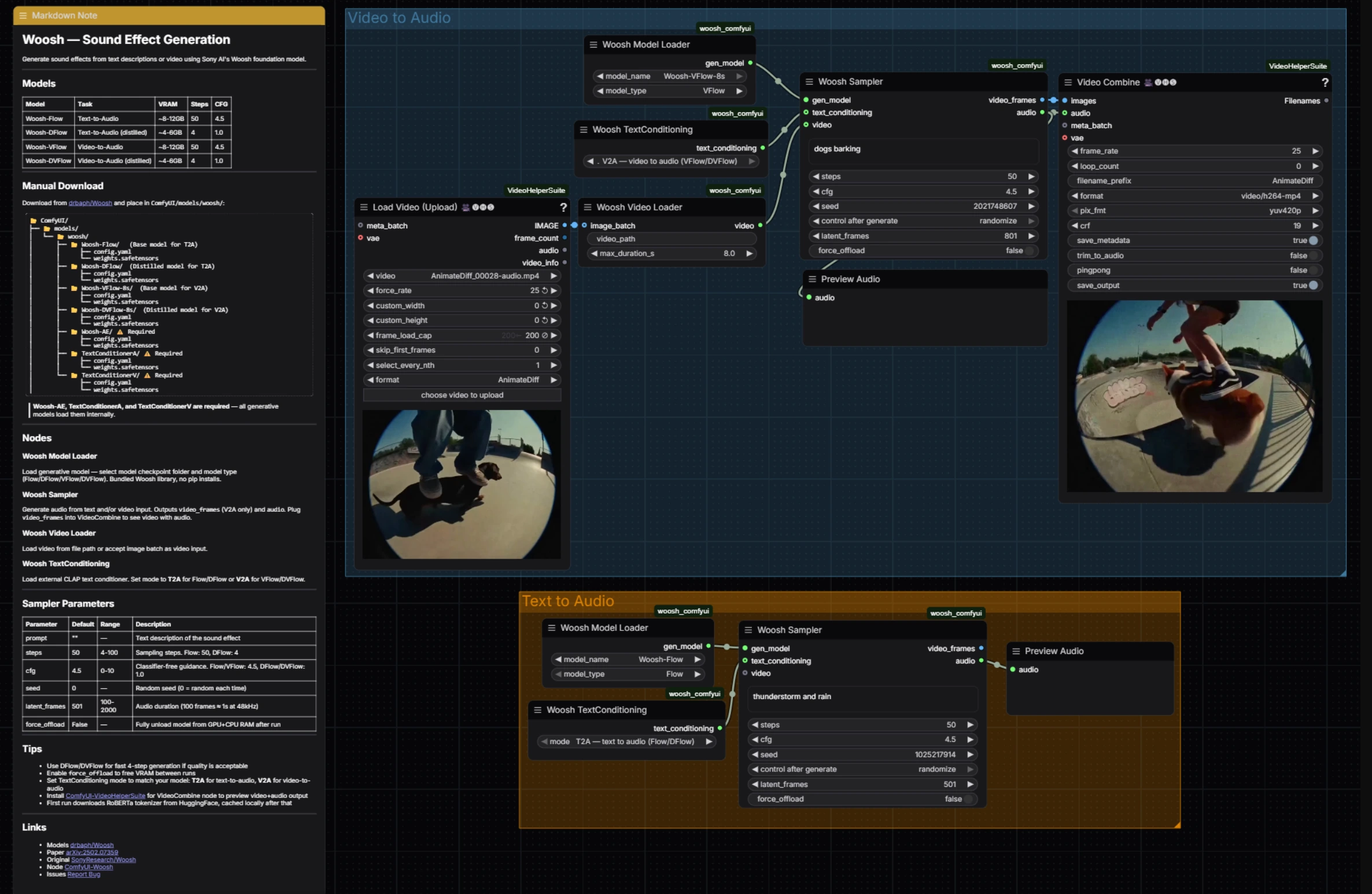
Generación de Efectos de Sonido Woosh: audio condicionado por indicaciones y video en ComfyUI#
La Generación de Efectos de Sonido Woosh es un flujo de trabajo de ComfyUI que convierte indicaciones de texto o clips de video en efectos de sonido pulidos utilizando el modelo base Woosh de Sony Research. Está diseñado para creadores que necesitan un lugar para Foley basado en indicaciones, diseño de sonido ajustado al video, y cambios rápidos entre variantes destiladas de alta calidad y rápidas.
El flujo de trabajo expone ambas familias de modelos Woosh: Flow/DFlow para texto a audio y VFlow/DVFlow para video a audio. Un sampler compartido impulsa la generación en ambos caminos, produciendo audio para vista previa inmediata y, en el camino de video, vistas previas de fotogramas que se recombinan para dailies rápidos. Bajo el capó, se basa en los nodos oficiales de ComfyUI Woosh y VideoHelperSuite para una entrada/salida de video sin problemas, por lo que la Generación de Efectos de Sonido Woosh se mantiene rápida y sencilla mientras sigue siendo flexible. Referencias: SonyResearch/Woosh, drbaph/Woosh en Hugging Face, paper, ComfyUI-Woosh, ComfyUI-VideoHelperSuite.
Modelos clave en el flujo de trabajo de Generación de Efectos de Sonido Woosh en Comfyui#
- Sony Research Woosh — Flow: generador principal de texto a audio utilizado para Foley y ambientes de alta fidelidad, entrenado con objetivos de coincidencia de flujo. Ver SonyResearch/Woosh y el paper.
- Sony Research Woosh — DFlow: modelo destilado de texto a audio optimizado para velocidad con muchos menos pasos de muestreo, ideal para iteraciones rápidas. Los pesos están disponibles a través de drbaph/Woosh.
- Sony Research Woosh — VFlow‑8s: generador condicionado por video que sincroniza inicios de audio y texturas con indicaciones de movimiento visual para video a audio. Ver SonyResearch/Woosh.
- Sony Research Woosh — DVFlow‑8s: modelo destilado de video a audio para flujos de trabajo ligeros en tiempo real y vistas previas rápidas. Pesos: drbaph/Woosh.
- Woosh‑AE: el autoencoder de audio utilizado para reconstruir formas de onda a partir de latentes del modelo; requerido por todos los generadores. Pesos: drbaph/Woosh.
- TextConditionerA y TextConditionerV: módulos de acondicionamiento de texto que incrustan indicaciones adecuadamente para ejecuciones de texto a audio o de video a audio. Los detalles y el uso están documentados en ComfyUI-Woosh y el paper.
Cómo usar el flujo de trabajo de Generación de Efectos de Sonido Woosh de Comfyui#
Este flujo de trabajo tiene dos grupos paralelos que puedes ejecutar de forma independiente: Video a Audio para diseño de sonido ajustado al visual y Texto a Audio para Foley basado en indicaciones puras. Ambos convergen en la misma lógica de muestreo y vista previa rápida de audio, haciendo que la Generación de Efectos de Sonido Woosh sea consistente de operar independientemente de la entrada.
Video a Audio#
El grupo Video a Audio carga un clip, alinea fotogramas y acondicionamiento, luego genera sonido sincronizado. Comienza alimentando tu clip en VHS_LoadVideo (#34); extrae fotogramas a la tasa elegida para que los nodos posteriores vean una secuencia limpia y delimitada. Esos fotogramas se empaquetan como una secuencia de acondicionamiento de video por WooshLoadVideo (#37), que estandariza la duración para que el generador reciba ventanas constantes.
Elige un modelo condicionado por video en WooshLoadFlow (#7), típicamente VFlow para fidelidad o DVFlow para velocidad. Proporciona una breve indicación descriptiva en el sampler (para estilo o intención) y configura WooshTextEncode (#19) a V2A para que el texto se incruste con la rama de acondicionamiento correcta. Ejecuta WooshSample (#38) para sintetizar audio; produce tanto audio para PreviewAudio (#9) como video_frames que fluyen en VHS_VideoCombine (#33) para una vista previa rápida ensamblada, manteniendo la Generación de Efectos de Sonido Woosh ajustada para revisión editorial.
Texto a Audio#
El grupo Texto a Audio se centra en la generación limpia impulsada por indicaciones. Selecciona un modelo en WooshLoadFlow (#40), usando Flow cuando quieras máxima calidad y DFlow cuando necesites pasadas muy rápidas e iterativas. Configura WooshTextEncode (#41) a T2A para que tu indicación se incruste para generación solo de texto. Ingresa tu descripción en WooshSample (#39) y ejecuta; el resultado se envía a PreviewAudio (#43) para escucha instantánea. Este camino mantiene la Generación de Efectos de Sonido Woosh ligera cuando estás creando bibliotecas o superponiendo efectos sin imagen.
Nodos clave en el flujo de trabajo de Generación de Efectos de Sonido Woosh de Comfyui#
WooshSample (#38)#
Sampler central para generación condicionada por video. Ajusta la indicación para dirigir estilo e inicios, luego ajusta steps para el equilibrio calidad-velocidad (usa menos pasos al ejecutar DVFlow). cfg controla la adherencia a la indicación y latent_frames determina la longitud de salida para que coincida o desplace intencionalmente el clip. Configura seed para reproducir tomas y habilita force_offload cuando necesites liberar memoria entre ejecuciones largas. La implementación y comportamiento del nodo siguen el oficial ComfyUI-Woosh.
WooshSample (#39)#
Sampler para texto a audio con los mismos controles y comportamiento, menos la secuencia de video. Para ideación rápida elige DFlow y bajos steps; para finales cambia a Flow y eleva steps para detalle. Mantén cfg moderado para texturas naturales, aumenta para resultados estilizados y bloqueados por indicación. Usa latent_frames para establecer la duración precisamente al construir activos para bibliotecas o líneas de tiempo DAW.
WooshLoadFlow (#7)#
Selector de modelo para el camino de Video a Audio. Elige VFlow para la mayor fidelidad de alineación al movimiento, o DVFlow cuando necesites vistas previas casi en tiempo real. Asegúrate de que WooshTextEncode esté configurado a V2A para que las incrustaciones coincidan con la familia de modelos elegida. Ver drbaph/Woosh para variantes de modelo.
WooshLoadFlow (#40)#
Selector de modelo para el camino de Texto a Audio. Elige Flow para un rico detalle y variedad de texturas más amplia, o DFlow para iteración rápida con pasos mínimos. Combínalo con WooshTextEncode en modo T2A para evitar desajustes de acondicionamiento. El comportamiento del nodo y las opciones siguen el oficial ComfyUI-Woosh.
VHS_VideoCombine (#33)#
Utilidad para ensamblar el audio generado con la vista previa de video_frames del sampler para producir un clip revisable. Úsalo para verificar la sincronización, evaluar transiciones y compartir dailies sin salir de ComfyUI. Parte de ComfyUI-VideoHelperSuite.
Extras opcionales#
- Usa DVFlow/DFlow para pasadas de exploración rápidas, luego cambia a VFlow/Flow para finales cuando la Generación de Efectos de Sonido Woosh deba brillar.
- Mantén tu clip de entrada dentro de la ventana del modelo seleccionado (por ejemplo, las variantes de VFlow de 8 segundos) y procesa escenas más largas en fragmentos superpuestos que puedas fundir.
- Mantén una tasa de fotogramas consistente desde
VHS_LoadVideohastaVHS_VideoCombinepara reducir la deriva entre audio e imagen. - Para indicaciones, combina palabras de acción con contexto acústico y de textura (por ejemplo, "rápido whoosh metálico en una escalera de concreto") para obtener resultados predecibles.
- Activa
force_offloaden el sampler entre ejecuciones pesadas si la memoria GPU es limitada.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Sony Research por Woosh (proyecto y artículo), Saganaki22 por ComfyUI-Woosh (nodo de ComfyUI), y Kosinkadink por ComfyUI-VideoHelperSuite por sus contribuciones y mantenimiento. Para detalles autorizados, consulte la documentación original y los repositorios enlazados a continuación.
Recursos#
- Saganaki22/ComfyUI-Woosh
- GitHub: Saganaki22/ComfyUI-Woosh
- drbaph/Woosh
- Hugging Face: drbaph/Woosh
- SonyResearch/Woosh
- GitHub: SonyResearch/Woosh
- Sony Research/Woosh (paper)
- arXiv: 2502.07359
- Kosinkadink/ComfyUI-VideoHelperSuite
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.